
modelscope-funasr中,在Linux系统上配置了Torch 2.1.1, FunASR 0.8.7, ModelScope 1.10.02,我尝试对下载的speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404模型进行量化导出。这个过程产生了一个TorchScripts文件,但当我将数据加载到这个模型并执行时,出现了错误,提示指出至少有两个设备上的张量不一致,cuda:0和cpu。可能问题代码是mask0 = torch.to(mask, torch.device("cpu"), 6),但不确定错误代码属于模型还是ModelScope的问题,而且使用ONNX时没有这个问题,只是ONNX输入是numpy格式而我的输入是tensor格式,这是怎么回事呢?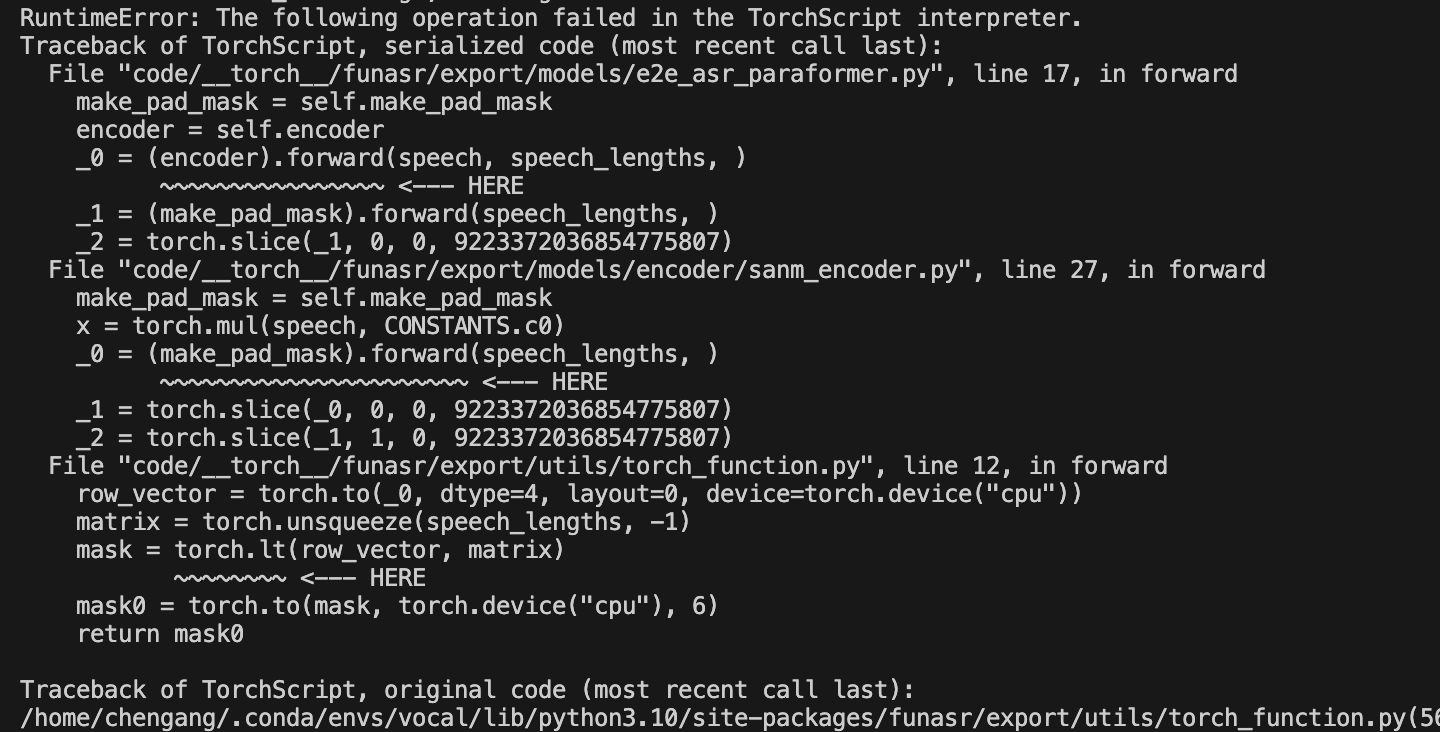
https://alibaba-damo-academy.github.io/FunASR/en/funasr/export/README.html
根据您提供的信息,问题的核心在于模型量化导出后,在加载和执行过程中出现了设备不一致的错误(cuda:0 和 cpu)。以下是针对该问题的详细分析与解决方法:
speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404 模型时,通过量化导出生成了一个 TorchScript 文件。cuda:0 和 cpu)。mask0 = torch.to(mask, torch.device("cpu"), 6)
这段代码尝试将张量 mask 转换到 CPU 设备,但可能未正确处理输入数据的设备一致性。
在 PyTorch 中,张量的设备(CPU 或 GPU)必须保持一致。如果模型在 GPU 上运行,则所有输入张量也必须位于 GPU 上;反之亦然。以下是具体操作步骤:
检查模型和输入张量的设备
在加载模型和输入数据时,确保它们位于同一设备上。例如:
# 假设模型已加载到 GPU
model = model.to("cuda:0")
# 将输入张量移动到 GPU
input_tensor = input_tensor.to("cuda:0")
修改问题代码
如果问题代码为:
mask0 = torch.to(mask, torch.device("cpu"), 6)
则需要根据模型的实际运行设备调整 torch.device 参数。例如,如果模型运行在 GPU 上,应改为:
mask0 = torch.to(mask, torch.device("cuda:0"), 6)
统一设备管理逻辑
在整个推理流程中,建议统一设备管理逻辑。例如:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
input_tensor = input_tensor.to(device)
导出时指定设备
在导出 TorchScript 文件时,确保模型和输入数据的设备一致。例如:
# 将模型和示例输入移动到同一设备
model = model.to("cuda:0")
example_input = example_input.to("cuda:0")
# 导出 TorchScript
scripted_model = torch.jit.script(model)
scripted_model.save("model.pt")
验证导出文件
加载导出的 TorchScript 文件并测试其运行是否正常:
loaded_model = torch.jit.load("model.pt")
loaded_model = loaded_model.to("cuda:0") # 确保加载到正确的设备
output = loaded_model(input_tensor.to("cuda:0"))
# 将 NumPy 数组转换为 PyTorch Tensor
input_tensor = torch.from_numpy(numpy_array).to("cuda:0")
pip install torch==2.0.1
pip install funasr==0.8.6
print(f"Model device: {next(model.parameters()).device}")
print(f"Input tensor device: {input_tensor.device}")
cuda:0 和 cpu),需要确保模型和输入张量位于同一设备上。希望以上解决方案能够帮助您解决问题!如果仍有疑问,请随时提供更多信息以便进一步分析。
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉答疑群:44837352
