
ModelScope中,读光-文字识别-行识别模型-中英-手写文本领域
这个模型,有什么方法可以限定识别范围吗?比如我知道1张图片上的内容只有数字,希望模型只识别数字;如果图片上只有英文,希望模型只识别英文字母
麻烦大佬能给写个简单的示例代码吗?比如限定纯数字0-9这种,谢谢
ModelScope中,读光-文字识别-行识别模型-中英-手写文本领域是一个通用的OCR模型,它不提供直接的方法来限定识别范围。但是,您可以通过对识别结果进行后处理来实现这个目的。
以下是一个使用Python和ModelScope库的简单示例代码,用于限定识别范围为纯数字0-9:
import modelscope.pipelines as mp
from modelscope.utils.constant import Tasks
# 初始化文字识别模型
recognizer = mp.Pipeline(Tasks.ocr_recognition, model='damo/cv_resnet18_ocr_recognition_line')
# 读取图片
image = 'path/to/your/image.jpg'
# 使用模型进行识别
result = recognizer(image)
# 后处理,提取纯数字
def extract_numbers(text):
return ''.join([c for c in text if c.isdigit()])
# 应用后处理方法
for item in result:
item['text'] = extract_numbers(item['text'])
print(result)
这段代码首先使用ModelScope的Pipeline类初始化一个文字识别模型,然后读取一张图片并使用模型进行识别。识别结果是一个包含多个字典的列表,每个字典包含一个识别项的信息。最后,我们定义了一个extract_numbers函数,用于从识别结果中提取纯数字,并将其应用于识别结果。
可以使用OCR识别时的参数config_str来限定识别范围。具体地,你可以设置config_str中的language_type参数来限定语言类型,例如设置为"CHN_ENG"表示识别中英文,设置为"ENG"表示只识别英文。
同样地,你可以设置config_str中的charInfo参数来限定字符范围,例如设置为"0123456789"表示只识别数字。
下面是一个简单的示例代码:
import requests
# 阿里云OCR接口的请求URL
url = 'https://ocrapi-wordsplitter.taobao.com/ocrservice/wordsplit'
# 阿里云手写文字识别API的appcode
appcode = '<your_appcode>'
# 待识别的图片路径
image_path = '<your_image_path>'
# 构造请求头
headers = {
'Authorization': 'APPCODE ' + appcode,
'Content-Type': 'application/json; charset=UTF-8'
}
# 构造请求体
payload = {
'image': '',
'configure': '{"language_type": "CHN_ENG", "charInfo": {"enable": true, "char": "0123456789"}}',
}
# 读取待识别的图片
with open(image_path, 'rb') as f:
image_data = f.read()
# 将图片数据转换为base64编码的字符串
payload['image'] = str(base64.b64encode(image_data), encoding='utf-8')
# 发送POST请求
response = requests.post(url, headers=headers, data=json.dumps(payload))
# 解析响应结果
result = json.loads(response.text)
print(result)
注意,以上代码仅供参考,请将<your_appcode>和<your_image_path>替换为实际值。另外,如果图片中包含其他语言或字符,也会被识别出来,但是会被标注为未知字符。
当您想让读光文字识别仅识别数字时,请使用如下示例代码:
import readology as ro
# 加载模型,这里假设您已经加载好了 readology 模型
reader = ro.Recognizer(model_path="")
# 限定识别范围为数字0-9
reader.set_chars('0123456789')
# 手写数字图片的路径及输出路径
img_file = "./test.jpg"
output_file = "./output.txt"
# 对图片进行处理并输出结果
result = reader.read_img(img_file, output_file)
print(result)
在ModelScope ModelScope DIY 平台中,可以使用定制化模型来限定识别范围,例如限制只识别数字0-9。以下是一个简单的示例代码:
from damo import cv as dc
model = dc.load_model('cv_convnextTiny_ocr-recognition-handwritten')
image_url = 'your_image_path' # 请替换为你自己的图像路径
input_data = {
'url': image_url,
'limit_type': 'number', # 设置识别类型为数字
}
output_data = model.execute(input_data)
print(output_data['text'])
在这个例子中,我们设置了 limit_type 参数为 'number' 来限制模型只识别数字。如果希望只识别英文字母,可以将 limit_type 参数改为 'alphabet'。
目前没有限定识别范围的接口,如果需要的话可以在源码里面根据dict中需要索引序列(比如字母或数字对应的索引序列)对softmax的输出进行限定,具体可以在./modelscope/models/cv/ocr_recognition/model.py line154进行修改这里的输出根据字典index_select一下就可以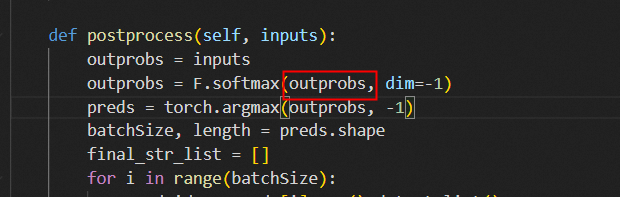
-—此回答整理自钉群:魔搭ModelScope开发者联盟群 ①

