
请教一下怎么用flinksql 写一个连接带有kerberos 认证的 hive 的catalog?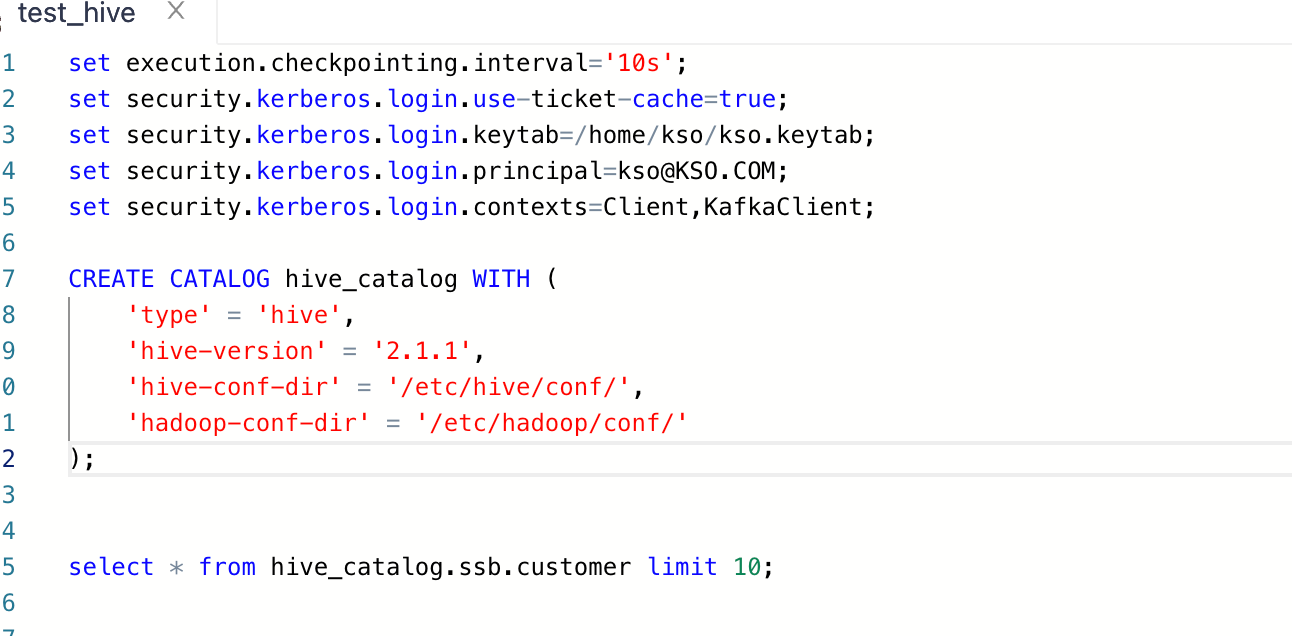
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要使用 Flink SQL 连接带有 Kerberos 认证的 Hive,你需要在 Flink要使用 Flink SQL 连接带有 Kerberos 认证的 Hive,你需要在 Flink SQL 中创建一个自定义的 Catalog,然后在该 Catalog 中配置 Hive 和 Kerberos 的相关参数。以下是一个简单的示例:
kerberos_hive_catalog:public class KerberosHiveCatalog extends AbstractCatalog {
private final String hiveMetastoreUri;
private final String principal;
private final String keytabPath;
public KerberosHiveCatalog(String hiveMetastoreUri, String principal, String keytabPath) {
this.hiveMetastoreUri = hiveMetastoreUri;
this.principal = principal;
this.keytabPath = keytabPath;
}
@Override
public Database getDatabase(String name) throws Exception {
// 在这里实现获取数据库的逻辑
}
// 其他需要实现的方法,例如 getTable、getFunctions 等
}
CREATE CATALOG kerberos_hive_catalog
WITH (
'type' = 'kerberos_hive',
'hive-metastore-uri' = 'thrift://your-hive-metastore-host:9083',
'principal' = 'your-principal@YOUR.REALM',
'keytab-path' = '/path/to/your/keytab/file'
);
USE kerberos_hive_catalog;
SHOW TABLES;
SELECT * FROM your_table;
注意:请根据实际情况替换上述代码中的占位符,例如 your-hive-metastore-host、your-principal@YOUR.REALM 和 /path/to/your/keytab/file。
flink必须写到配置文件里,kerberos配置只能从配置文件读 ,此回答整理自钉群“【③群】Apache Flink China社区”
要使用Flink SQL连接带有Kerberos认证的Hive,您需要按照以下步骤进行操作:
首先,确保您的Hive服务器已经配置了Kerberos认证。这通常涉及到在Hive配置文件(如hive-site.xml)中设置相关的Kerberos参数,例如Kerberos principal、keytab文件路径等。
接下来,在Flink SQL中创建一个自定义的catalog,用于连接到带有Kerberos认证的Hive。您可以使用CREATE CATALOG语句来创建一个新的catalog,并指定其类型为hive。然后,在catalog定义中提供必要的连接信息,包括Hive服务器的地址、端口、数据库名等。
下面是一个示例的Flink SQL代码,用于创建一个名为kerberos_hive_catalog的catalog,连接到带有Kerberos认证的Hive服务器:
CREATE CATALOG kerberos_hive_catalog
WITH (
'type' = 'hive',
'default-database' = 'your_database_name',
'hive.metastore.uris' = 'thrift://your_hive_server:9083',
'hive.metastore.kerberos.principal' = 'your_kerberos_principal@YOUR.REALM',
'hive.metastore.kerberos.keytab' = '/path/to/your/keytab/file',
'hive.metastore.kerberos.kinit.cmd' = 'kinit -kt /path/to/your/keytab/file your_kerberos_principal@YOUR.REALM'
);
请根据您的实际情况替换上述代码中的占位符,例如your_database_name、your_hive_server、YOUR.REALM、your_kerberos_principal和/path/to/your/keytab/file。
现在,您可以使用新创建的kerberos_hive_catalog来执行查询操作。例如,要查询Hive中的表数据,可以使用以下Flink SQL语句:
USE kerberos_hive_catalog;
SELECT * FROM your_table_name;
请将your_table_name替换为您实际要查询的表名。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


