
3台虚拟机,每台虚拟机总内存32G分配给hbase24G内存,regionserver的读和写分别占0.4即9.6G,listTable表有两个字段,一个rowkey(行号)empid,一个字段elc,表listTable使用预分区分了9个region,每个regionserver管理3个region,100万行数据均匀的分布在9个region中。
在hbase上搭建了Phoenix,用DBserver连接Phoenix进行查询。测试结果在dbserver客户端,查一条数据3ms,
一万条数据109ms,十万条数据1.62s,百万条数据10.5s
数据都在内存当中,为什么查百万条数据还要耗时10.5s?

通过行键过滤
查一条
SELECT empid,"elc" FROM "listTable" WHERE EMPID >= '469290-S000144001' AND EMPID <= '469290-S000144001'
查十万条
SELECT empid,"elc" FROM "listTable" WHERE EMPID >= '100000-S000144001' AND EMPID <= '200000-S000144001'
查百万条
SELECT empid,"elc" FROM "listTable"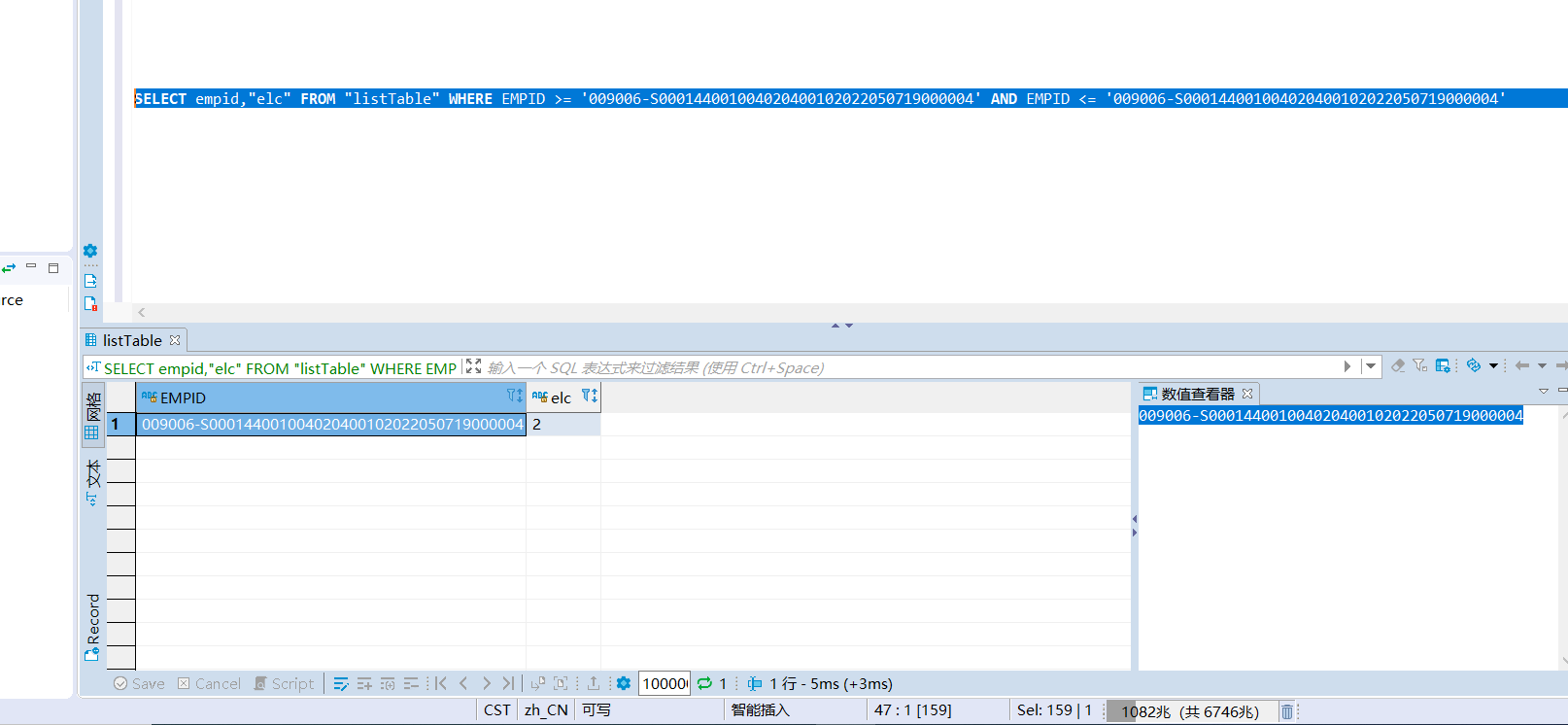

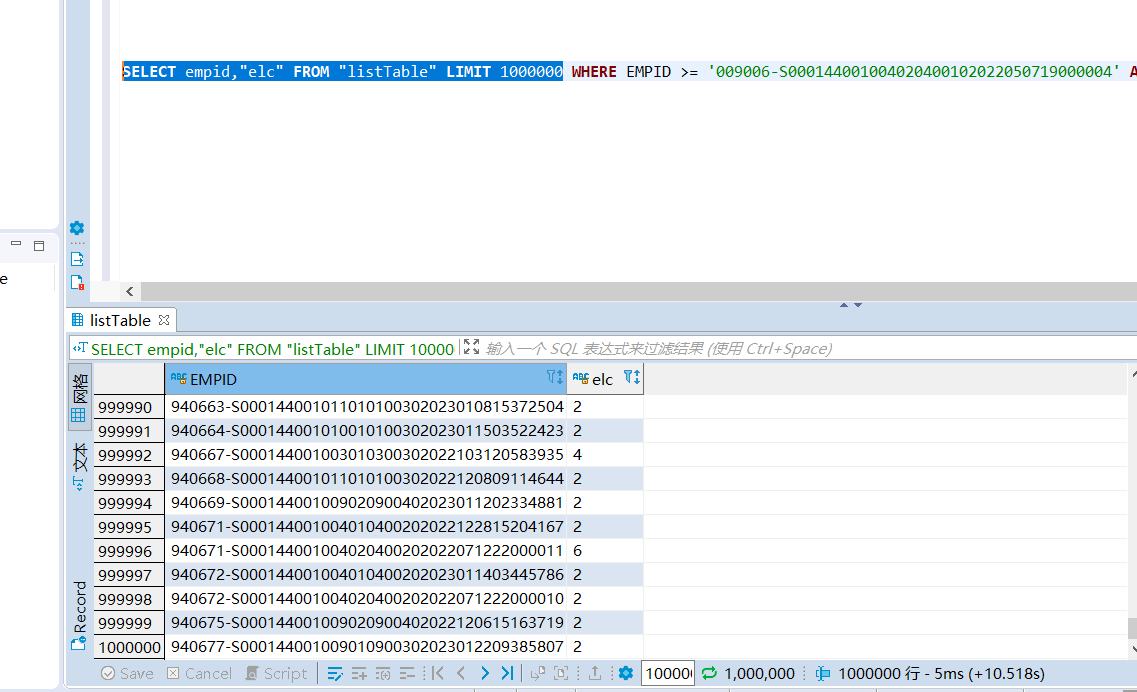
后面测试了不同region个数对速度影响
一个region,查100万数据10.4s
18个region,100万数据10.5s,
100个region,100万数据,11.7s
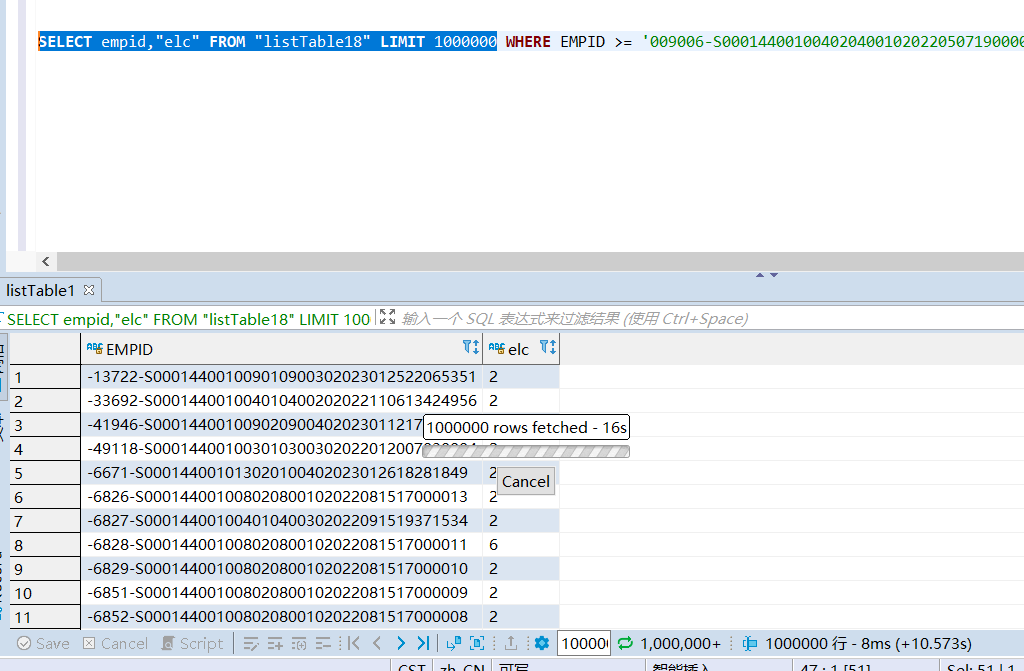
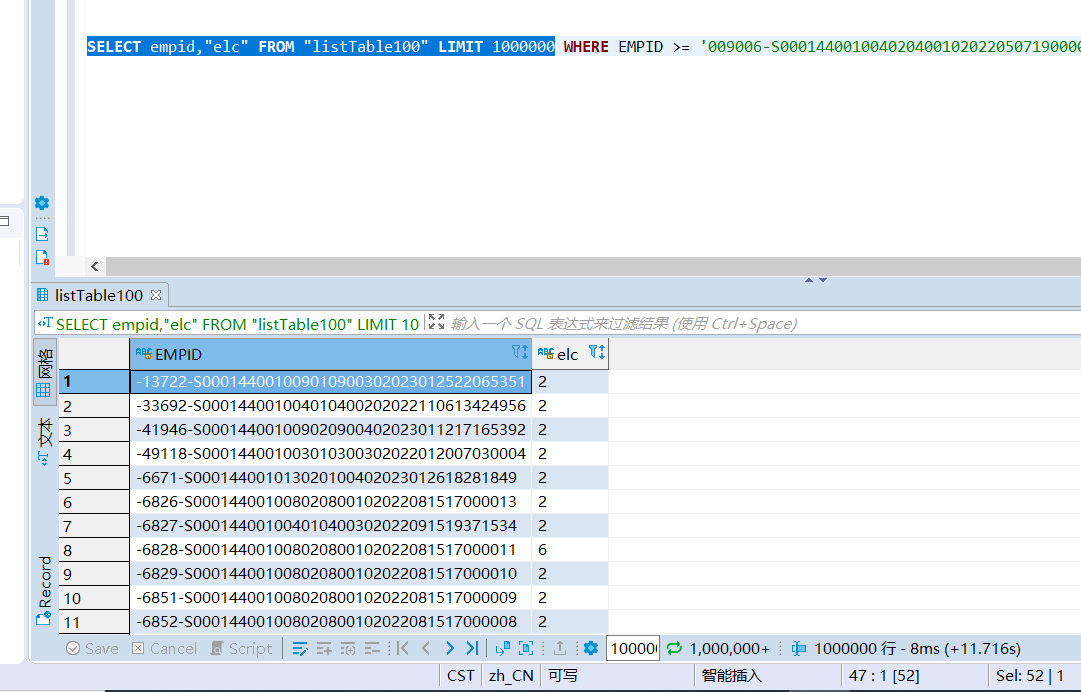
也建了索引,但同样查询条件,速度反而下降,不管怎么调整,查询百万条数据都要耗时10s以上,这是为什么呢?还望大佬不吝赐教
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
尽管您的数据都在内存中,查询百万条数据仍然需要10.5秒的原因可能有以下几点:
网络延迟:
HBase内部处理:
Phoenix 查询优化:
硬件限制:
并发问题:
系统配置:
为了提高查询性能,您可以尝试以下方法:
查询速度较慢可能由多种原因引起,以下是几种可能的解决方案:
HBase 查询速度慢的原因可能有很多,以下是一些常见的原因以及相应的解决方案:
即使数据都在内存里面,查询百万条数据还是需要一定的时间的,因为还涉及到以下几个方面:

