
只有一张卡在用,图中modelscope问题怎么解决? 
在使用ModelScope模型时,如果遇到只有一张GPU卡可用的情况,并且出现相关问题,可以按照以下步骤进行排查和解决:
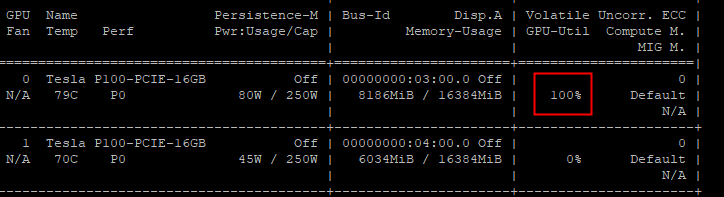
nvidia-smi命令查看当前GPU的显存大小和使用情况。precision字段,设置为fp16或int8。-replicas参数,减少副本数。max_batch_size为较小值,限制单次推理的批量大小。arena serve custom \
-name=modelscope \
-version=v1 \
-gpus=1 \
-replicas=1 \
-restful-port=8000 \
-image=<镜像地址> \
"MODEL_ID=qwen/Qwen1.5-4B-Chat python3 server.py"
-gpus=1:指定使用1张GPU卡。MODEL_ID:确保模型ID与实际需求一致。arena serve logs modelscope
arena serve get modelscope
Available字段显示为1,表示服务已成功启动。通过以上步骤,您可以有效解决单卡环境下ModelScope模型部署的问题。如果问题仍未解决,请提供具体的错误日志或现象,以便进一步分析。
