
机器学习PAI中看easyrec的训练,也没指定entryfile,这是怎么做的啊?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在机器学习PAI中,EasyRec的训练过程可以通过指定entryfile来指定训练数据的路径和格式。如果没有指定entryfile,则默认使用当前目录下的sample_data文件夹作为训练数据的来源。
在sample_data文件夹中,包含了一个名为sample_train.txt的文件,其中包含了用于训练的数据样本。每个数据样本由两部分组成:第一部分是特征向量,以空格分隔;第二部分是标签,通常是一个整数或浮点数。
例如,sample_train.txt文件中的一行数据可以是:
1.0 2.0 3.0 4.0 5.0 0
其中,1.0 2.0 3.0 4.0 5.0是特征向量,0是对应的标签。
在EasyRec的训练过程中,会根据指定的模型和参数对sample_train.txt中的样本进行训练。如果需要使用其他数据集进行训练,可以将数据集整理成与sample_train.txt相同的格式,并将其放在sample_data文件夹中,然后通过指定entryfile参数来指定新的数据集路径。
在机器学习PAI中,EasyRec的训练过程通常不需要指定entryfile。这是因为EasyRec通常使用数据集中的样本作为输入,并根据这些样本进行训练。以下是EasyRec训练的一般步骤:
1.数据准备:首先,需要准备用于训练的数据集。这个数据集通常包含多个样本,每个样本具有相应的特征和标签。
2.配置训练参数:在开始训练之前,需要配置EasyRec的训练参数。这些参数包括学习率、迭代次数、正则化强度等。
3.训练模型:在配置好参数后,可以开始训练EasyRec模型。训练过程中,EasyRec会自动读取数据集中的样本,并根据这些样本进行学习。
4.模型评估:在训练完成后,可以使用测试数据集对模型进行评估,以了解模型的性能。评估指标通常包括准确率、召回率、F1分数等。
5.模型优化:根据评估结果,可以对模型进行优化,以提高其性能。优化方法可能包括调整超参数、增加模型复杂度等。
6.部署:完成模型优化后,可以将模型部署到生产环境中,以供实际使用。
在整个训练过程中,EasyRec会自动处理数据加载和预处理,而不需要手动指定entryfile。这是因为EasyRec通常使用数据集中的样本作为输入,而不需要额外的entryfile来指定输入数据的格式或结构。
在阿里云机器学习PAI平台上使用EasyRec进行分布式训练时,通常需要通过PAI命令行或PAI Studio等界面上传配置文件并执行相应的训练脚本。虽然您提到没有明确指出entryFile,但在实际配置任务时,PAI系统依然需要知道哪个Python脚本或命令用于启动训练过程。
在PAI-EasyRec中,训练任务的启动脚本一般是隐含在平台内部实现中的,用户无需直接指定具体的entryFile。当您配置EasyRec的训练作业时,实际上是在提供一系列如数据源、模型结构、训练参数等信息,并通过PAI平台提供的模板或者向导完成任务的配置。
例如,在提交PAI-EasyRec训练任务时,您可能会间接地通过以下方式来定义训练流程:
即使您在提交任务时不直接指定entryFile,只要按照PAI-EasyRec的规范正确配置了训练任务的各项参数,系统就能识别出正确的启动入口并开始分布式训练。如果您遇到了具体的问题或需要更详细的配置指导,请提供更多关于您配置训练任务的具体情境或步骤。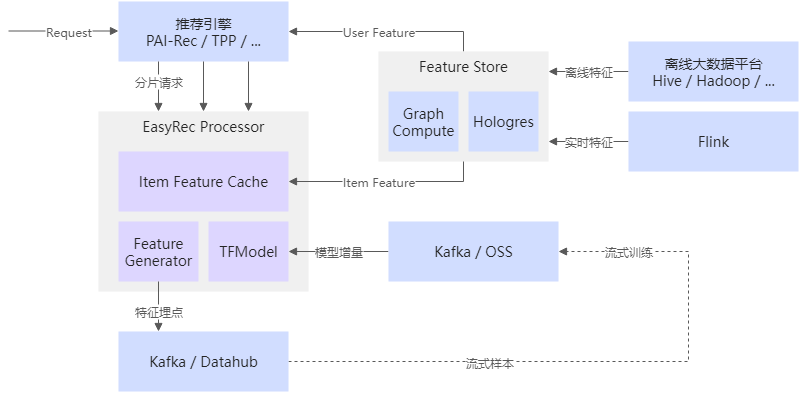
在阿里云机器学习PAI平台中,EasyRec是一个深度学习推荐系统解决方案,其训练过程不一定需要显式指定entry_file(入口文件)。在使用PAI训练EasyRec时,通常我们会通过PAI的Job配置或者可视化界面来配置训练任务,而不是直接指定一个entry_file。
在PAI中训练EasyRec时,主要需要配置如下几个关键要素:
数据源:指定训练数据所在的路径,包括用户行为数据、物品特征数据等。
模型配置:选择或自定义EasyRec的模型结构,如DIN、DIEN、DSSM等,并设置模型相关的超参数。
训练参数:设置训练批次大小、学习率、训练轮数等训练过程中的参数。
输出路径:指定模型训练完成后模型权重文件的输出位置。
在PAI平台上提交EasyRec的训练任务时,实际上是通过PAI的job配置文件或图形化界面提供的模板完成了上述配置,底层框架会根据配置生成相应的训练脚本和任务流程,而无需用户直接指定entry_file。
举个例子,通过PAI控制台创建EasyRec训练任务时,会通过填写表单或上传配置文件的方式来完成上述配置,而这些配置会被PAI后台系统转换为实际运行的训练脚本和任务指令。在这种情况下,entry_file虽然没有被用户直接指定,但实际上是隐含在PAI平台封装的训练流程之中的。
在PAI中,EasyRec的训练不需要指定entryfile,因为EasyRec通过Blink来构造实时样本和特征,并调用Feature Generation对特征进行加工,然后通过Kafka、DataHub读取实时的样本流进行训练。 实时训练的稳定性比较重要,我们在训练过程中对正负样本比、特征的分布、模型的auc等做实时的监控,当样本和特征的分布变化超过阈值时,报警并停止更新模型。 保存checkpoint时,EasyRec会同步记录当前训练的offsets(多个worker一起训练时,会有多个offset),当系统发生故障重启时,会从保存的offsets恢复训练。 效果验证 EasyRec在多个用户场景中得到了验证,场景中包括商品推荐、信息流广告、社交媒体、直播、视频推荐等。
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。


