
基于X-Engine引擎的历史订单数据库方案:历史库存储引擎切换为X-Engine,保存超过90天的所有交易订单数据,超过90天的订单读写,直接操作历史库。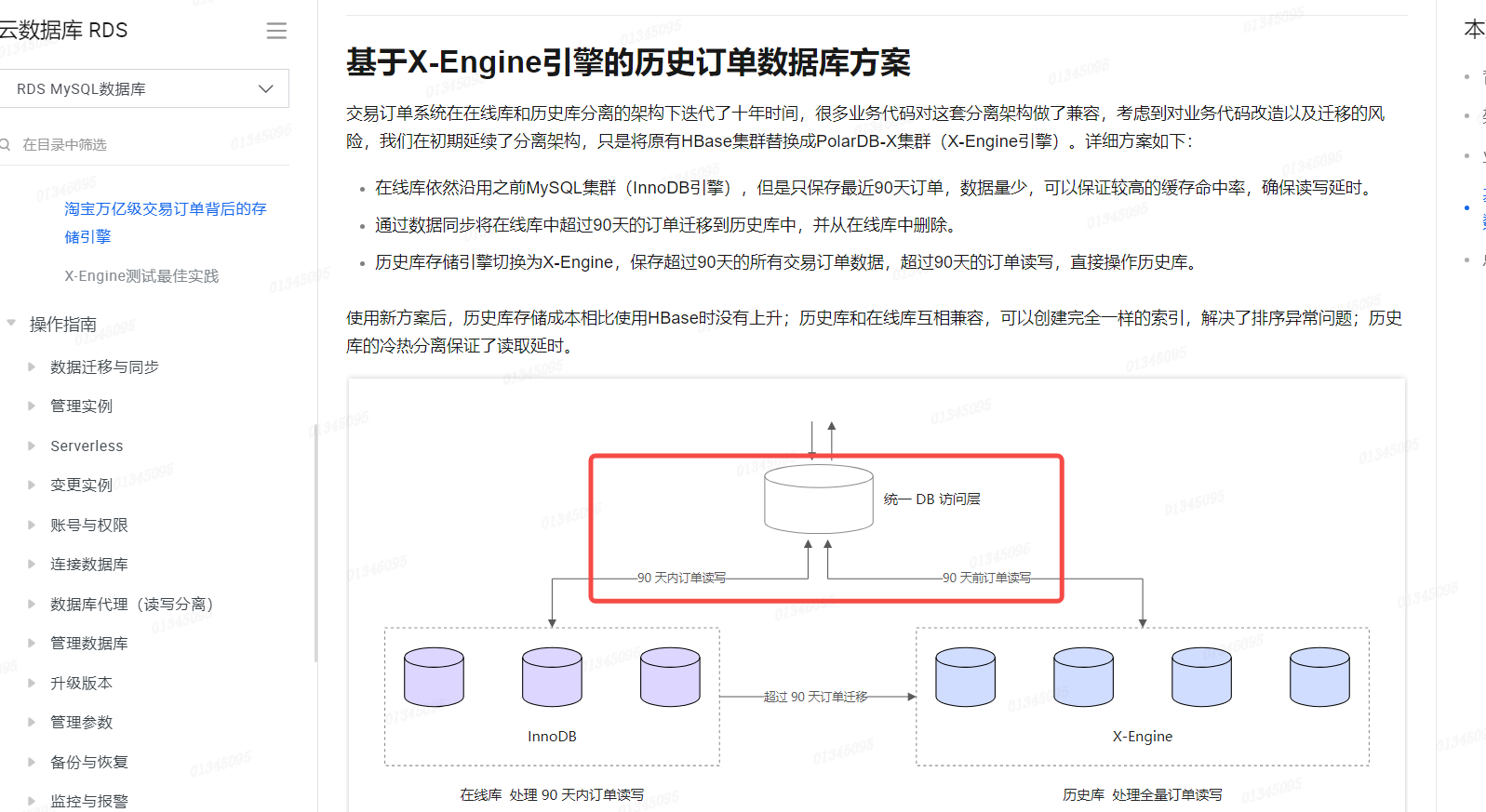
统一DB访问层 是如何实现,90天内订单读写在线库,90天前订单读写历史库的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
统一DB访问层可以通过以下方式实现:
使用读写分离策略,将90天内的订单数据存储在在线库中,90天前的数据存储在历史库中。这样,当需要读取或写入订单数据时,可以根据时间范围选择相应的数据库进行操作。
使用分布式缓存系统(如Redis)来缓存最近90天内的订单数据。当需要读取订单数据时,首先从缓存中获取,如果缓存中没有数据或者数据已过期,则从在线库中查询并更新缓存。
对于超过90天的订单数据,可以使用X-Engine引擎的历史订单数据库方案。将历史库存储引擎切换为X-Engine,保存超过90天的所有交易订单数据。当需要读取或写入超过90天的订单数据时,直接操作历史库。
以下是一个简单的示例代码:
import datetime
import pymysql
from redis import StrictRedis
# 连接在线库和历史库
online_db = pymysql.connect(host='online_db_host', user='user', password='password', db='db')
history_db = pymysql.connect(host='history_db_host', user='user', password='password', db='db')
# 连接Redis缓存
redis_client = StrictRedis(host='redis_host', port=6379, db=0)
def get_order_data(order_id):
# 尝试从缓存中获取订单数据
order_data = redis_client.get(f'order_{order_id}')
if order_data:
return order_data
# 如果缓存中没有数据,从在线库中查询
with online_db.cursor() as cursor:
sql = f"SELECT * FROM orders WHERE id = {order_id}"
cursor.execute(sql)
order_data = cursor.fetchone()
# 如果在线库中也没有数据,从历史库中查询
if not order_data:
with history_db.cursor() as cursor:
sql = f"SELECT * FROM orders WHERE id = {order_id}"
cursor.execute(sql)
order_data = cursor.fetchone()
# 将查询到的订单数据存入缓存,设置过期时间为90天
if order_data:
redis_client.setex(f'order_{order_id}', 90 * 24 * 60 * 60, order_data)
return order_data
def update_order_data(order_id, new_data):
# 更新在线库中的订单数据
with online_db.cursor() as cursor:
sql = f"UPDATE orders SET data = '{new_data}' WHERE id = {order_id}"
cursor.execute(sql)
online_db.commit()
# 更新历史库中的订单数据(如果需要)
with history_db.cursor() as cursor:
sql = f"UPDATE orders SET data = '{new_data}' WHERE id = {order_id}"
cursor.execute(sql)
history_db.commit()
# 更新Redis缓存中的订单数据
redis_client.setex(f'order_{order_id}', 90 * 24 * 60 * 60, new_data)
这个示例代码展示了如何使用Python连接到在线库、历史库和Redis缓存,以及如何根据订单ID获取和更新订单数据。在实际项目中,还需要考虑事务处理、错误处理等细节。


