
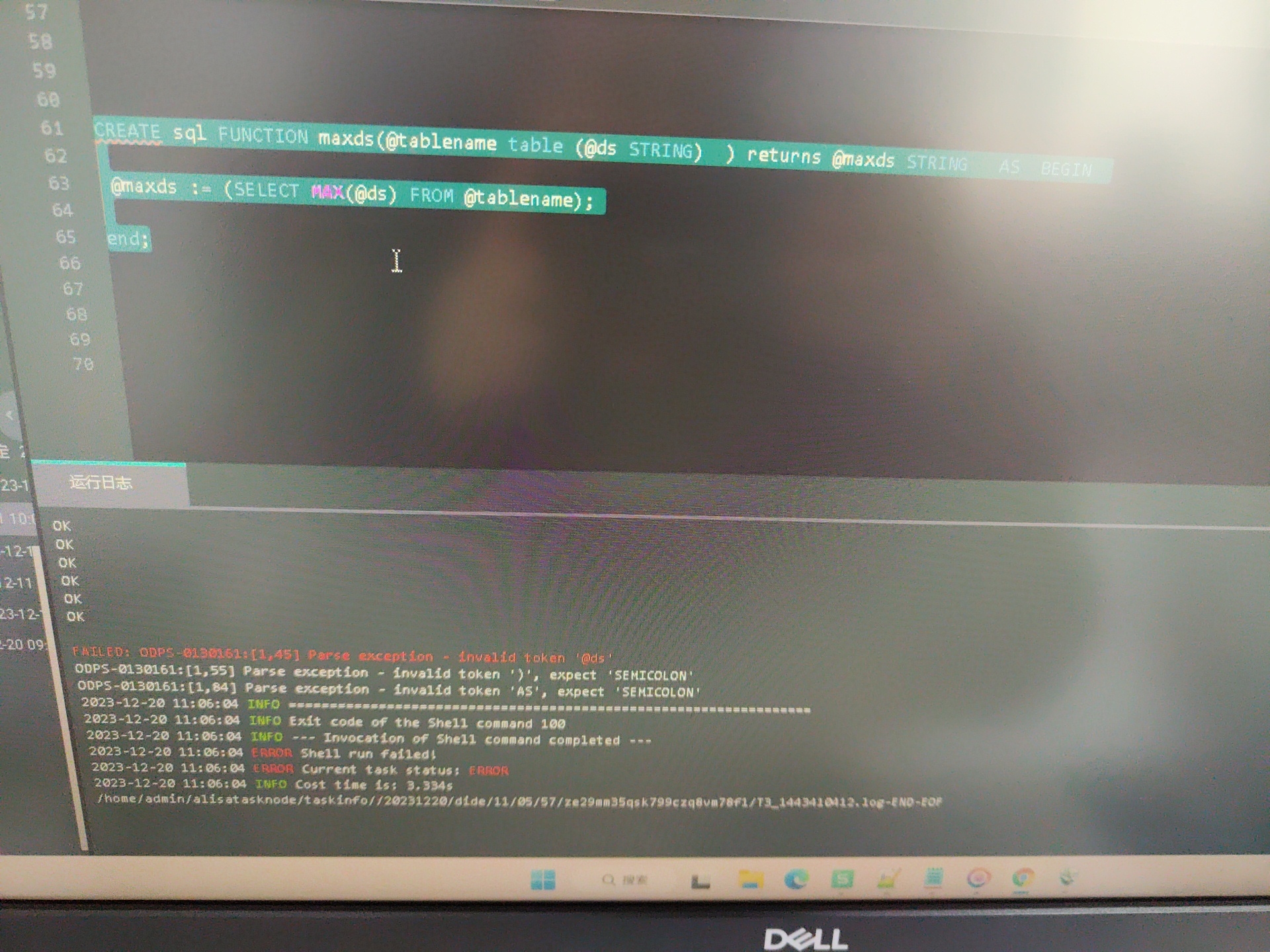
大数据计算MaxCompute odps函数表作为参数 有资料吗?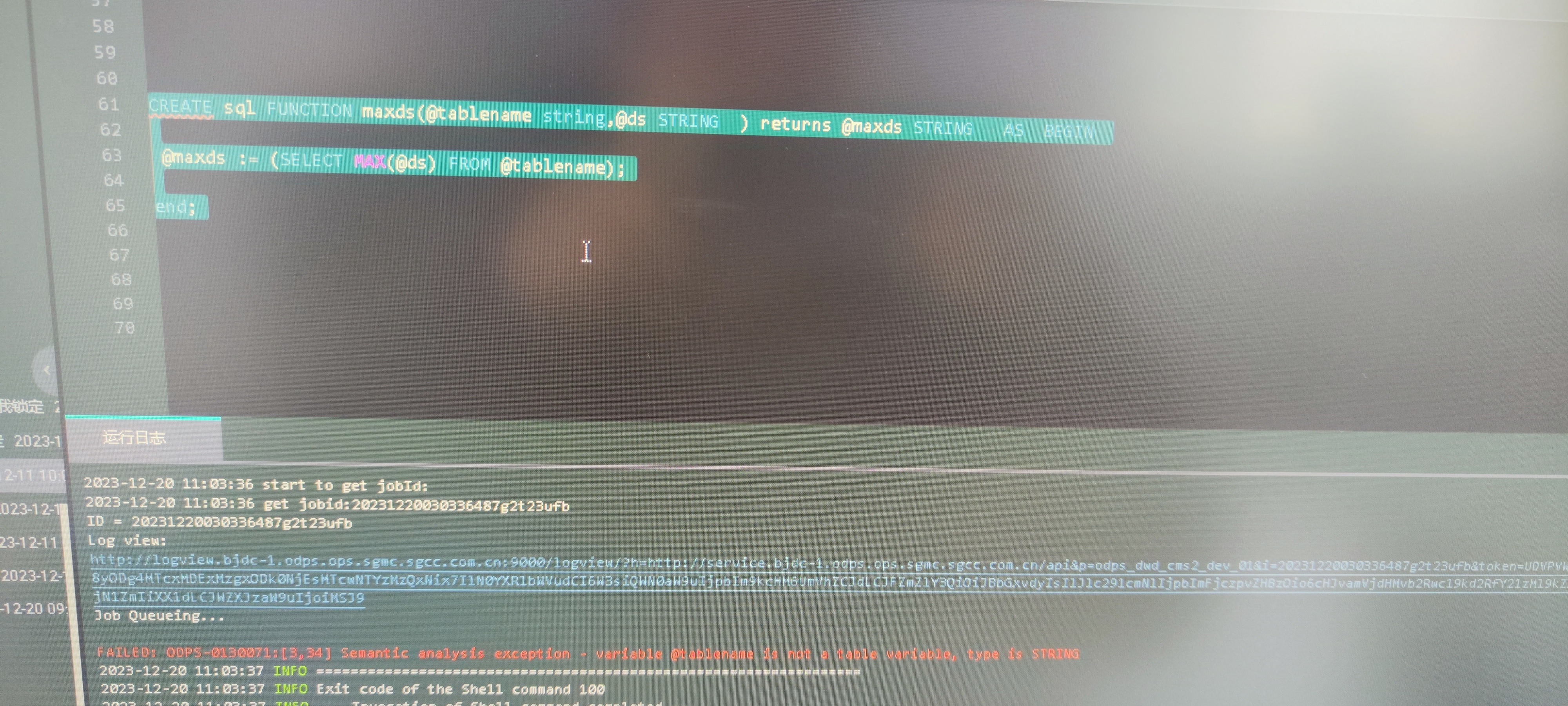
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在MaxCompute(原ODPS)中,函数表作为参数的使用场景主要涉及一些特定的内置函数或自定义函数(UDF),这些函数可以接受表名、列名或其他元数据信息作为输入参数。以下是基于知识库资料的相关内容总结和说明:
在MaxCompute中,某些函数支持将表或列作为参数进行操作,主要用于以下场景: - 聚合函数:如PERCENTILE_APPROX等,允许对指定列进行统计计算。 - 窗口函数:如COLLECT_LIST等,支持在窗口范围内对表的列进行操作。 - 元数据查询函数:如PARTITION_EXISTS、TABLE_EXISTS等,用于检查表或分区是否存在。 - 采样函数:如SAMPLE,支持对表中的数据进行采样。
PERCENTILE_APPROX 是一个典型的聚合函数,支持以列作为参数进行近似百分位计算: - 命令格式:
DOUBLE percentile_approx(colname, p [, B])
colname:必填,值为DOUBLE类型的列。p:必填,需要计算的百分位数,取值范围为[0.0, 1.0]。B:可选,精度参数,默认值为10000。sal)的0.3百分位值:
SELECT percentile_approx(sal, 0.3) FROM emp;
窗口函数支持在指定的窗口范围内对表的列进行操作。例如,COLLECT_LIST 可以收集窗口内的列值: - 命令格式:
ARRAY collect_list(colname) OVER (PARTITION BY ... ORDER BY ... [ROWS|RANGE BETWEEN ... AND ...])
tbl包含pid、oid、rid三列,以下语句按pid分组并按oid排序,收集窗口内的rid值:
SELECT pid, oid, rid,
COLLECT_LIST(rid) OVER (PARTITION BY pid ORDER BY oid ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS window
FROM tbl;
PARTITION_EXISTS 和 TABLE_EXISTS 是用于检查表或分区是否存在的元数据函数: - 命令格式:
BOOLEAN PARTITION_EXISTS(table_name, partition_spec)
BOOLEAN TABLE_EXISTS(table_name)
foo的分区ds='20190101', hr='1'是否存在:
SELECT PARTITION_EXISTS('foo', '20190101', '1');
SAMPLE 函数支持对表中的数据进行采样,常用于大数据集的抽样分析: - 命令格式:
BOOLEAN SAMPLE(bucket_num, bucket_id [, colname])
bucket_num:总桶数。bucket_id:目标桶编号。colname:可选,指定采样的列。tbla的cola列进行哈希采样,取第1桶的数据:
SELECT * FROM tbla WHERE SAMPLE(4, 1, cola);
NULL值,大多数函数会跳过该行的计算。odps.sql.hive.compatible参数。MaxCompute提供了丰富的内置函数,支持将表或列作为参数进行操作,涵盖聚合、窗口、元数据查询和采样等多种场景。用户可以根据具体需求选择合适的函数,并注意相关限制和优化建议。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。

