
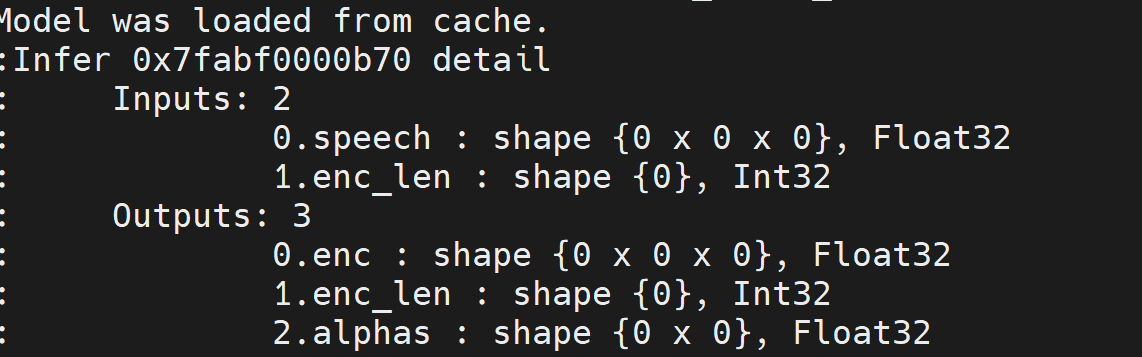
modelscope-funasr中文识别模型的encoder 模型 ,int32怎么量化成int8?
要将ModelScope FunASR中文识别模型的encoder模型从int32量化为int8,可以参考以下步骤。这些步骤基于PAI-Blade提供的量化优化方法,适用于TensorFlow或PyTorch模型。
在进行量化之前,需要确保以下资源已准备就绪: - 模型文件:获取FunASR中文识别模型的encoder部分(假设为TensorFlow或PyTorch格式)。 - 测试数据:用于验证量化后模型的精度。 - 校正数据集:用于离线计算量化参数,确保量化后的模型性能和精度满足要求。
根据PAI-Blade的文档,您需要下载示例模型、测试数据及校正数据集。以下是通用的下载命令(请替换为实际的FunASR模型路径):
# 下载模型文件
wget <模型文件URL>
# 下载测试数据
wget <测试数据URL>
# 下载校正数据集
wget <校正数据集URL>
如果您的模型是TensorFlow格式,可以使用以下代码加载模型、测试数据和校正数据集:
import numpy as np
import tensorflow as tf
# 加载模型
graph_def = tf.GraphDef()
with open('frozen.pb', 'rb') as f:
graph_def.ParseFromString(f.read())
# 加载测试数据
test_data = np.load('test_bc32.npy', allow_pickle=True, encoding='bytes').item()
# 加载校正数据集
calib_data = np.load('calib_data_test_bc32.npy', allow_pickle=True, encoding='bytes')
如果您的模型是PyTorch格式,可以使用以下代码加载模型、测试数据和校正数据集:
import torch
# 加载模型
pt_model = torch.jit.load('traced_model.pt')
# 加载测试数据
test_data = torch.load('test_bc32.pth')
# 加载校正数据集
calib_data = torch.load('calib_data_test_bc32.pth')
使用PAI-Blade工具对模型进行离线INT8量化优化。以下是具体代码示例:
import blade
# 执行量化优化
optimized_model, opt_spec, report = blade.optimize(
model=graph_def,
optimization_level='o2',
device_type='gpu',
test_data=test_data,
calib_data=calib_data
)
import blade
# 执行量化优化
optimized_model, opt_spec, report = blade.optimize(
model=pt_model,
optimization_level='o2',
device_type='gpu',
test_data=test_data,
calib_data=calib_data
)
量化完成后,建议在测试数据集上验证模型的精度,以确保量化后的模型性能满足需求。如果精度下降明显,可以通过调整量化配置来优化结果。例如:
quant_config = {
'weight_adjustment': 'true'
}
# 重新执行量化优化
optimized_model, opt_spec, report = blade.optimize(
model=graph_def, # 或 pt_model
optimization_level='o2',
device_type='gpu',
test_data=test_data,
calib_data=calib_data,
config=blade.Config(quant_config=quant_config)
)
通过上述步骤,您可以成功将ModelScope FunASR中文识别模型的encoder部分从int32量化为int8,从而减少内存占用并提升推理效率。
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉群号:44837352
