
Flink CDC中,读取pg开启增量快照,并行度设置为5个,运行完成5个ck后就报图片这个错误,这怎么解决?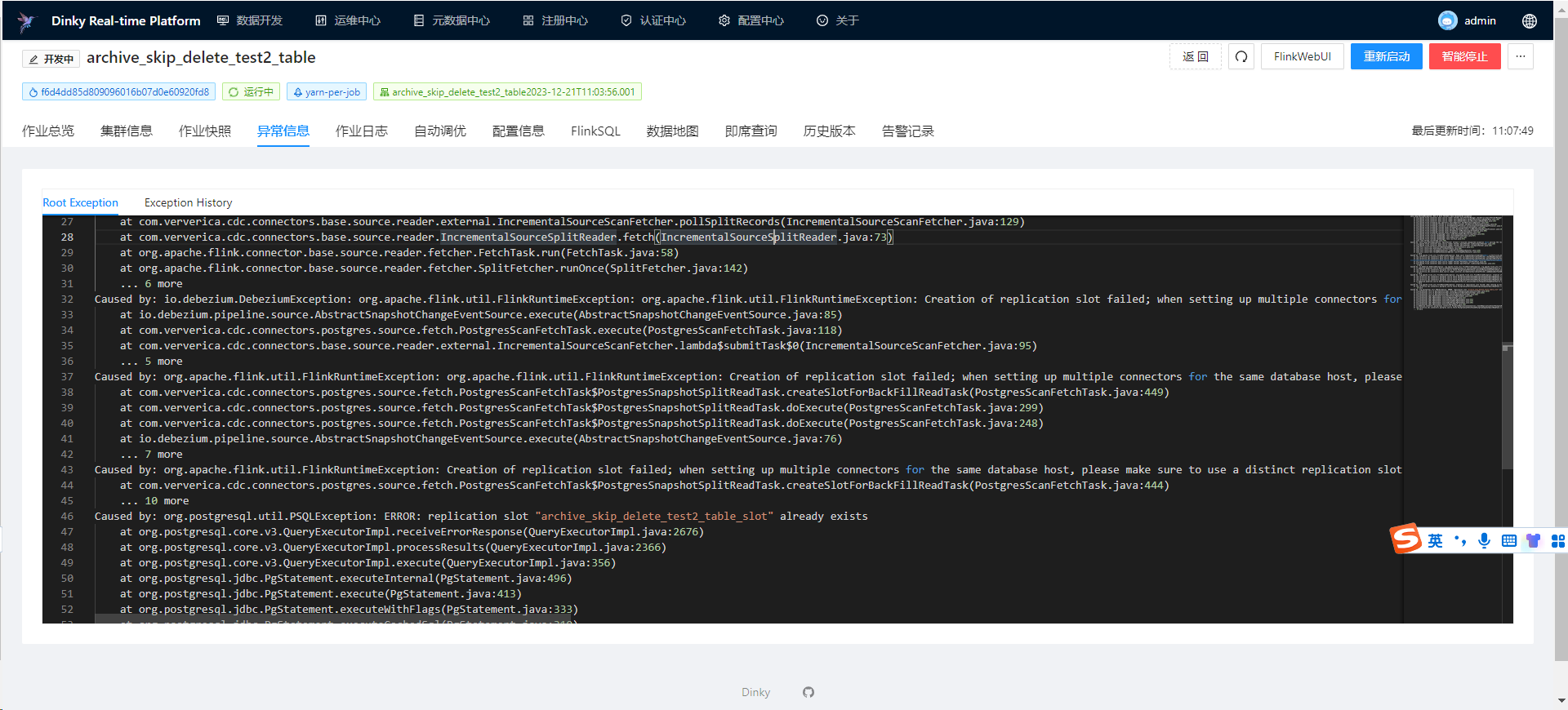
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据用户描述,Flink CDC在读取PostgreSQL(pg)时开启了增量快照功能,并设置了并行度为5。运行完成5个Checkpoint(ck)后报错。结合知识库中的信息,可以推测问题可能与以下因素相关:
max_wal_senders或max_replication_slots参数值不足,可能导致作业失败。max_replication_slots参数值大于当前已使用的Slot数量与Flink作业所需的Slot数量之和。slot.name参数,避免Slot名称冲突。例如:CREATE TABLE source_table (
...
) WITH (
'connector' = 'postgres-cdc',
'slot.name' = 'custom_slot_name',
...
);
execution.checkpointing.interval),建议设置为10分钟或更长:execution.checkpointing.interval: 10min
execution.checkpointing.tolerable-failed-checkpoints),以应对大表全量同步时的Checkpoint超时问题:execution.checkpointing.tolerable-failed-checkpoints: 100
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 2147483647
max_wal_senders或max_replication_slots参数值不足,可能导致作业失败。max_wal_senders和max_replication_slots参数值,确保其满足Flink作业的需求。例如:ALTER SYSTEM SET max_wal_senders = 10;
ALTER SYSTEM SET max_replication_slots = 10;
SELECT pg_reload_conf();
max_wal_senders和max_replication_slots的可用资源。wal_level参数设置为logical。REPLICA IDENTITY设置为FULL,以保障数据同步的一致性。scan.incremental.snapshot.enabled=false),观察作业是否正常运行。通过以上步骤,您可以逐步排查并解决Flink CDC读取PostgreSQL时的错误问题。重点检查以下内容: 1. Replication Slot管理:确保Slot数量充足且及时清理。 2. Checkpoint配置:合理设置Checkpoint时间间隔和失败容忍次数。 3. 数据库资源限制:调整max_wal_senders和max_replication_slots参数值。 4. 增量快照功能:验证使用条件并考虑关闭该功能以排除潜在问题。
如果问题仍未解决,请提供具体的错误日志信息,以便进一步分析和定位问题。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

