
大数据计算MaxCompute看起来好像又不是,单个都是1分钟多,他们不是完全并行的?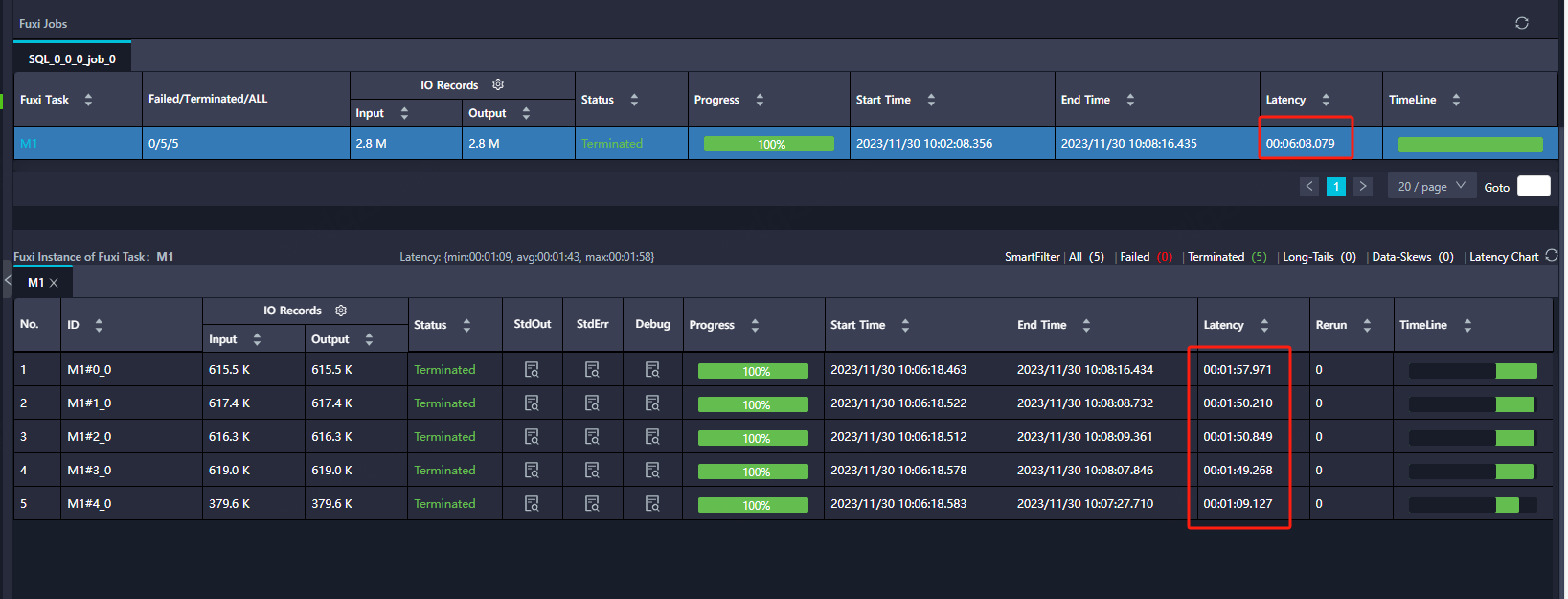
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在MaxCompute中,如果一个任务被分成了多个子任务(也称为Instance),那么这些子任务是并行执行的。也就是说,它们会同时开始读取数据,同时进行计算,最后同时完成。
然而,这并不意味着它们的执行速度是一样的。因为每个子任务处理的数据量可能不同,或者每个子任务的计算复杂度可能不同,所以它们的执行时间可能会有所不同。
在MaxCompute中,任务(Task)是其基本计算单元,所有的SQL和MapReduce功能都是通过任务来完成的。每个任务在被提交后,MaxCompute会对其进行解析以生成任务的执行计划。
尽管MaxCompute的设计初衷是为了实现并行处理以提高运算效率,但在实际运行中,由于存在任务间的依赖关系,因此并不是所有任务都能完全并行执行。一个任务的开始运行可能需要等待其依赖的任务先运行完成。这种任务间的依赖性可能会影响到整体的执行效率,使得单个任务的执行时间增加。
此外,根据实际生产项目的经验,即使是计算量较大的任务,其执行时间(包括等待时间和真正运行时间)通常也不会超过1个小时。对于使用spark等类型的作业,如果一个job启动时间较长,也是正常现象。
总的来说,虽然MaxCompute设计上支持并行处理,但由于任务间的依赖关系和特定任务类型的特性,可能会导致单个任务的执行时间超过预期。同时,也需要注意监控和管理任务的状态,以确保任务能够顺利执行并及时获取任务的执行进度。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


