
业务背景:有一批百亿级别的数据需要同步从mongo同步到doris,存量+增量都要同步,所以想使用CDC同步,但是发现速率太慢,目前QPS 2w,预计300亿要同步20天左右才能跑完。
UI上看到QPS在2万左右,并且source的并行度一直是1。请问如何提高source的并行度?以及并行度的提升是否有助于提升消费速率?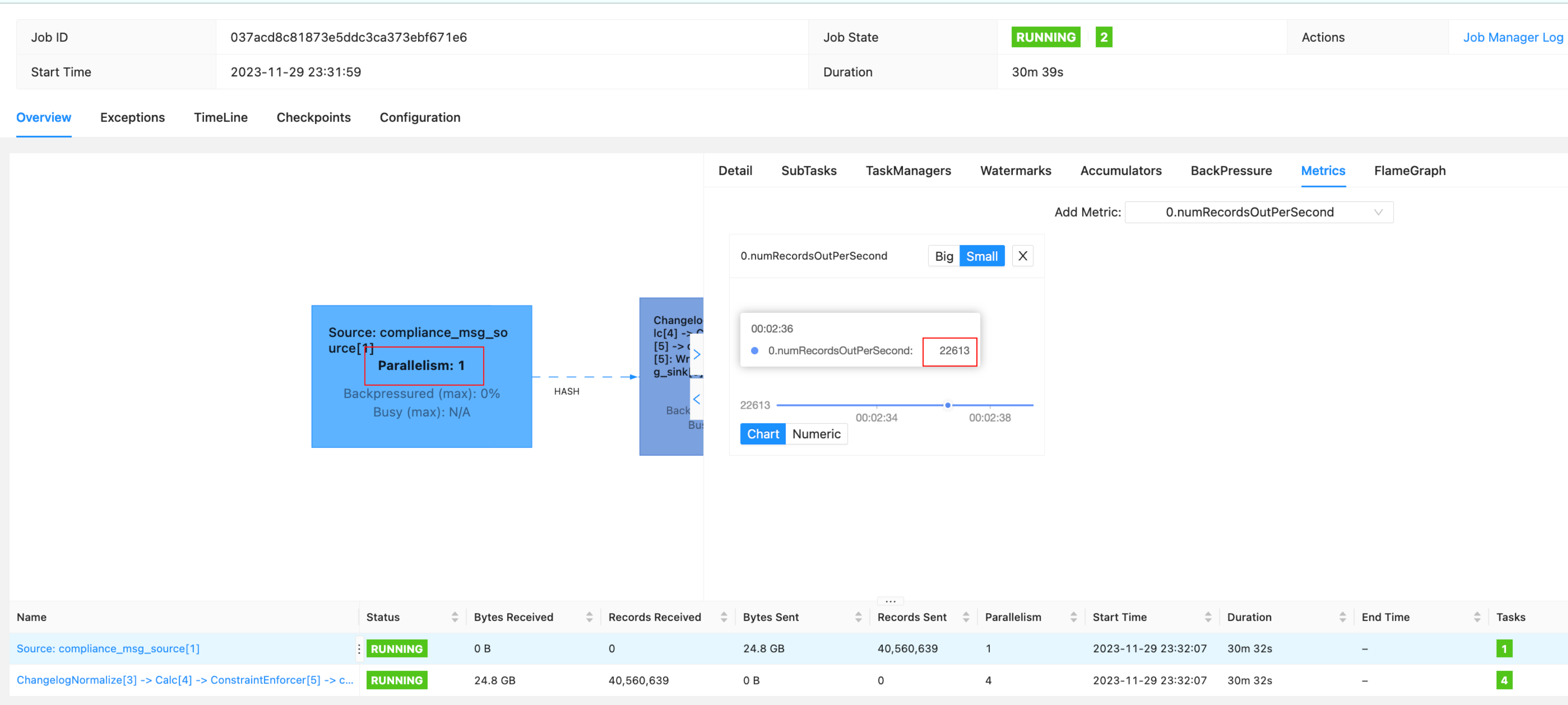
sql 的 source table 配置如下,这里在CDC文档中没有找到可以配置source并行度的地方。提高了拉数据的batch size。发现对source的QPS没有提升效果。
flink.conf文件中的默认并行度配置如下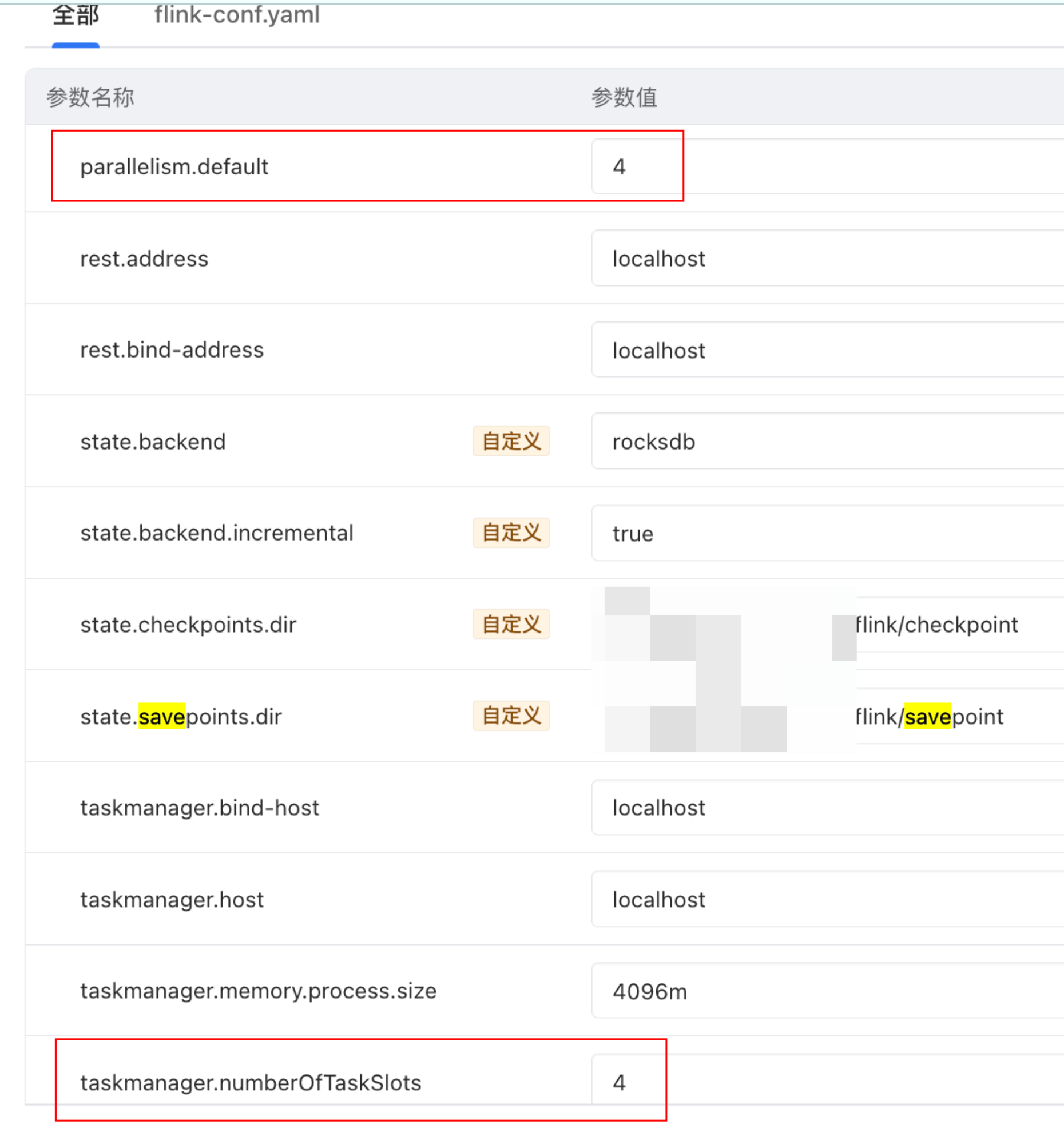
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
CDC SQL Mongo Connector默认使用MongoDB的Change Streams来获取数据变化。要提高消费速率,您可以尝试以下方法:
提高并行度:您可以在Flink的CDC任务中设置`source.parallelism`参数来提高source的并行度。例如,您可以将并行度设置为`numTaskSlots`,这将使用Flink集群中的所有任务槽来处理数据。需要注意的是,提高并行度可能会增加资源消耗和数据竞争的风险,因此需要根据实际情况进行调整。
调整MongoDB连接器参数:您可以在Flink的MongoDB连接器中设置一些参数来优化消费速率,例如:
`connector.class`:使用`MongoDBChangeEventSource`类来处理变更事件,而不是默认的`MongoDBBulkChangeEventSource`。这将使得连接器更高效地处理变更事件,从而提高消费速率。
`mongo.batch.size`:设置批量大小,以减少与MongoDB的通信次数。根据您的网络和MongoDB集群的性能,可以尝试调整此参数以获得最佳效果。
`mongo.max.document.size`:设置最大文档大小,以避免处理过大的文档。根据您的数据特点,可以尝试调整此参数以提高消费速率。
优化Flink任务配置:您还可以尝试调整Flink任务的配置,例如:
`task.timeout`:设置任务超时时间,以便在任务长时间运行时自动终止。这将有助于避免因为长时间运行的任务而导致的资源浪费。
`state.backend`:使用更高效的State Backend,例如`filesystem`或`rocksdb`,以提高任务的状态存储和恢复性能。
在使用Flink CDC SQL MongoDB Connector时,可以采取以下措施来提升数据消费速率:
并行度:
网络优化:
数据分区:
连接器参数调优:
readConcernLevel、maxBatchSize等,以优化数据读取效率。数据源性能:
容错和检查点间隔:
代码优化:
资源管理:
监控和调试:
增量快照:
要提升Flink SQL Mongo Connector的消费速率,可以尝试以下几种方法:
1、调整并行度:通过增加Flink任务的并行度,可以同时处理更多的数据流,从而提高整体的消费速率。可以在Flink配置中增加并行度参数,例如--parallelism 10,将任务并行度设置为10。
2、优化数据分区:对于大规模数据的处理,合理地划分数据分区可以减少单个分区的数据量,从而降低单个节点的负载。可以使用MongoDB的分片功能或者在Flink端进行数据分区优化。
3、调整数据读取方式:Flink SQL Mongo Connector默认使用批量读取方式,可以通过调整为流式读取方式来提高消费速率。流式读取可以实时处理数据变更,避免批量读取时的数据积压和延迟。
4、增加资源:如果集群资源不足,可以增加节点数量或者提高节点的配置,以提高整体的消费速率。
5、优化查询语句:针对MongoDB的数据访问,可以优化查询语句,避免全表扫描等低效操作,提高查询效率。
6、调整数据缓存策略:合理地使用数据缓存可以减少对数据库的访问次数,从而提高消费速率。可以根据实际情况调整缓存策略,例如设置缓存大小、缓存时间等参数。
7、优化序列化/反序列化:对于大规模数据的处理,优化序列化/反序列化的方式可以减少网络传输和内存占用,从而提高消费速率。可以使用更高效的序列化/反序列化库,例如Protobuf、Avro等。
8、调整消息处理延迟:Flink SQL Mongo Connector默认会处理所有消息,包括已经处理过的消息。可以通过设置消息处理延迟来避免重复处理相同的数据变更,从而提高消费速率。
需要根据实际情况选择合适的方法进行优化,并结合性能测试和监控来评估优化效果。
要提高MongoDB到Doris的同步速率,可以从多个角度进行优化。首先,确认一下你使用的工具是否支持并行处理和配置调整。通常,提升源端(MongoDB)的并行度可以增加数据读取速度,进而提升整个同步过程的效率。
以下是一些可能有助于提升同步速率的建议:
使用合适的CDC工具:
确保你正在使用一个支持高并发和并行处理的CDC工具。一些开源工具如Debezium或Mongo Connector提供了这样的功能。
调整并行度:
在你的工具中寻找相关参数来调整并行度。这通常涉及到设置连接池大小、线程数等。在某些工具中,这些参数可能会被称为“并行度”、“worker数”或类似的名称。增加并行度理论上可以提高消费速率,但也要注意不要过度消耗资源。
优化MongoDB查询性能:
使用适当的索引策略可以帮助加速数据读取。确保你在MongoDB上为需要同步的字段建立了合适的索引,并且它们被正确地用于查询操作。
批量处理:
尽可能采用批量处理方式来减少网络I/O次数。增大批次大小可能会提高同步速率,但需要注意避免内存溢出。
合理安排任务调度:
根据业务负载情况,选择在低峰期进行同步,以减少对生产环境的影响。
硬件优化:
如果条件允许,考虑升级服务器硬件,包括CPU、内存和网络带宽,以便更好地支持大数据量的同步。
监控与调优:
监控整个同步过程中的瓶颈,例如网络延迟、磁盘I/O、CPU使用率等,然后针对性地进行调优。
分片策略:
如果MongoDB集群是分片的,确保你的同步工具能够充分利用分片的优势,同时从多个分片并行读取数据。
应用级优化:
对于特别慢的操作,可以尝试在应用程序层面进行优化,比如通过缓存或者预计算来减少不必要的计算。
降低一致性要求:
如果业务允许,在不影响最终一致性的前提下,可以适当降低数据同步的一致性要求,从而提高同步速率。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


