
"NLP自学习平台中怎么这里选不了?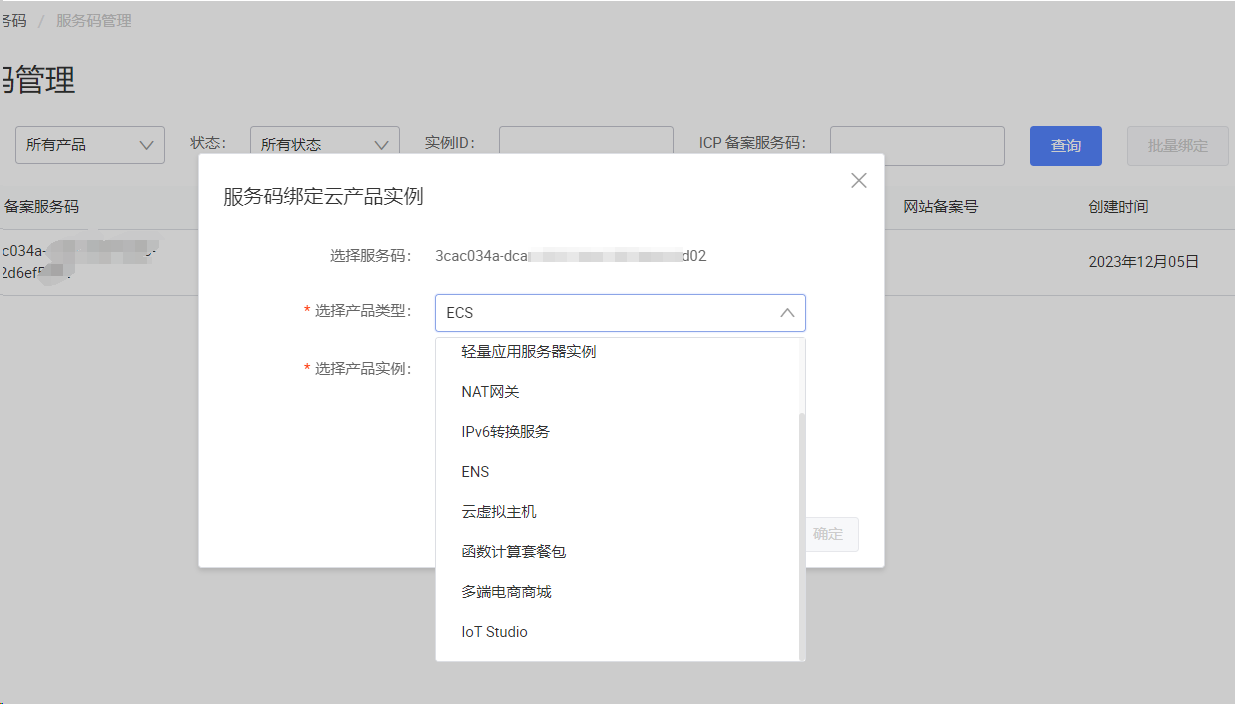 "
"
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您的问题提到“NLP自学习平台中怎么这里选不了?”,但未具体说明是哪个功能或选项无法选择。根据知识库中的信息,我将从几个可能的场景进行详细解答,帮助您定位问题并解决。
在NLP自学习平台中,如果您在创建模型时发现某些模型类型无法选择,可能是以下原因导致: - 数据格式不符合要求:不同模型对输入数据的格式有特定要求。例如,实体抽取模型需要JSON格式的数据。如果上传的数据格式不正确(如非JSON格式或超出20M大小限制),可能导致模型类型不可用。 - 数据标注不完整:对于多层级标签体系,如果标注路径不完整(如部分数据缺少从根节点到叶子节点的完整标签),可能会影响模型的选择。
解决方法: - 检查数据集是否符合JSON格式,并确保数据大小不超过20M。 - 确保标注数据完整,尤其是多层级标签的路径是否正确。
如果您在分词时尝试自定义停用词但无法生效,可能是因为: - 未正确加载停用词文件:在使用工具(如jieba)时,需要明确指定停用词文件路径。如果路径错误或文件格式不符合要求,停用词设置将无效。 - 平台不支持自定义停用词:部分NLP平台可能不支持用户自定义停用词功能,需确认当前使用的平台是否支持该功能。
解决方法: - 确认停用词文件路径是否正确,并检查文件格式是否为纯文本。 - 如果平台不支持自定义停用词,可以考虑使用其他支持该功能的工具(如Python的jieba或spaCy)。
如果您在尝试私有化部署时发现某些选项不可用,可能的原因包括: - 未加入相关咨询群:私有化部署的具体方案和报价需要通过钉钉群(群号:44619071)咨询获取。如果未加入群组,可能无法查看完整的选项。 - 权限不足:子账号可能未被授权访问私有化部署的相关功能。
解决方法: - 加入“阿里云NLP自学习平台用户答疑二群”(钉钉群号:44619071)以获取详细方案。 - 确认当前账号是否具有足够的权限,必要时联系主账号管理员进行授权。
在模型训练过程中,如果您发现某些参数(如遍历次数、学习速率)无法调整,可能是因为: - 默认参数限制:平台内置了earlystop功能,当模型效果连续三次未提升时会自动停止训练,即使设置了较高的遍历次数也可能提前终止。 - 高级设置未开启:部分参数调整需要在高级设置中启用。
解决方法: - 检查是否启用了高级设置,并根据需求调整遍历次数和学习速率。 - 如果希望快速验证模型效果,可以先使用小规模数据进行训练。
在模型测试阶段,如果您发现无法输入特定字段(如content或labels),可能是因为: - 输入格式错误:测试输入必须为JSON格式,且content字段为必填项。如果同时输入labels,其值必须为列表格式。 - 字段名称拼写错误:JSON字段名称区分大小写,拼写错误会导致无法识别。
解决方法: - 确保输入为JSON格式,并检查字段名称是否正确。 - 示例输入格式如下:
{
"content": "亨利·希姆斯(Henry Sims),1990年3月27日出生于美国马里兰州巴尔的摩( Baltimore, MD),美国职业篮球运动员,司职中锋,效力于NBA费城76人队",
"labels": ["人物", "组织机构", "日期", "地理位置", "数量"]
}
如果上述内容仍未解决您的问题,请提供更具体的描述(如无法选择的功能名称、操作步骤等),以便我们进一步为您排查问题。同时,您可以参考知识库中的相关文档,确保操作符合平台要求。
