
机器学习PAI报一个问题:我DSSM负采样版本,user tower输入两个特征:gender(F, M, UNKNOWN,共3种)与age_level([1, 17], [18, 24], ..., UNKOWN,共11种),item tower一个特征:item_id。我们输入数据都提前补好了缺失值,gender的hash_bucket_size设的200(unique value有3个),age_level的hash_bucket_size设为300。我们预期上user tower产生33种不同的user embedding,但是实际上有一些样本attr被hash到同一个bucket里去了,只有30种不同的user embedding,导致他们虽然feature不同但是embedding相同,请问这个问题咱们有碰到过吗?
看上图,gender一样age_level不一样,但是embedding一样,看起来是age_level被hash到同一个bucket了
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
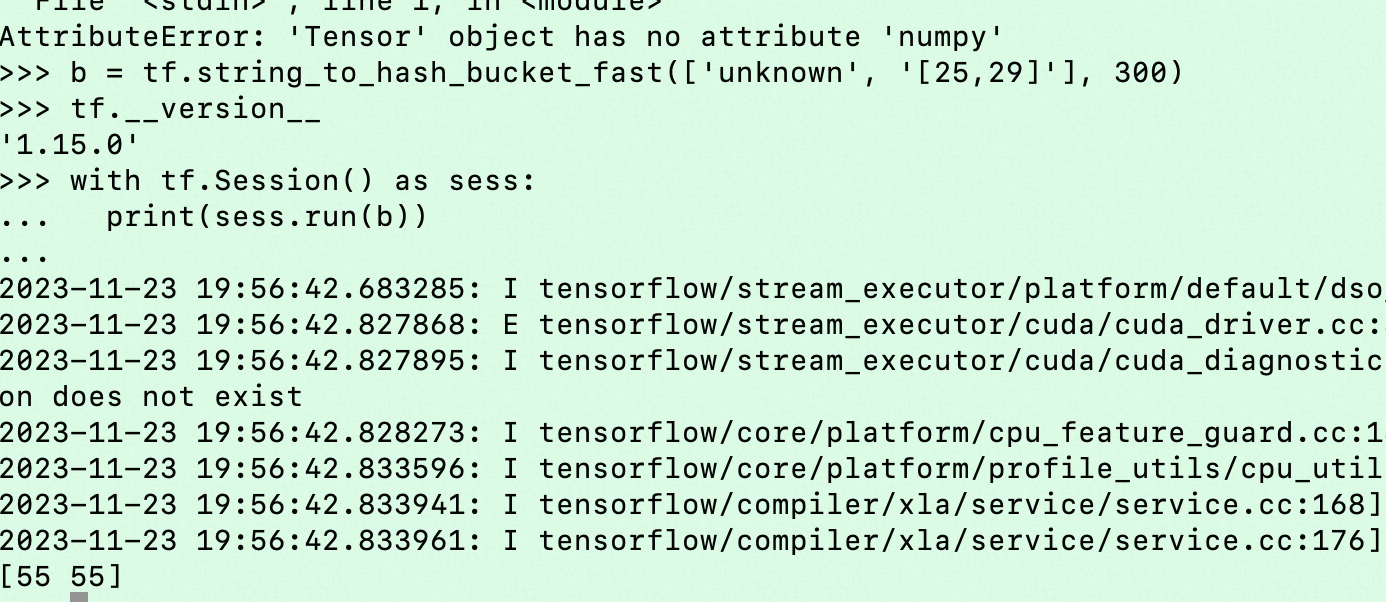
确实是一样的,这种取值有限的,要么用个vocab_dict或者EmbeddingVariable好了 可以防止冲突,或者干脆设置的大一些,比如1000
这说明,大多数未知年龄的,都把他当做25-29 的年龄来处理(应该出现概率高)。看起来也有道理啊,此回答整理自钉群“【EasyRec】推荐算法交流群”
您在机器学习PAI中遇到的这个问题,是因为使用了相同的hash函数和哈希桶大小对不同的特征进行了哈希处理。在这种情况下,即使输入数据不同,但它们可能被哈希到同一个桶里,导致生成的embedding相同。
为了解决这个问题,您可以尝试以下方法:
增大hash_bucket_size:
hash_bucket_size值,确保每个特征都有足够的空间来分散其哈希结果。使用独立的哈希函数或参数:
使用多层哈希:
使用其他编码方式:
调整特征组合:
检查代码实现:
检查数据集和特征设置是否合理,并确保模型在训练过程中没有发生过拟合的情况。
同时,您可以尝试调整特征的hash_bucket_size来增加不同特征的区分度,从而避免相似特征被哈希到同一个bucket中。训练模型文档可以参考这个:https://help.aliyun.com/zh/pai/user-guide/xgboost-train
---来自XGBoost训练文档
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。


