Flink的ctas有办法把 这三个字段也同步进去嘛?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,看了你的问题描述,你可以直接通过Flink的CTAS功能来实现,具体如下所示: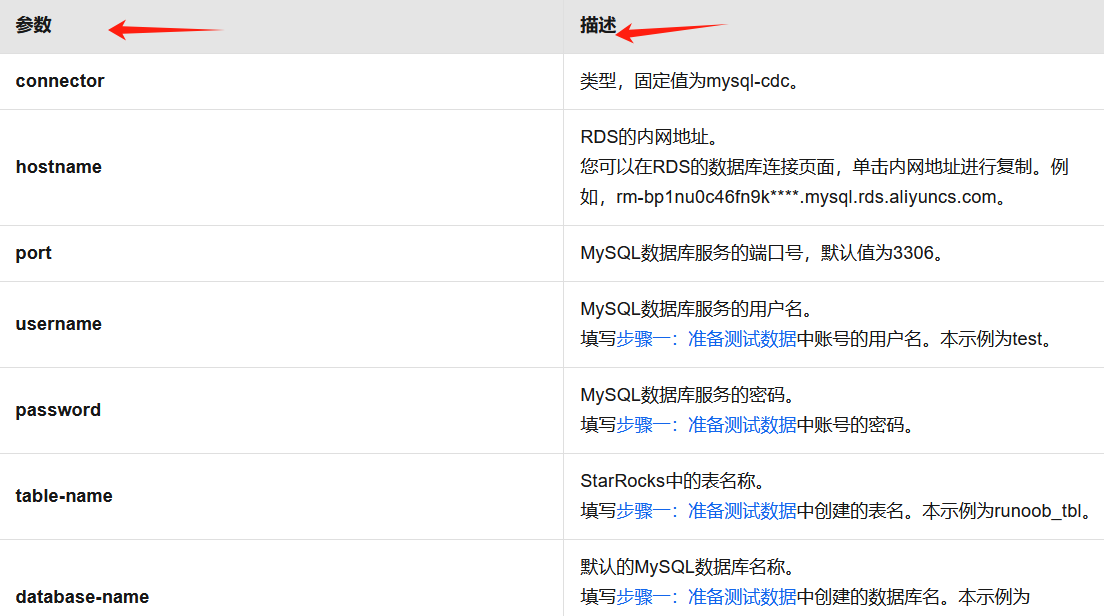
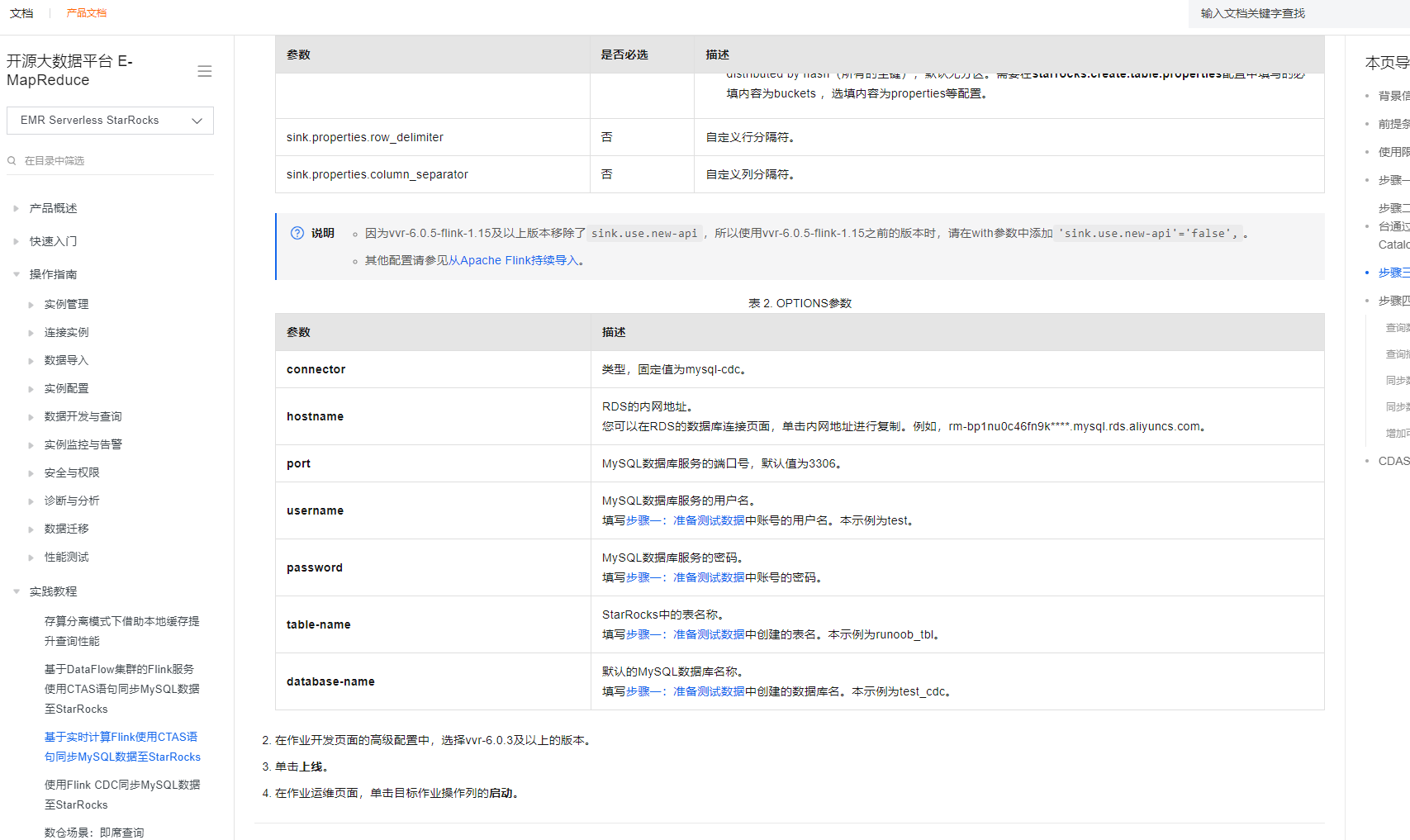
注意:本回答参考了阿里云开源大数据平台 E-MapReduce官方文档
Flink的CTAS功能不仅可以实时同步数据,还能将上游表结构(Schema)的变更同步到下游表。这一特性提高了在目标存储中创建表和维护源表结构变更的效率。然而,在使用CTAS语句时,如果需要调整已有字段的数据类型,例如从VARCHAR(10)改为VARCHAR(20),需要注意一些版本兼容性问题。在Flink计算引擎VVR 6.0.5以下的版本,上游修改数据类型可能导致CTAS任务失败。因此,当需要将三个特定字段同步进去的时候,你需要首先确保你的Flink版本支持这种操作,并且对这三个字段的数据类型进行正确的设定。
是的,在使用CTAS(Create Table As Select)命令的时候,可以通过INSERT INTO TABLE (database_name, table_name, op_ts) SELECT ... FROM ...的方式将这三个字段插入到目标表中。但是需要注意以下几个方面:
数据一致性:CTAS是一个一次性操作,不会捕获后续发生的事务变更。所以,如果你想保持这些字段是最新的,就需要定期刷新源表并将最新值更新到目标表中。
并发控制:如果有多个用户并发修改同一个记录,可能会出现冲突。为了避免这种问题,可以在应用层实现乐观锁或者其他并发控制策略。
版本选择:如果源表中有大量的历史数据并且你想保留每个版本的不同副本,那么可能需要设计多级复制机制或者专门的归档系统来满足需求。
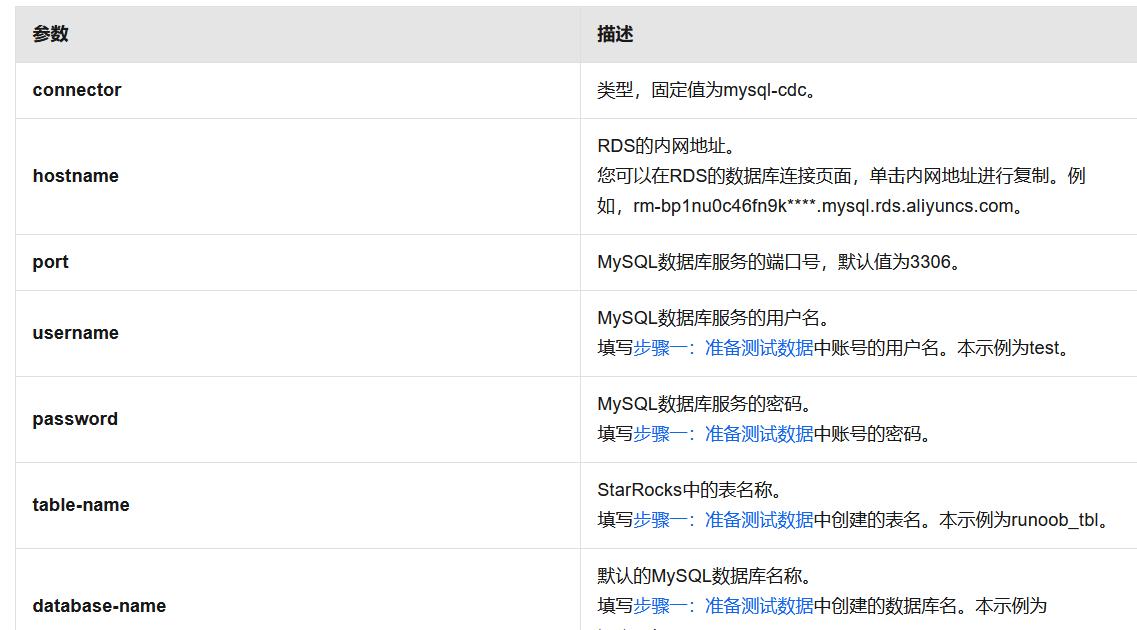
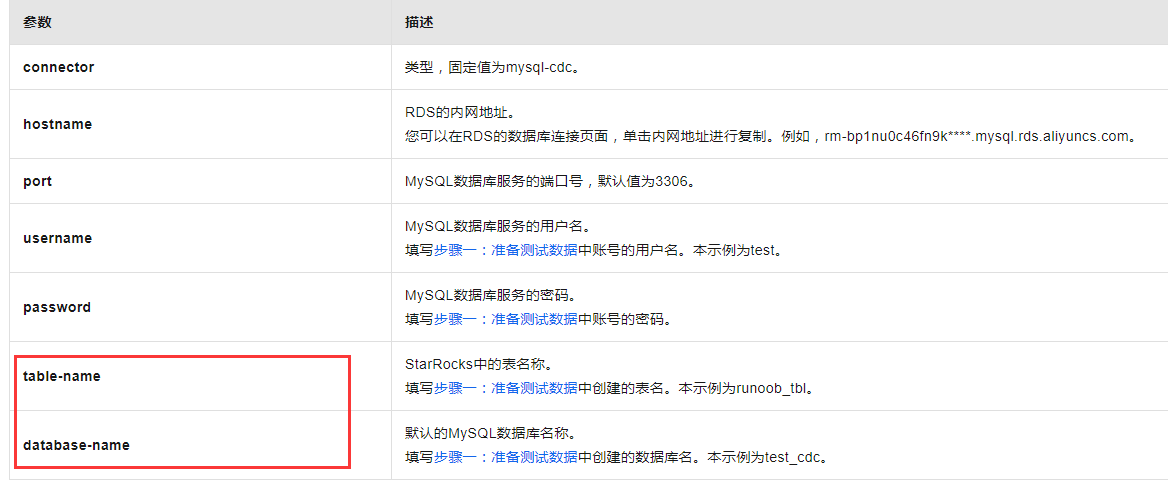
Flink的CTAS(Create Table As Select)操作主要用于创建一个新的表,其结构与指定的查询结果相同。要将您提到的三个字段(元数据key、database name、table name、op ts、元数据类型)同步到新表中,您可以在CTAS语句中使用相应的字段作为新表的列。
假设您有一个元数据表,其中包含这些字段,您可以使用以下CTAS语句创建一个新表:
CREATE TABLE new_table AS
SELECT
metadata_key,
database_name,
table_name,
op_ts,
metadata_type
FROM
metadata_table;
请根据您的实际情况替换metadata_table和new_table为您的表名。如果需要,您还可以添加其他列,以便在新表中包含所需的所有信息。
如果您需要将多个查询的结果合并到同一个新表中,可以使用UNION ALL将它们连接起来:
CREATE TABLE new_table AS
SELECT
metadata_key,
database_name,
table_name,
op_ts,
metadata_type
FROM
metadata_table
UNION ALL
SELECT
other_metadata_key,
other_database_name,
other_table_name,
other_op_ts,
other_metadata_type
FROM
other_metadata_table;
请根据您的实际情况替换metadata_table、other_metadata_table和new_table为您的表名。
根据您提供的元数据表结构,似乎并没有明确提到与这三个字段相关联的列或字段。不过,您可以考虑创建一个新的视图或 UDF (用户自定义函数) 将这些额外字段添加到您的原始表中。
假设您想要为每条变更记录追加新的字段,一种方法是利用窗口函数对历史变更记录进行分组并在每一组内计算平均值。这里我们将展示一个基本示例,但请注意将其适应于您的具体情况:
CREATE VIEW table_with_extra_fields AS
WITH latest_record AS (
SELECT database_name, table_name, op_ts, MAX(op_ts) OVER (PARTITION BY database_name, table_name)
FROM history_table
),
grouped_records AS (
SELECT database_name, table_name, op_ts, row_number() OVER (PARTITION BY database_name, table_name ORDER BY op_ts DESC) as rn
FROM latest_record
)
SELECT h.database_name, h.table_name, h.op_ts, g.row_num, AVG(h.op_ts - g.op_ts) over(partition by h.database_name, h.table_name order by h.database_name, h.table_name desc rows between unbounded preceding and current row) as avg_age
FROM grouped_records g JOIN latest_record h ON g.database_name = h.database_name AND g.table_name = h.table_name AND g.rn <= h.rn
ORDER BY database_name, table_name, op_ts;
这段代码会生成一个新的视图 table_with_extra_fields ,其中包含原表的历史变更记录以及新增字段 avg_age 。此字段代表了当前记录相对于最近一次相同变更的时间间隔(单位为秒),即两个相邻变更之间的平均时间差。
上述示例仅适用于特定场景下,且并未考虑到其他复杂条件下的合并策略。在实践中,您可能需要针对不同的应用场景设计更加复杂的逻辑。在某些情况下,您可能希望避免频繁更改表结构,而是选择保留现有表不变并通过其他方式获得所需的附加信息。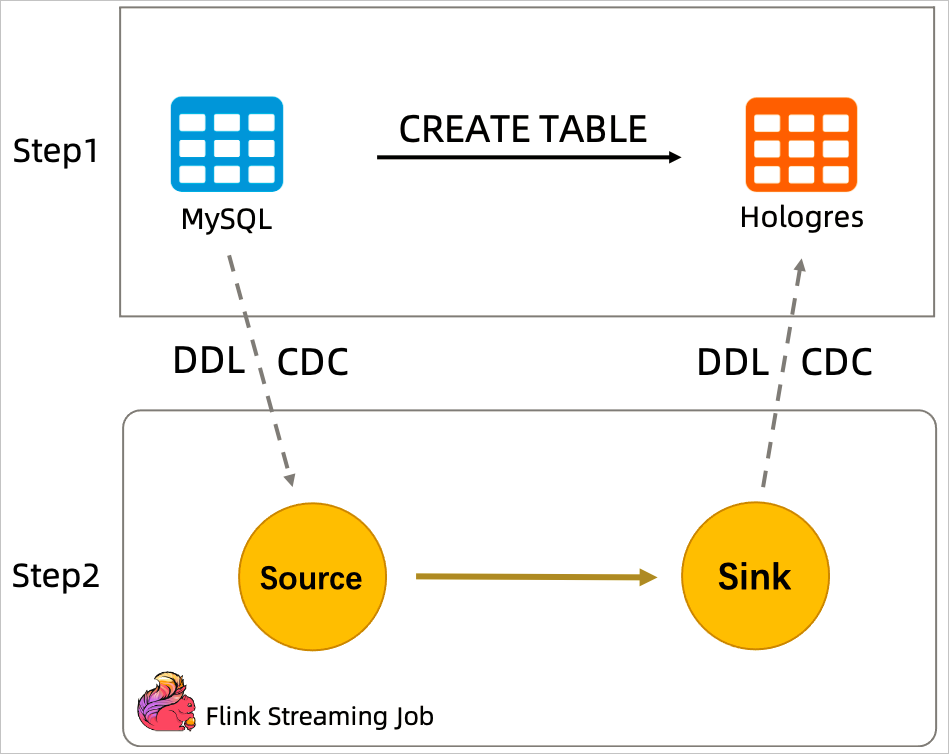
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。