
ModelScope的swift训练的时候loss下不来 怎么办,需要降低学习率吗?参考sft.sh, qwen_7b_chat ,sft是example里面的,没改过 # Experimental environment: V100, A10, 3090
PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0 \
python llm_sft.py \
--model_id_or_path qwen/Qwen-7B-Chat \
--model_revision master \
--sft_type lora \
--tuner_backend swift \
--template_type chatml \
--dtype AUTO \
--output_dir output \
--dataset blossom-math-zh \
--train_dataset_sample -1 \
--num_train_epochs 1 \
--max_length 2048 \
--check_dataset_strategy warning \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0.05 \
--lora_target_modules DEFAULT \
--gradient_checkpointing true \
--batch_size 1 \
--weight_decay 0.01 \
--learning_rate 1e-4 \
--gradient_accumulation_steps 16 \
--max_grad_norm 0.5 \
--warmup_ratio 0.03 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 10 \
--use_flash_attn false \
--push_to_hub false \
--hub_model_id qwen-7b-chat-lora \
--hub_private_repo true \
--hub_token 'your-sdk-token' \
看你的命令行的输出,发个文件给我。--lora_target_modules DEFAULT E\ 改成 --lora_target_modules ALL \ 试试,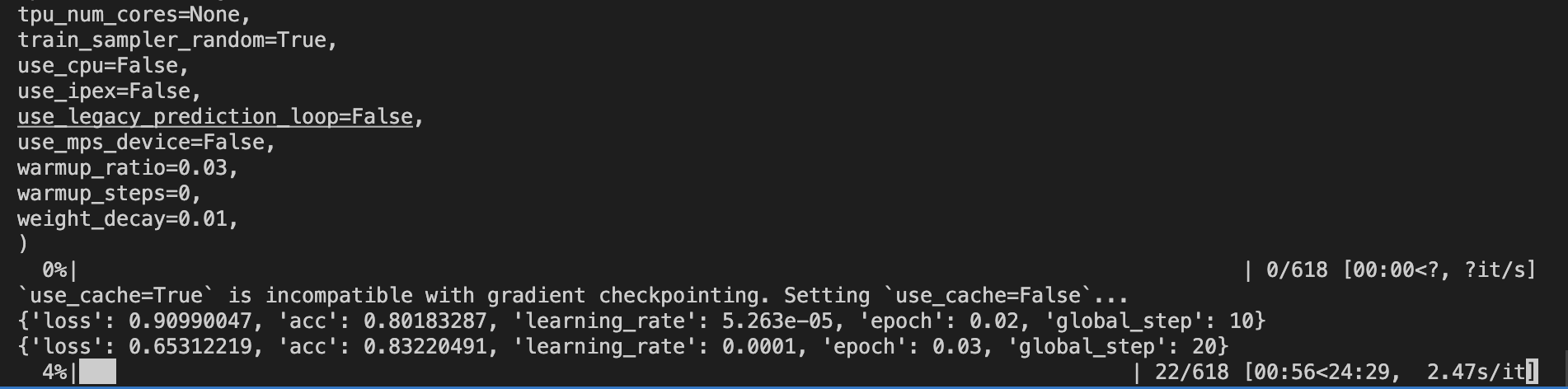 此回答整理自钉群 “魔搭ModelScope开发者联盟群 ①”
此回答整理自钉群 “魔搭ModelScope开发者联盟群 ①”
