
Flink CDC这个AI 说的 每个key状态 和每个并行度的状态 怎么测试区分?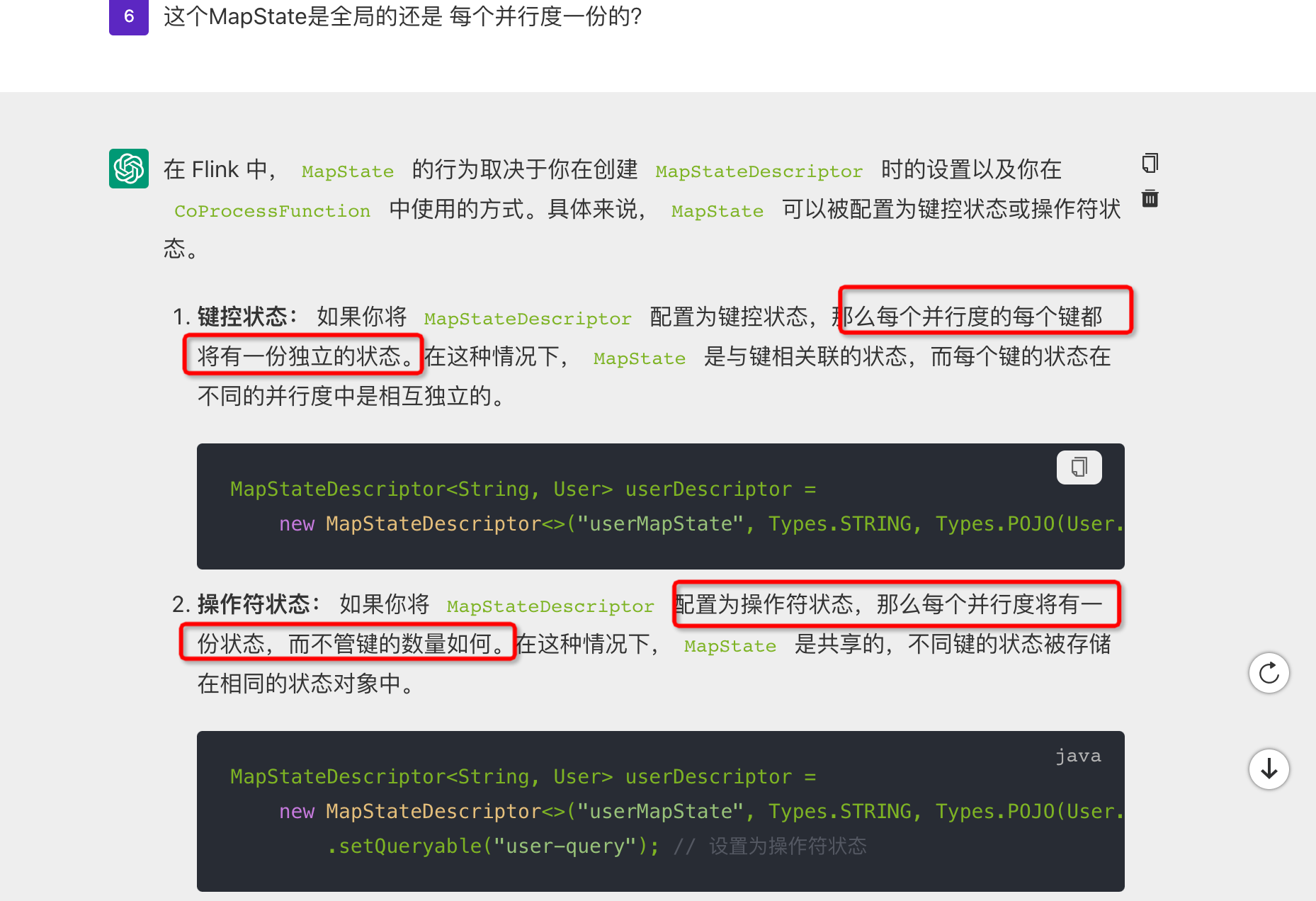
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink CDC(Change Data Capture)场景中,测试和区分每个Key的状态与每个并行度的状态是理解作业行为和性能调优的重要环节。以下是具体的测试方法和区分方式:
每个Key的状态通常由Flink的State Backend管理,用于存储分组聚合、窗口计算等操作的中间结果。要测试每个Key的状态,可以按照以下步骤进行:
numBytesUsed(状态占用的字节数)和numKeys(状态中存储的Key数量)。这些指标可以通过Flink Web UI或Prometheus等监控工具查看。state.backend为rocksdb或filesystem,以便更直观地观察状态存储的行为。INSERT INTO source_table VALUES ('key1', 'value1'), ('key2', 'value2'), ('key3', 'value3');
SELECT DISTINCT或GROUP BY操作时,检查每个Key的状态是否被正确维护。state.ttl参数,例如:
CREATE TABLE test_table (
id STRING,
value STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'state.ttl' = '10min'
);
每个并行度的状态是指Flink作业中每个并行子任务(Subtask)所维护的状态。由于Flink的并行度决定了任务的分区数,因此需要测试并行度对状态分布的影响。
env.setParallelism(4);
SET parallelism.default = 4;
numBytesUsed:每个并行子任务使用的状态字节数。numRecordsIn:每个并行子任务处理的记录数。key.fields-prefix属性避免字段冲突。为了区分每个Key的状态与每个并行度的状态,可以从以下几个方面入手:
Key Group数量 = maxParallelism
/tmp/flink/state/rocksdb/<job-id>/<operator-id>/<subtask-index>
numKeys)和每个并行子任务的状态指标(如numBytesUsed)。如果某个并行子任务的状态显著大于其他子任务,可能存在数据倾斜问题。execution.checkpointing.interval: 60000
state.backend: rocksdb
key.fields-prefix属性解决。通过上述方法,您可以有效测试和区分Flink CDC作业中每个Key的状态与每个并行度的状态,从而更好地优化作业性能和稳定性。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

