
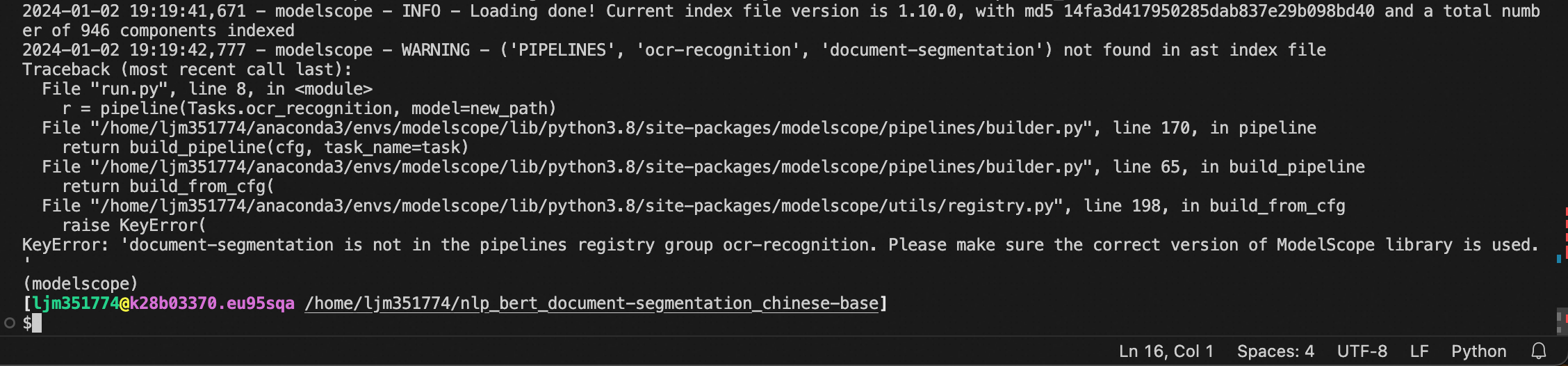
上图是modelscope什么原因造成的? from modelscope.outputs import OutputKeys
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
new_path = '/home/ljm351774/nlp_bert_document-segmentation_chinese-base/damo/nlp_bert_document-segmentation_chinese-base'
r = pipeline(Tasks.ocr_recognition, model=new_path)
result = r(documents='近年来,随着端到端语音识别的流行,基于Transformer结构的语音识别系统逐渐成为了主流。然而,由于Transformer是一种自回归模型,需要逐个生成目标文字,计算复杂度随着目标文字数量线性增加,限制了其在工业生产中的应用。针对Transoformer模型自回归生成文字的低计算效率缺陷,学术界提出了非自回归模型来并行的输出目标文字。根据生成目标文字时,迭代轮数,非自回归模型分为:多轮迭代式与单轮迭代非自回归模型。其中实用的是基于单轮迭代的>非自回归模型。对于单轮非自回归模型,现有工作往往聚焦于如何更加准确的预测目标文字个数,如CTC-enhanced采用CTC预测输出文字个数,尽管如此,考虑到现实应用中,语速、口音、静音以及噪声等因素的影响,如何准确的预测目标文字个数以及抽取目标文字对应的声学隐变量仍然是一个比较大的挑战;另外一方面,我们通过对比自回归模型与单轮非自回归模型在工业大数据上的错误类型(如下图所示,AR与vanilla NAR),发现,相比于自回归模型,非自回归模型,在预测目标文字个数方面差距较小,但是替换错误显著的增加,我们认为这是由于单轮非自回归模型中条件独立假设导致的语义信息丢失。于此同时,目前非自回归模型主要停留在学术验证阶段,还没有工业大数据上的相关实验与结论.')
r = result[OutputKeys.TEXT]
print(result[OutputKeys.TEXT])
这段代码使用了ModelScope的OCR识别(光学字符识别)功能,通过调用pipeline函数来执行任务。其中,Tasks.ocr_recognition表示任务类型为OCR识别,model=new_path表示使用指定路径下的模型进行识别。
在代码中,首先导入了所需的模块和常量:
from modelscope.outputs import OutputKeys
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
然后定义了一个变量new_path,用于存储模型的路径。接下来,通过调用pipeline函数并传入任务类型和模型路径,创建了一个OCR识别的管道对象r。
最后,将待识别的文档作为参数传递给管道对象r,并将结果存储在变量result中。通过访问OutputKeys.TEXT,可以获取到识别后的文本内容,并将其打印输出。
需要注意的是,这段代码中的documents参数是一个字符串,表示待识别的文档内容。你可以根据实际需求修改该参数的值。
改为r = pipeline("document-segmentation", model=new_path) 此回答整理至钉群“魔搭ModelScope开发者联盟群 ①”

