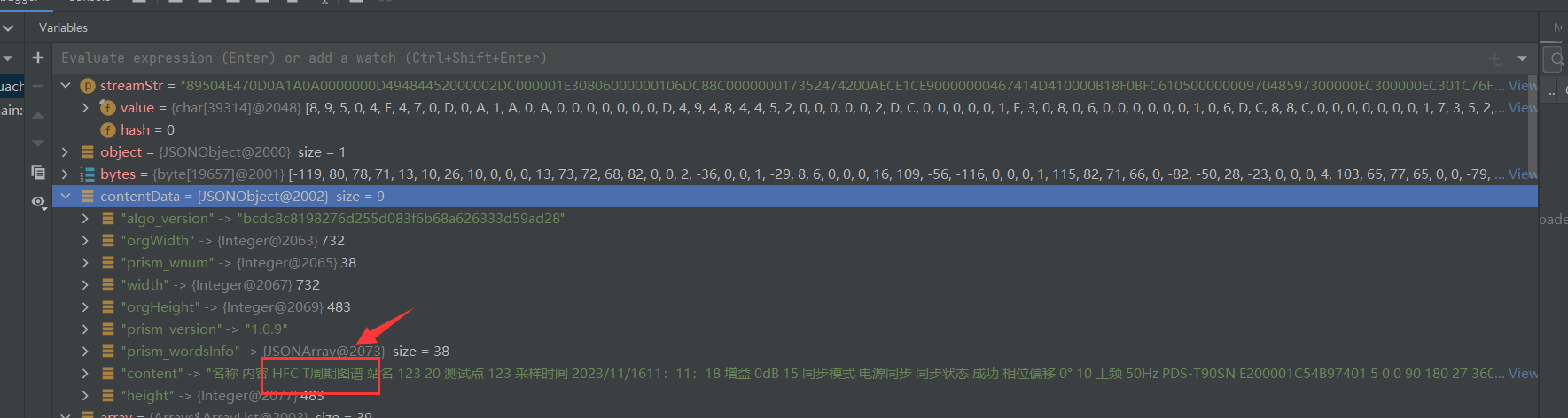
在使用文字识别OCR服务时,如果图片中的表头(如“HFCT周期图谱”)出现换行的情况,并且识别结果将其分开,这可能是由于以下原因导致的:
1. 图片质量问题
- 如果图片中文字的清晰度较低、存在反光、扭曲或模糊等问题,OCR算法可能无法准确判断文字的连贯性,从而将本应连续的文字误分为多段。
- 建议:尽量提供高清晰度、无反光、无扭曲的图片。确保图片内单字大小在10-50px范围内,以获得最佳识别效果。
2. 文字排版复杂性
- 如果图片中的文字排版较为复杂(例如换行、间距不均匀等),OCR算法可能会根据视觉上的分隔错误地分割文字。
- 建议:
- 将图片中的文字内容重新排版为单行,避免换行或复杂的布局。
- 如果图片中包含多张子图,建议将每张子图拆解为单独的图片进行调用识别。
3. OCR算法的局限性
- OCR算法基于深度学习模型,虽然能够处理大部分常见场景,但对于某些特殊排版或格式(如表头换行、特殊符号等),可能存在一定的识别误差。
- 建议:
- 对于少量识别错误,可以通过人工核对的方式修正。
- 如果此类问题频繁发生,可以将问题反馈给阿里云团队,提供具体的图片样本以便针对性优化。
4. 接口选择与参数调整
- 不同的OCR接口对图片的处理方式有所不同。例如,通用文字识别接口和结构化识别接口在处理复杂排版时的表现可能有所差异。
- 建议:
- 根据实际需求选择合适的接口。例如,对于表格或结构化数据,可以尝试使用
RecognizeEduPaperStructed(精细版结构化切题)接口。
- 在调用接口时,确保图片尺寸适中(建议长宽均大于500px),并避免图片过大或过小影响识别精度。
5. 后处理逻辑
- 如果OCR识别结果中出现了换行或分隔错误,可以在后端增加一定的文本处理逻辑,例如通过关键词匹配或规则拼接,将“HFCT”和“周期图谱”重新组合为完整表头。
总结
针对表头“HFCT周期图谱”被分开识别的问题,您可以从图片质量、文字排版、接口选择以及后处理逻辑等方面进行优化。如果问题仍然存在,建议联系阿里云技术支持团队,提供具体的图片样本以便进一步分析和优化。

 "
"
