
flink cdc 首次同步数据,应该是全量阶段的错误?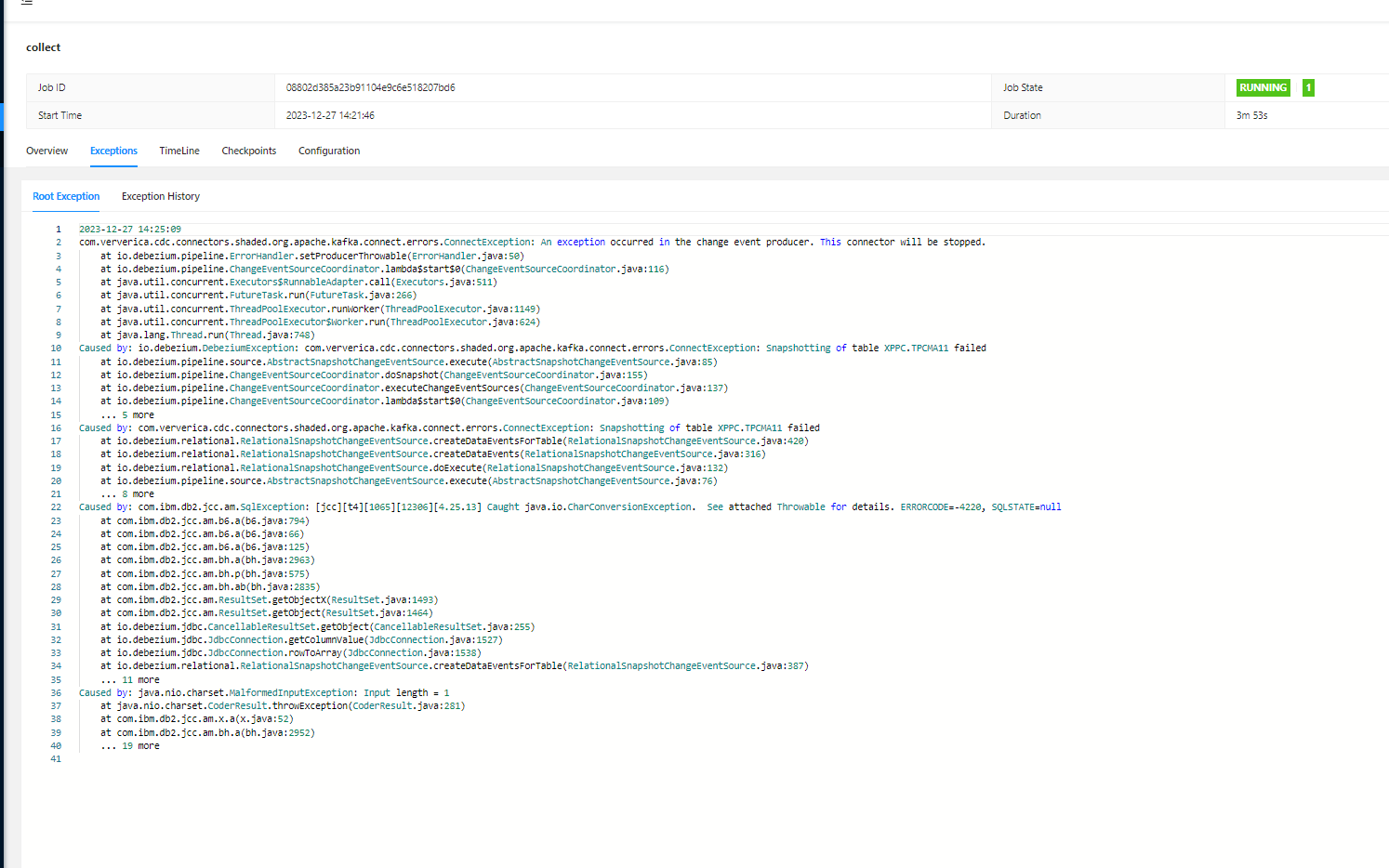
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用 Flink CDC 进行首次同步数据时,如果出现错误,通常可能与全量阶段的配置或环境问题有关。以下是可能导致全量阶段错误的原因及解决方案:
execution.checkpointing.interval: 5min。execution.checkpointing.tolerable-failed-checkpoints 参数值,以允许更长的快照读取时间。log-slave-updates = 1
gtid_mode = on
enforce_gtid_consistency = on
table-name 参数),但正则表达式中包含逗号,Debezium 会将其解析为分隔符,导致配置错误。'table-name' = '(t_process_wi_history_\d{1}|t_process_wi_history_\d{2})'
BinlogSplitReader is created 日志。Replication Slot 占用问题(Postgres CDC 相关):
'debezium.slot.drop.on.stop' = 'true' 参数。时区问题:
timestamp 字段时区相差 8 小时,可能是因为 CDC 作业中配置的 server-time-zone 参数与 MySQL 服务器时区不一致。server-time-zone 参数与 MySQL 服务器时区一致。首次同步数据时,全量阶段的错误通常与 内存配置、Checkpoint 设置、数据库实例类型、表结构变更 等因素相关。根据具体问题,您可以参考上述解决方案逐一排查和优化。如果问题仍未解决,建议检查 Flink 作业日志和数据库日志,定位具体的错误信息并采取针对性措施。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

