
Flink CDC这个没有异常,怎么看是啥问题?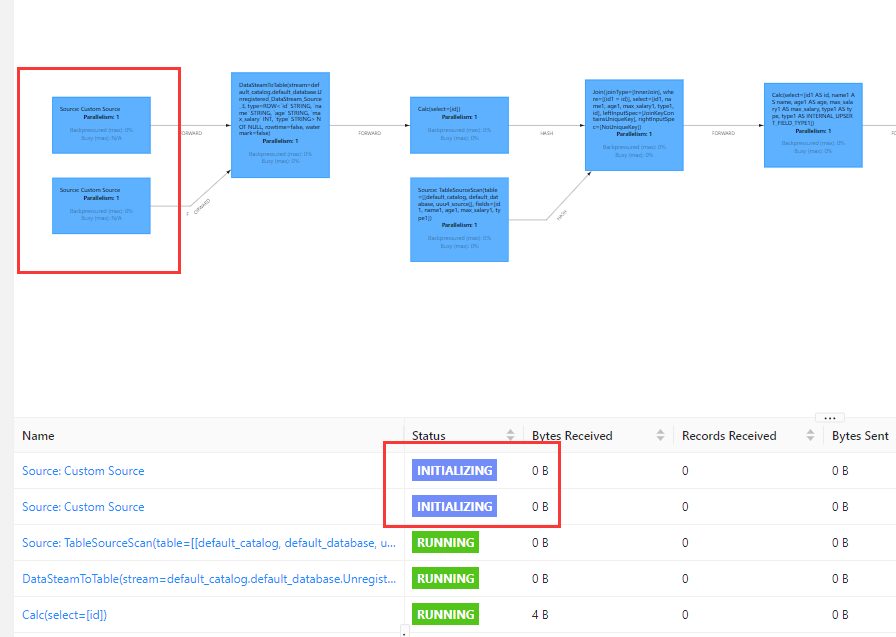
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要判断Flink CDC作业是否存在问题,即使没有明显的异常信息,也可以通过以下步骤进行排查和分析。以下是详细的排查方法和建议:
查看作业的重启次数
检查Num of Restarts指标,该指标表示作业错误恢复的次数。如果该值持续增加,说明作业可能存在潜在问题。
操作建议:在Flink UI中查看作业的状态总览页面,确认是否有频繁的重启现象。
检查Watermark推进情况
如果作业中使用了基于事件时间的窗口操作,需要确保Watermark能够正常推进。如果Watermark停滞不前,可能导致窗口无法触发输出。
可能原因:上游数据源(如Kafka分区)长时间无数据进入,导致分区被标记为空闲状态。
解决方案:设置table.exec.source.idle-timeout参数,例如table.exec.source.idle-timeout: 1s,以排除空闲分区对Watermark计算的影响。
业务延时(current Emit Event Time Lag)
该指标反映了从数据产生到作业处理完成的时间差。如果该值较大,说明作业在拉取或处理数据上存在延迟。
排查方向:
传输延时(current Fetch Event Time Lag)
该指标反映了从数据源拉取数据的时间差。如果该值较大,说明Source算子在拉取数据时存在瓶颈。
排查方向:
记录输入与输出数量
numRecordsIn:所有Operator的输入记录总数。如果某个算子的输入记录数长时间未增长,可能是上游数据源未正常提供数据。numRecordsOut:输出记录总数。如果某个算子的输出记录数长时间未增长,可能是作业逻辑存在问题。JobManager日志
如果JobManager未能正常启动,可以通过以下方式快速定位问题:
error,获取异常信息。<Logger level="ERROR" name="org.apache.flink.fs.osshadoop.shaded.com.aliyun.oss"/>。TaskManager日志
检查TaskManager日志中是否存在异常堆栈信息,尤其是与Source算子相关的部分。重点关注以下内容:
MySQL CDC相关配置
timestamp字段存在时区偏差,需检查server-time-zone参数是否与MySQL服务器时区一致。ROW模式。如果使用STATEMENT或MIXED模式,可能导致数据解析失败。Kafka相关配置
如果Flink CDC将数据写入Kafka,需检查Kafka的消费情况:
BackPressure页面定位问题:
Thread Dump页面分析线程堆栈,定位具体的瓶颈点(如CPU密集型操作或I/O阻塞)。table.exec.source.cdc-events-duplicate=true,并在源表上定义主键。通过以上步骤,您可以全面排查Flink CDC作业的潜在问题。重点检查作业状态、性能指标、日志信息以及数据源配置,并结合BackPressure分析定位瓶颈点。如果问题仍未解决,可以进一步提供具体的日志或监控数据,以便更深入地分析。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

