
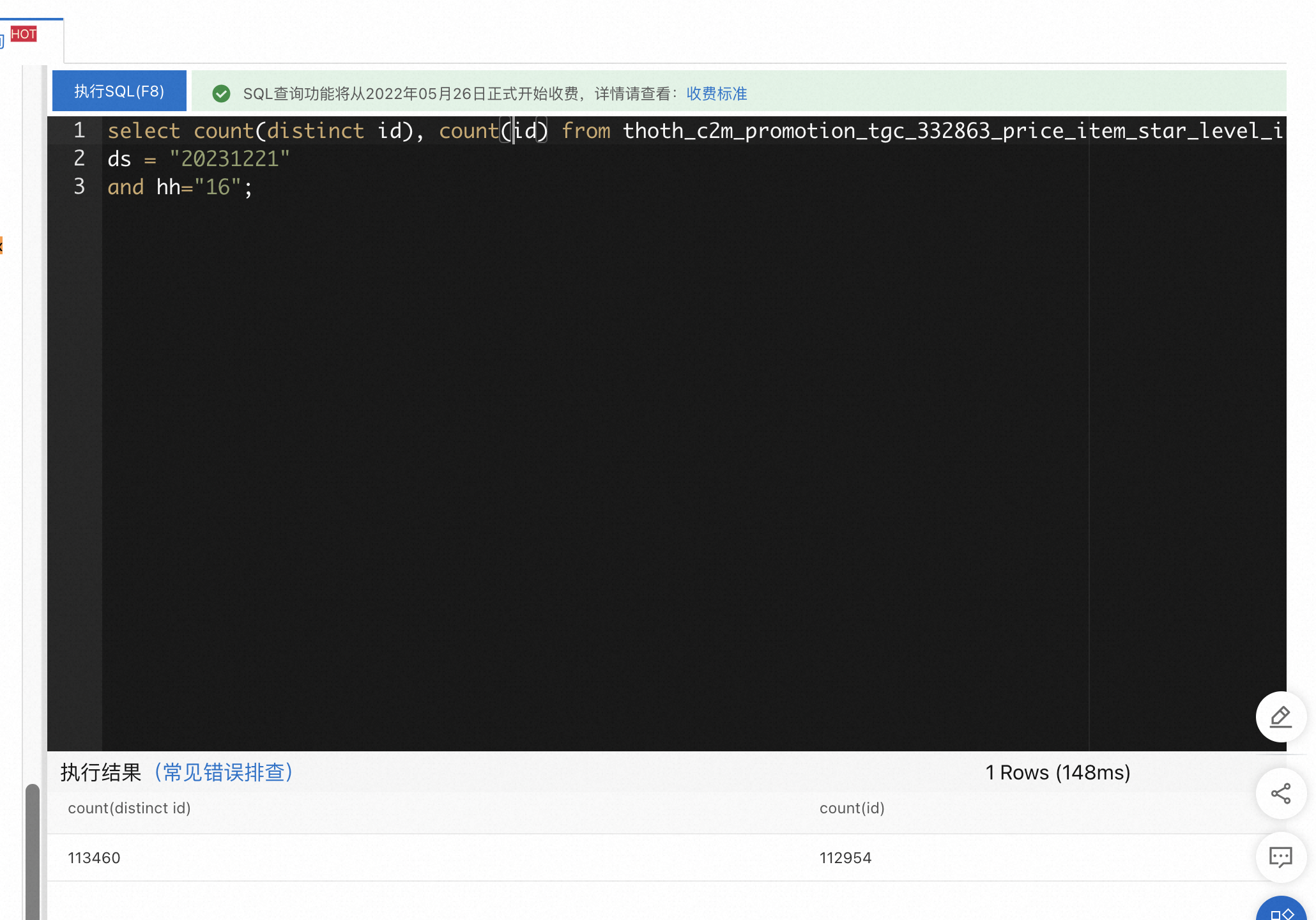
表格存储ots表查询,distinct后数据量变多了?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在SQL语句中,DISTINCT关键字用于去除重复行的结果集。当你对结果进行计数(COUNT(DISTINCT id))的时候,它会计算出唯一的不同id的数量。因此,如果你看到 count(distinct id) 和 count(id) 结果不同的话,那是因为这两个字段包含的数据并不完全相同。
例如,假设我们有一个订单表,其中有两个列分别是 order_id (唯一的订单ID) 和 customer_id(客户ID),如果我们执行如下两个查询:
SELECT COUNT(order_id), COUNT(customer_id)
FROM orders;
那么,第一个查询将返回所有不同的order_id数量,而第二个查询则返回所有的customer_id数量。通常情况下,这些数字应该是相等的,因为每个订单都应该对应一个唯一的客户。但是如果有多个相同的order_id但有不同的customer_id的情况,则会导致它们之间的差异。
当你说“distinct 后数据量变多”时,我理解为原本应该是一一对应的两组数据现在变得不再一一对应了。这种情况通常是由于某些记录具有相同的主键但仍属于不同的实体造成的。在这种情况下,你应该查看原始数据以及 DISTINCT 关键字所应用的具体条件,找出为什么会出现这样的现象,并据此调整 SQL 查询。
在表格存储中,使用DISTINCT关键字可以去除查询结果中的重复行。然而,在某些情况下,使用DISTINCT可能会导致数据量变多。
这种情况可能发生在使用多个列进行DISTINCT操作时。当您对多个列进行DISTINCT操作时,表格存储会返回所有不同的组合,而不仅仅是唯一的行。这可能导致查询结果中的数据量增加。
例如,假设您有一个名为"ots_table"的表格,其中包含两列"column1"和"column2"。如果您执行以下查询:
SELECT DISTINCT column1, column2 FROM ots_table;
表格存储将返回所有不同的"column1"和"column2"的组合,即使某些组合只出现一次或几次。因此,查询结果中的数据量可能会比原始表中的行数更多。
如果您希望仅获取唯一的行,而不包括重复的组合,可以使用GROUP BY子句来进一步筛选结果。例如:
SELECT column1, column2 FROM ots_table GROUP BY column1, column2;
这将返回每个唯一组合的一行,并去除重复的组合。请注意,使用GROUP BY可能会增加查询的复杂性和性能开销。
总结起来,使用DISTINCT关键字时需要注意其可能引起的数据量增加情况,特别是在对多个列进行DISTINCT操作时。根据具体需求,您可以选择适当的方法来处理重复数据。

