
ModelScope如果想用tiktoken计算message token,红框里的建议值是什么?
ModelScope如果想用tiktoken计算qwen-14b的message token,红框里的建议值是什么?该函数来自langchain_community/chat_models/openai.py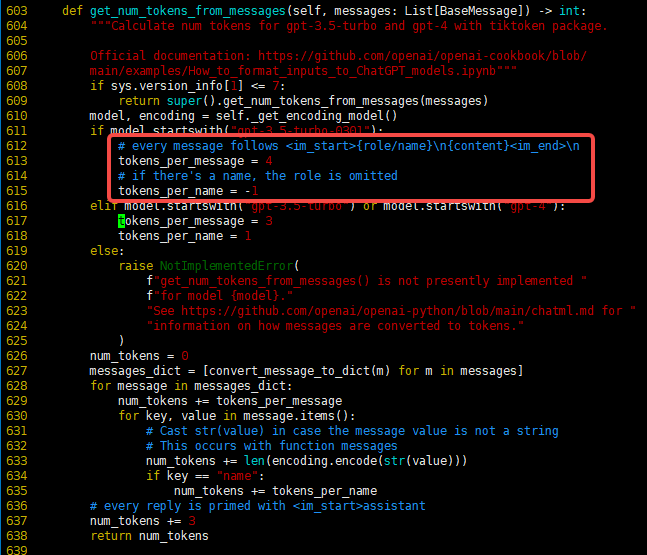
在使用 tiktoken 计算 qwen-14b 的 message token 时,红框中的建议值需要根据具体的模型分词规则和输入内容来确定。以下是详细的解答:
1. Token计算的基本原理
Token 是大语言模型处理文本的基本单位,不同的模型对文本的切分方式可能不同。对于通义千问系列模型(如 qwen-14b),可以通过其专用的 tokenizer 来查看文本被切分为哪些 token。
例如,以下代码展示了如何通过 dashscope 提供的工具获取 qwen-turbo 模型的 token 切分结果:
from dashscope import get_tokenizer
tokenizer = get_tokenizer('qwen-turbo') # 获取 tokenizer 对象
input_str = '通义千问具有强大的能力。'
tokens = tokenizer.encode(input_str) # 将字符串切分为 token id
print(f"经过切分后的 token id 为:{tokens}。")
print(f"经过切分后共有 {len(tokens)} 个 token。")
2. tiktoken 的使用方法
tiktoken 是 OpenAI 提供的一个高效工具,用于计算文本的 token 数量。虽然 tiktoken 主要针对 OpenAI 模型设计,但也可以通过加载自定义的编码规则来适配其他模型。
如果想用 tiktoken 计算 qwen-14b 的 message token,需要明确以下几点: - 编码规则:tiktoken 需要加载与 qwen-14b 兼容的编码规则。如果没有现成的规则文件,可以参考 dashscope 提供的 tokenizer 输出结果进行映射。 - 建议值:红框中的建议值通常是指模型对特定输入的最大 token 数限制或推荐值。对于 qwen-14b,建议值可能与上下文长度、最大输入长度等参数相关。
3. langchain_community/chat_models/openai.py 中的函数
在 langchain_community/chat_models/openai.py 中,tiktoken 的使用通常涉及以下步骤: 1. 加载编码器:
import tiktoken
encoding = tiktoken.get_encoding("cl100k_base") # 示例编码规则
- 计算 token 数量:
tokens = encoding.encode("通义千问具有强大的能力。") print(f"Token 数量: {len(tokens)}")
对于 qwen-14b,如果需要适配 tiktoken,可以尝试以下方法: - 使用 dashscope 提供的 tokenizer 输出结果,手动映射到 tiktoken 的编码规则。 - 如果有官方支持的 tiktoken 编码规则文件,直接加载该文件。
4. 红框中的建议值
根据知识库资料,qwen-14b 的上下文长度和最大输入长度可能会影响 token 的建议值。假设红框中的建议值是指最大输入长度,则可以参考以下信息: - 上下文长度:32,768 tokens。 - 最大输入长度:30,720 tokens。 - 最大输出长度:2,048 tokens。
因此,红框中的建议值可能是 30,720 tokens,即模型允许的最大输入长度。
5. 重要提醒
- 模型兼容性:确保使用的
tiktoken编码规则与qwen-14b的 tokenizer 兼容,否则可能导致 token 计算不准确。 - 上下文限制:超出模型的最大上下文长度(32,768 tokens)会导致错误,请务必控制输入长度。
如果您需要进一步的帮助或具体代码示例,请提供更多上下文信息。