
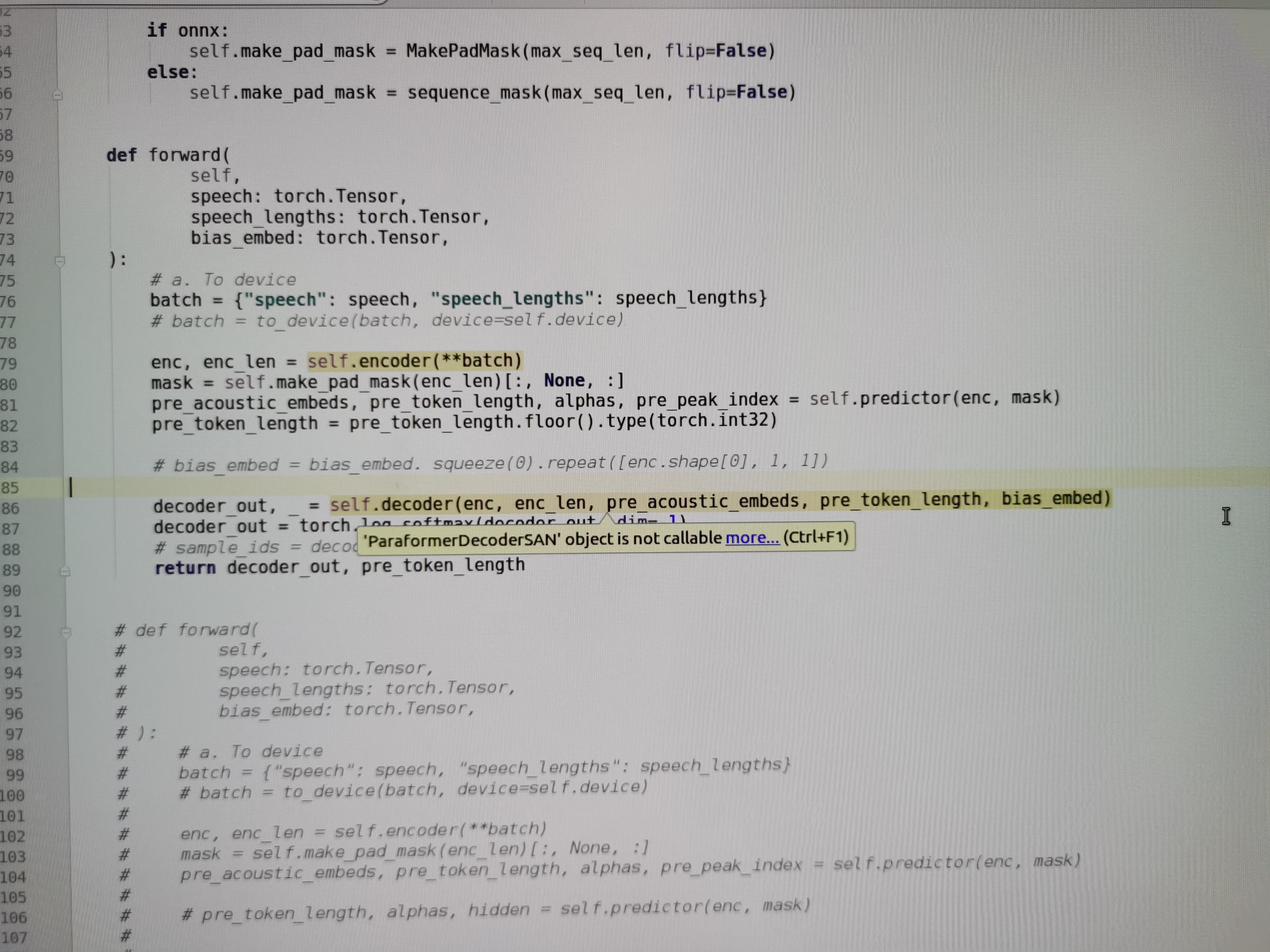
我当前需要将paraformer-large-contextual offline模型转换为RKNN模型部署到终端,遇到转换失败问题,需要对模型进行拆分,想参考online模型的拆分方式,我看到online模型拆分后在decoder部分需要进行缓存处理,想确认一下modelscope-funasr的offline模型可以不进行缓存处理吗?由于offline模型还要进行热词embedding处理,加上缓存处理复杂度较高!
要解答您的问题,我们需要从模型拆分、缓存处理以及热词embedding的复杂性三个方面进行分析,并结合您提到的paraformer-large-contextual offline模型和modelscope-funasr框架的特点来确认是否可以避免缓存处理。
在将模型转换为RKNN格式时,拆分模型是为了适配终端设备的硬件限制(如内存、计算能力等)。根据知识库中关于Paraformer模型的描述,Paraformer的核心功能是语音识别,其解码器(decoder)部分通常需要对中间状态进行缓存处理,尤其是在在线(online)推理场景下。这种缓存机制的主要目的是: - 在线推理:为了支持流式语音输入,解码器需要保存上一时刻的状态以保证上下文连贯性。 - 离线推理:理论上,离线推理不需要流式处理,因此可以省略缓存机制,直接对完整输入进行一次性解码。
然而,您提到的paraformer-large-contextual offline模型还涉及热词embedding处理,这增加了模型的复杂性。热词embedding的作用是动态调整模型对特定词汇的敏感度,从而提升识别准确率。如果在离线场景下引入缓存机制,可能会导致以下问题: - 复杂度增加:缓存机制需要额外的内存和计算资源,可能超出终端设备的能力。 - 性能下降:频繁的缓存读写操作可能导致推理延迟增加。
因此,是否可以避免缓存处理取决于模型的具体实现和终端设备的硬件条件。
根据modelscope-funasr框架的设计特点,offline模型的推理流程通常是基于完整输入的批量处理,而非流式处理。这意味着: - 无需上下文连贯性:由于输入数据是完整的语音片段,解码器可以直接生成最终结果,而不需要依赖上一时刻的状态。 - 热词embedding的独立性:热词embedding的处理可以在编码阶段完成,而不需要在解码阶段动态更新缓存。
因此,在理论上,modelscope-funasr的offline模型是可以避免缓存处理的。但需要注意以下几点: - 模型拆分的影响:如果拆分后的decoder部分仍然保留了缓存逻辑(例如为了兼容online模型的代码结构),则需要手动移除或禁用这些逻辑。 - 硬件限制:终端设备的计算能力和内存大小可能会影响是否能够完全避免缓存处理。如果设备资源有限,建议进一步优化模型结构以降低复杂度。
为了确认paraformer-large-contextual offline模型是否可以不进行缓存处理,您可以按照以下步骤进行验证和实施:
综上所述,modelscope-funasr的offline模型在理论上可以不进行缓存处理,但需要根据具体实现和硬件条件进行验证和优化。如果您在实施过程中遇到具体问题,可以进一步提供详细信息以便我们为您提供更精准的支持。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉答疑群:44837352
