
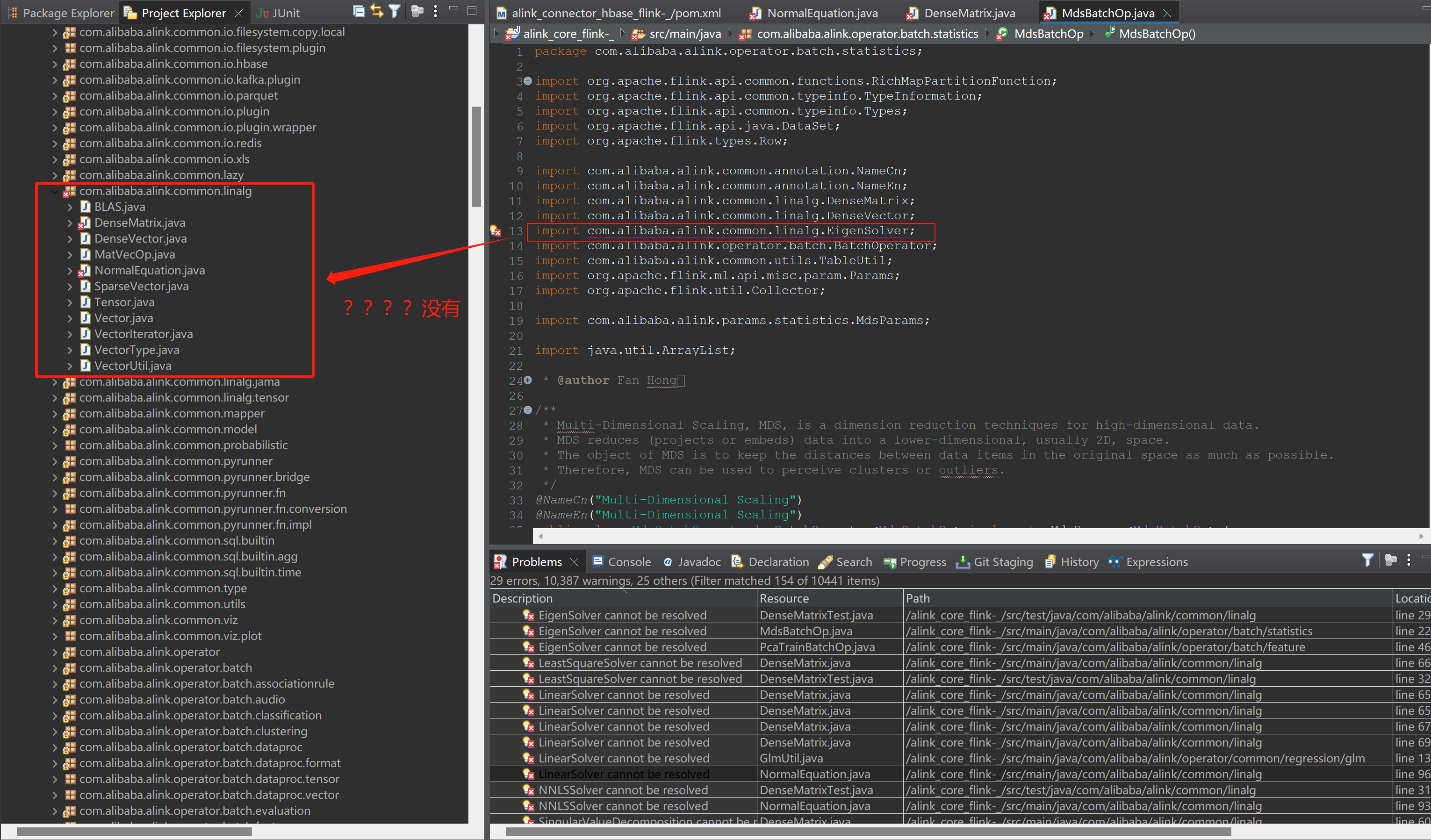
如下请问机器学习PAI的这些问题怎么解决?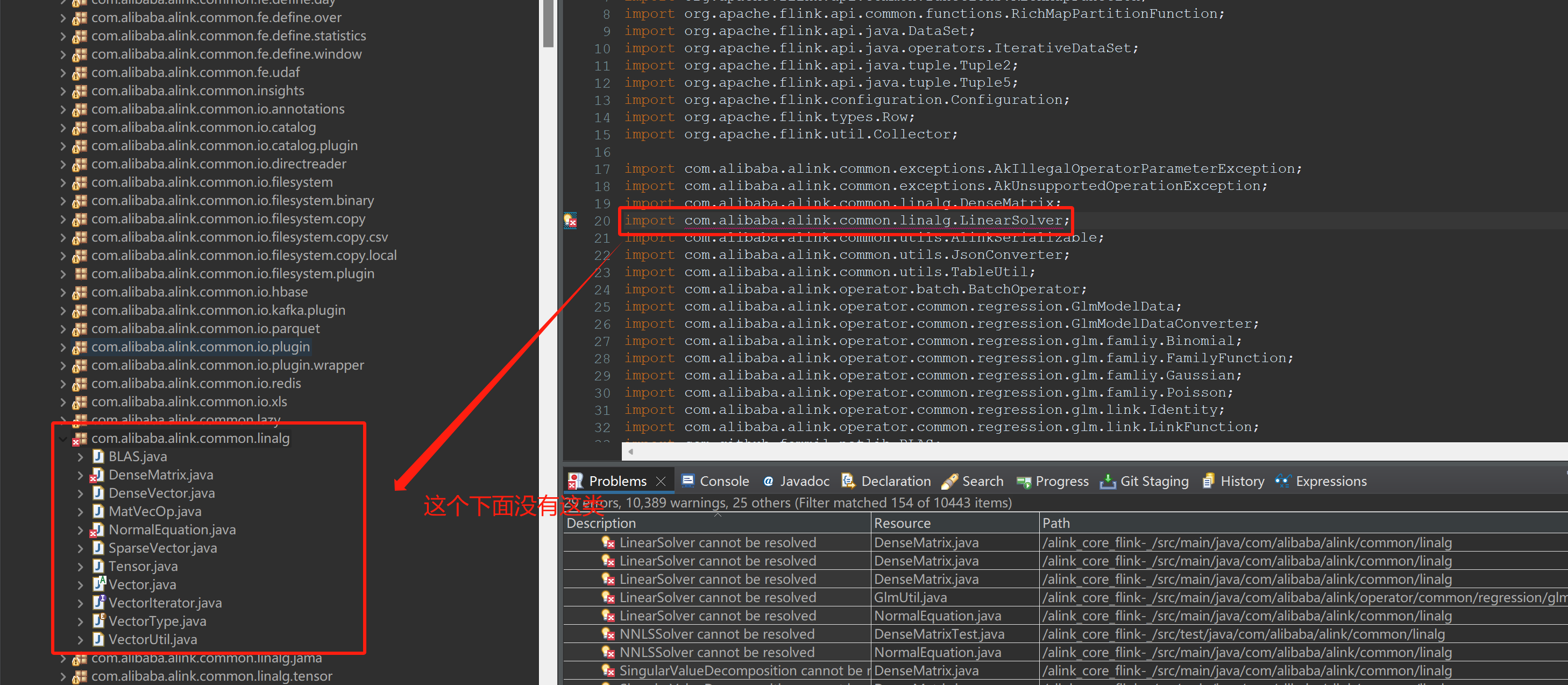
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
解决方案:
EAS推荐使用Docker镜像来上传运行环境和大文件。当业务代码发生变化时,只需增量更新改动部分,这可以显著提升开发效率。具体操作步骤如下:
1. 将运行环境和依赖打包为Docker镜像。 2. 仅上传修改后的代码或配置文件,避免重复上传整个压缩包。
cv2报错 libSM.so.6: cannot open shared object file: No such file or directory,如何解决?解决方案:
此错误通常是因为EAS线上环境未预装必要的库文件。可以通过以下两种方法之一解决:
1. 安装无依赖版本的cv2:
使用命令 pip install opencv-python-headless 安装不依赖额外库文件的cv2版本。 2. 手动添加缺失的库文件:
- 将系统中已安装的libXext、libSM和libXrender库文件拷贝至ENV/lib目录。 - 随Processor上传这些库文件。
param invalid UserNotInTnt,如何处理?解决方案:
该问题通常是由于权限配置不当导致的。可以尝试以下操作:
1. 设置管理员权限:
- 在工作空间中设置管理员账号。 - 在iTag的人员管理页面,将对应的RAM账号设置为管理员。 2. 检查子账号权限:
如果iTag是由其他子账号创建的,可以让对应的子账号将主账号添加到权限列表中。 3. 重新创建工作空间:
如果AI工作空间时间较久,建议创建一个新的AI工作空间以使用iTag功能。 4. 参考授权文档:
更多授权操作可参见为PAI-iTAG授权的相关文档。
解决方案:
该问题可能是因为探索者版DSW实例需要天池侧的实名认证。解决方法如下:
1. 跳转至天池完成认证:
根据提示,跳转到天池平台完成实名认证。 2. 申诉解决风控问题:
如果账号触发了风控机制,需通过申诉解决。申诉时需提供账号持有人手持证件的照片。
解决方案:
数据读取本身没有限制,但预览功能默认只显示100条数据。如果需要查看更多数据,可以按照以下步骤操作:
1. 使用SQL脚本筛选数据:
连接一个SQL脚本节点,通过SELECT语句筛选出关心的数据进行预览。 2. 了解SQL脚本用法:
单击SQL脚本组件以了解更多使用细节。
解决方案:
上采样可以通过以下两种方式实现:
1. 分层采样(StratifiedSample):
使用分层采样组件完成上采样操作,详情可参考分层采样的相关文档。 2. 自定义Python组件:
利用自定义Python组件实现上采样逻辑,参考文档中的使用实例1。
解决方案:
doc2vec组件无法直接预测新向量。建议使用以下替代方案:
1. 结合word2vec和docvecFromWordVec:
使用PyAlink中的word2vec生成词向量,再通过docvecFromWordVec生成文档向量。 2. 参考详细文档:
具体实现方法可参考相关文档说明。
解决方案:
在PAI Designer中,节点结果数据可能保存在MaxCompute表或OSS路径中。下游节点可以通过连线的方式从对应的存储位置读取数据。具体操作如下:
1. 确认数据存储位置:
- 如果数据存储在MaxCompute表中,下游节点可以直接连接并读取。 - 如果数据存储在OSS路径中,确保下游节点配置了正确的OSS路径。 2. 连线传递数据:
通过连线的方式将上游节点的结果数据传递给下游节点。
FAILED: ODPS-1220061: Invalid parameter in HTTP request - xflow not found,如何解决?解决方案:
该问题通常是由于project参数未正确设置导致的。解决方法如下:
1. 设置固定值algo_public:
在调用PAI命令时,将project参数设置为固定值algo_public。 2. 检查其他参数配置:
确保其他参数配置正确,避免因参数错误导致调用失败。
以上是针对您提出的问题的详细解答。如有进一步疑问,请随时补充说明!
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。

