回答1:就是普通的csv,比如字段: text,label 每一条的输出就是 {'text': xxx, 'label': xxx ,可以print(next(iter(train_dataset)))查看,一般label这些在preprocessor中指定。可以先查看一下模型卡片上提供的数据集格式,后面用自己的数据集微调。 回答2:无回答 回答3:无回答 回答4:csv文件本身是逗号分隔文件,因此只要符合逗号分隔,值是什么都可以,加载出来的就是一个dataset 回答 5: 参考链接:https://modelscope.cn/datasets/modelscope/Libri2Mix_8k/dataPeview ,这个是输入数据集的格式 具体介绍在这里:https://modelscope.cn/datasets/modelscope/Libri2Mix_8k/summary 回答 6:您从.to_torch_dataset那里拆开查看比较方便,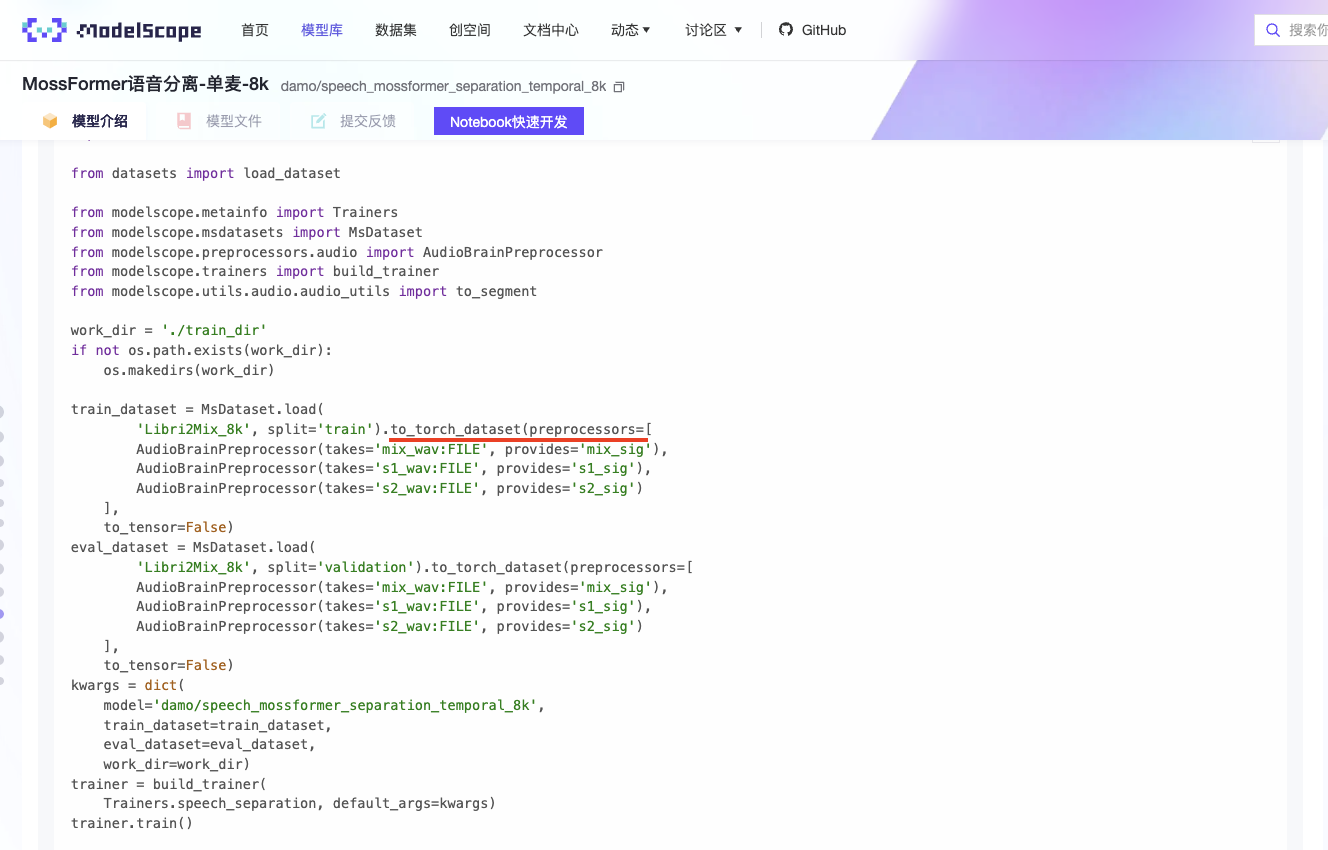 ,原csv文件读取后应该是这样的:{'id': '1578-6379-0038_6415-111615-0009', 'mix_wav:FILE': '/root/.cache/modelscope/hub/datasets/modelscope/Libri2Mix_8k/master/data_files/extracted/e48c3496515ca52ec330f35de7450b5905206d3ecc58a52450b9a07005d8b335/train/mix_clean/1578-6379-0038_6415-111615-0009.wav', 's1_wav:FILE': '/root/.cache/modelscope/hub/datasets/modelscope/Libri2Mix_8k/master/data_files/extracted/e48c3496515ca52ec330f35de7450b5905206d3ecc58a52450b9a07005d8b335/train/s1/1578-6379-0038_6415-111615-0009.wav', 's2_wav:FILE': '/root/.cache/modelscope/hub/datasets/modelscope/Libri2Mix_8k/master/data_files/extracted/e48c3496515ca52ec330f35de7450b5905206d3ecc58a52450b9a07005d8b335/train/s2/1578-6379-0038_6415-111615-0009.wav', 'length': 53560.0}。数据集页面上也可以查看
,原csv文件读取后应该是这样的:{'id': '1578-6379-0038_6415-111615-0009', 'mix_wav:FILE': '/root/.cache/modelscope/hub/datasets/modelscope/Libri2Mix_8k/master/data_files/extracted/e48c3496515ca52ec330f35de7450b5905206d3ecc58a52450b9a07005d8b335/train/mix_clean/1578-6379-0038_6415-111615-0009.wav', 's1_wav:FILE': '/root/.cache/modelscope/hub/datasets/modelscope/Libri2Mix_8k/master/data_files/extracted/e48c3496515ca52ec330f35de7450b5905206d3ecc58a52450b9a07005d8b335/train/s1/1578-6379-0038_6415-111615-0009.wav', 's2_wav:FILE': '/root/.cache/modelscope/hub/datasets/modelscope/Libri2Mix_8k/master/data_files/extracted/e48c3496515ca52ec330f35de7450b5905206d3ecc58a52450b9a07005d8b335/train/s2/1578-6379-0038_6415-111615-0009.wav', 'length': 53560.0}。数据集页面上也可以查看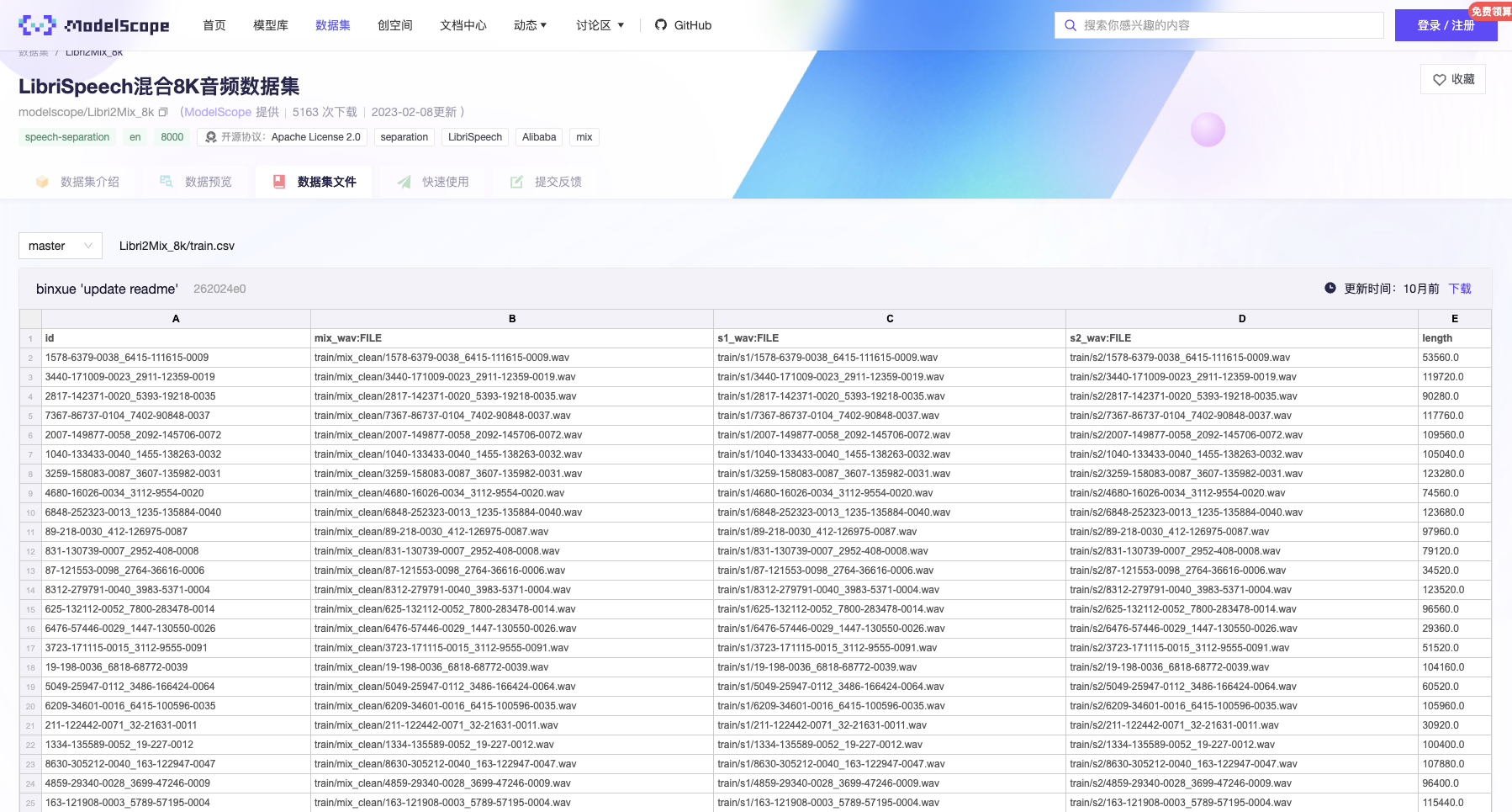 。如果想传到 modelscope 上,再加载,也可以参考这个最佳实践: https://modelscope.cn/docs/%E3%80%90%E7%A4%BA%E4%BE%8B%E3%80%91%E6%95%B0%E6%8D%AE%E9%9B%86%E6%89%98%E7%AE%A1%E5%88%B0ModelScope ,正好也是音频相关的。参考链接:https://modelscope.cn/docs/%E3%80%90%E7%A4%BA%E4%B...88%B0ModelScope 此回答整理自钉群 “魔搭ModelScope开发者联盟群 ①”
。如果想传到 modelscope 上,再加载,也可以参考这个最佳实践: https://modelscope.cn/docs/%E3%80%90%E7%A4%BA%E4%BE%8B%E3%80%91%E6%95%B0%E6%8D%AE%E9%9B%86%E6%89%98%E7%AE%A1%E5%88%B0ModelScope ,正好也是音频相关的。参考链接:https://modelscope.cn/docs/%E3%80%90%E7%A4%BA%E4%B...88%B0ModelScope 此回答整理自钉群 “魔搭ModelScope开发者联盟群 ①”