
请教一下机器学习PAI DSSM这两个id在train/predict的时候发挥什么作用?我看了一下源码似乎没有找到这两个参数解析的踪迹。文档内这两个id对应的列名在DSSM模型的输入配置部分出现了,原理上不对哇?我们每一个user_id都是unique的,对于新用户承接而言模型没有见过它的user_id信息,我们只希望用他们的画像特征信息做u2i召回。如果模型强制要求user_id做输入,是不是意思是easyrec的DSSM模型完全不能用于新用户的item召回?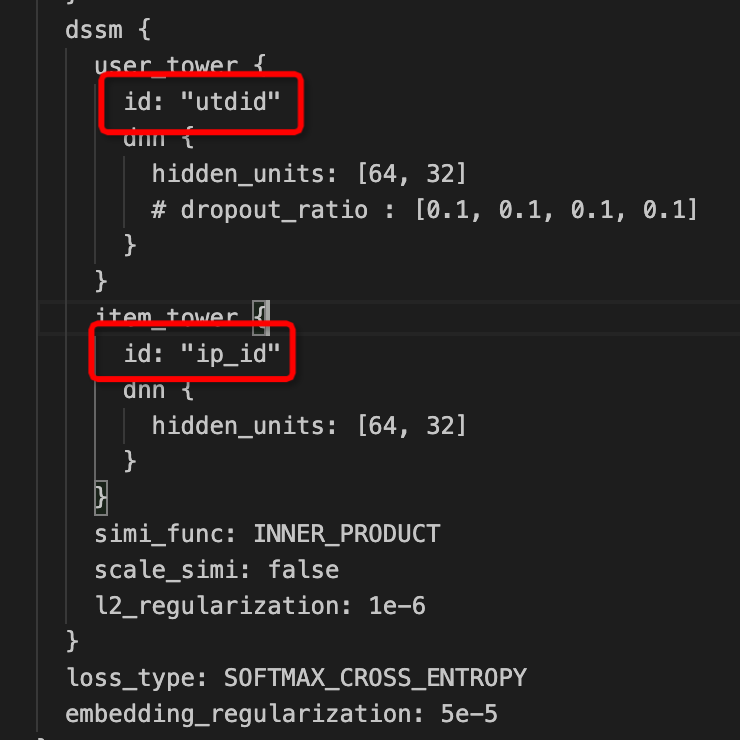
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在MaxCompute PAI的DSSM模型中,user_id和item_id是关键参数,它们分别代表着用户和物品的唯一标识符。在训练阶段,这两个参数分别对应于用户的唯一ID和物品的唯一ID。当进行预测时,我们可以通过提供user_id和item_id作为输入来获取DSSM模型的预测得分。
然而,您提到的担忧也是合理的。对于新用户,由于模型之前没有接触过他们的user_id信息,只使用他们的画像特征信息进行u2i召回确实是一种方法。但是,需要注意的是,直接将user_id和item_id作为特征加入模型可能会导致一些问题。例如,基于长尾分布的用户行为日志训练的推荐模型可能会对头部物品有偏好,这会伤害中长尾物品的曝光机会和用户满意度。
在 MaxCompute PAI DSSM 模型中,user_id 和 item_id 是用于唯一标识用户的唯一 ID。在训练阶段,这两个参数会分别对应于用户的唯一 ID 和物品的唯一 ID。当进行预测时,可以使用 user_id 和 item_id 对 DSSM 模型进行输入,以获得相应的得分。
因此,在训练时,即使新用户还没有被 DSSM 模型看到,也不影响其使用用户画像特征进行 item 回收。您只需要正确地使用 user_id 和 item_id 输入 DSSM 模型即可,这些 ID 不会被模型使用,只会被用作唯一标识。
另外,在用户画像特征之外,可以使用其他特征来进一步提高 DSSM 模型的性能,比如物品特征、标签、标签匹配等。如果您有任何疑问,请及时联系技术支持寻求帮助,我们会尽力提供帮助。
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。


