
Hologres之前用的ttl来管理生命周期的,建议用了动态分区管理,降低了数据写入压力,对于大表按主键+时间+group by的这种时间范围聚合查询的场景,应该怎么同时保证读写高并发性能?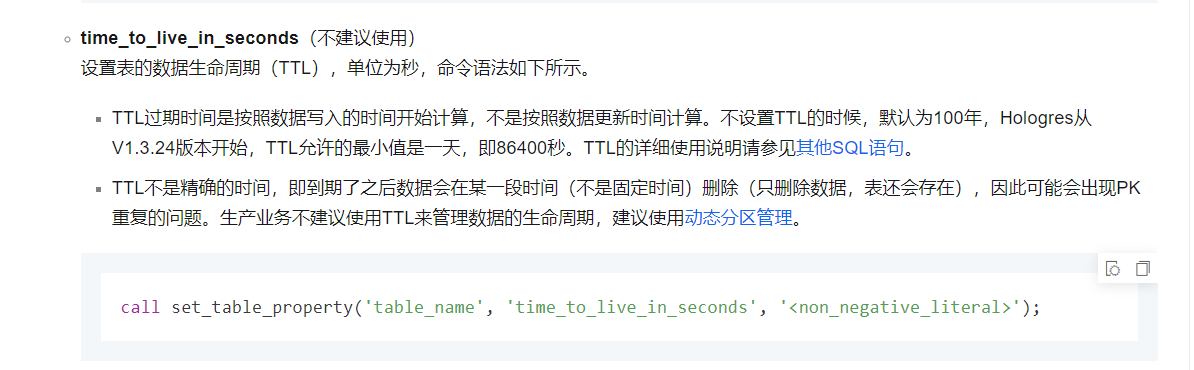
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
对于大表按主键+时间+group by的这种时间范围聚合查询的场景,建议采用以下方法来保证读写高并发性能:
使用动态分区管理:通过动态分区管理,可以自动根据数据量和查询需求进行分区,避免手动分区带来的问题。同时,动态分区管理还可以降低数据写入压力,提高系统性能。
使用分布式缓存:可以使用分布式缓存来缓存热点数据,减少对数据库的访问压力。例如,可以使用Redis等开源缓存框架来实现。
使用读写分离:可以将读请求和写请求分离到不同的数据库节点上,从而提高系统的并发性能。例如,可以使用MySQL的主从复制架构来实现读写分离。
使用索引优化查询:可以为查询中的主键、时间和分组字段创建索引,以提高查询效率。同时,还可以使用覆盖索引等技术来进一步优化查询性能。
使用负载均衡:可以使用负载均衡技术来平衡系统负载,避免某个节点过载导致系统性能下降。例如,可以使用Nginx等开源负载均衡器来实现。
对于大表按主键+时间+group by的时间范围聚合查询场景,您可以考虑以下方法来保证读写高并发性能:
动态分区优化:使用动态分区管理,将数据按照时间进行分区,可以提高查询性能。确保在查询语句中充分利用分区键和相关索引,以减少扫描的数据量。
分布式架构:如果数据规模非常大,可以考虑使用Hologres的分布式架构。通过水平拆分数据到多个节点上,可以提升并行处理能力和查询性能。
适当调整资源配置:根据实际的读写负载情况,合理配置Hologres实例的计算和存储资源。增加实例规格、调整连接池大小等操作,可以提高并发处理能力。
优化查询语句:仔细设计和优化查询语句,包括选择合适的索引、避免不必要的全表扫描、合理使用聚合函数等。考虑使用预聚合技术,将一些计算提前进行,并将结果缓存起来,以减少查询时的计算开销。
数据压缩和归档:对于历史数据,可以进行数据压缩和归档,将不经常访问的数据移至冷数据存储,从而减少热数据查询时的负载。
并发控制和事务管理:合理设置并发控制策略,考虑使用合适的事务隔离级别,以保证读写操作的一致性和并发性能。
数据缓存和预热:利用缓存技术,如Redis等,对经常访问的数据进行缓存,在查询时可以先从缓存中获取数据,减少对数据库的实际访问。同时,根据访问模式,可以进行数据预热,将频繁访问的数据加载到缓存中,提高查询响应速度。
在Hologres中,针对大表按主键+时间+GROUP BY的时间范围聚合查询的场景,同时保证读写高并发性能,可以采取以下策略:
动态分区管理:
Shard数设置:
索引优化:
资源隔离:
并行处理:
内存管理:
查询优化:
监控与调优:
数据生命周期管理:
定期备份与恢复:
Hologres是阿里云自研的兼容PostgreSQL协议的一站式实时数仓引擎,它支持海量数据的实时写入、更新和分析。为了实现高并发性能,Hologres在存储时将物理表分成多个Shard,这些Shard会按照一定的分布方式存储在所有的物理节点上。每个Shard可以并发进行查询,因此Shard数量越多,整个查询的并发度也就越高。
然而,Shard的数量并不是越多越好,因为更多的Shard会带来额外的开销。因此,在确定每个表的Shard数量时,需要综合考虑查表的数据量和查询的复杂度。此外,为了进一步优化性能,可以考虑使用分布式查询引擎,如MaxCompute,这种技术可以显著加速查询并实现亚秒级的响应时间。
本技术圈将为大家分析有关阿里云产品Hologres的最新产品动态、技术解读等,也欢迎大家加入钉钉群--实时数仓Hologres交流群32314975


