
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
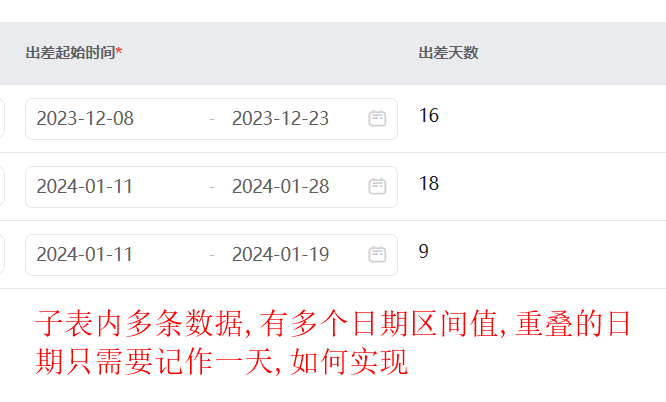
要实现去重并只计算相同的天数,可以使用以下步骤:
下面是一个示例代码,用于实现上述逻辑(假设日期区间表以列表的形式给出):
def remove_duplicates(date_ranges):
# 按起始日期排序
date_ranges.sort(key=lambda x: x[0])
result = []
current_range = date_ranges[0]
for i in range(1, len(date_ranges)):
if date_ranges[i][0] == current_range[1]:
# 当前日期区间与下一个日期区间连续,合并为一个日期区间
current_range = (current_range[0], max(current_range[1], date_ranges[i][1]))
else:
# 当前日期区间不连续,将其添加到结果集中,并将下一个日期区间设置为当前日期区间
result.append(current_range)
current_range = date_ranges[i]
# 添加最后一个日期区间到结果集中
result.append(current_range)
return result
使用示例:
date_ranges = [(1, 3), (2, 4), (5, 7), (6, 8), (9, 10)]
result = remove_duplicates(date_ranges)
print(result) # 输出: [(1, 4), (5, 8), (9, 10)]
在上述示例中,输入的日期区间表为[(1, 3), (2, 4), (5, 7), (6, 8), (9, 10)],经过去重处理后,输出的结果为[(1, 4), (5, 8), (9, 10)]。
为了实现这个需求,您可以使用数据库中的 DATE_TRUNC 函数和 DISTINCT 关键字。以下是一个可能的解决方案:
首先,假设您的数据库中有一个名为 trips 的表,其中包含以下字段:
SELECT DISTINCT
DATE_TRUNC('day', start_date) AS start_date,
DATE_TRUNC('day', end_date) AS end_date,
days
FROM
trips
ORDER BY
start_date;
CopyCopy
这个查询使用了 PostgreSQL 中的 DATE_TRUNC 函数,它允许您将一个日期字段截断为指定的单位(例如,天、月等)。在这里,我们使用 DATE_TRUNC('day', start_date) 将 start_date 截断为天,然后使用 DISTINCT 关键字去除重复的记录。最后,我们按 start_date 对结果进行排序。
通过这个查询,您可以得到一个去重后的结果集,其中相同的天数只计算一次。请注意,这个解决方案依赖于您的数据库支持 DATE_TRUNC 函数和 DISTINCT 关键字。如果您使用的是其他数据库系统,可能需要查找相应的函数来实现类似的功能。


