
Flink CDC任务全量跑完后 jvm heap 内存占用一直在增加 不知道为啥?已经从占用1.6G增加到2.2G了 ,就是我有两个任务 都是单表同步 全量+增量 全量同步完毕后jvm heap 占用1.6G 然后过了三分钟 内存占用飙到了 2.2G 这期间并没有增量任务

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的情况,Flink CDC任务在全量同步完成后,JVM Heap内存占用持续增加,从1.6G增长到2.2G,且期间没有增量任务。以下是可能的原因分析及解决方案:
在Flink CDC任务中,全量阶段会通过JDBC读取MySQL表的全量数据,并将这些数据加载到内存中进行处理。如果全量阶段结束后,相关的资源(如缓存、连接池等)未被及时释放,可能会导致内存占用持续增加。
execution.checkpointing.interval: 3min
execution.checkpointing.min-pause: 1min
'scan.incremental.snapshot.enabled' = 'true'
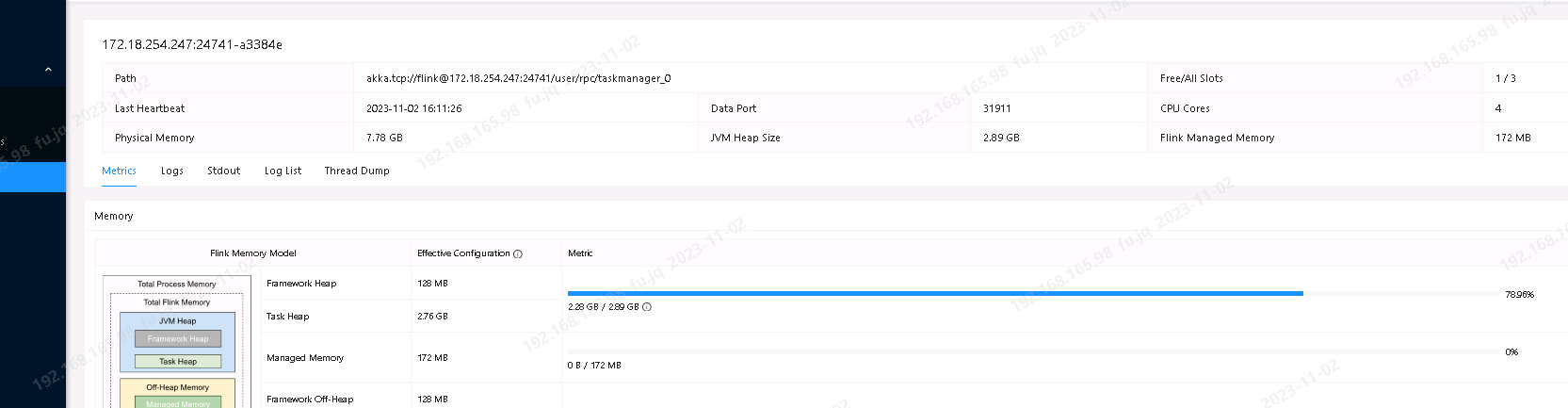
JVM的垃圾回收(GC)行为可能未能及时清理无用对象,导致Heap内存占用持续增加。这种情况通常与GC策略或内存分配不合理有关。
-Xms)和最大值(-Xmx)设置合理,避免频繁的内存扩展操作。-Xms2048m -Xmx2048m -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCDateStamps
MaxRAMPercentage参数,为其他系统组件预留更多内存:-XX:MaxRAMPercentage=70.0
如果两个任务都使用了相同的MySQL CDC源表,但未正确配置server-id,可能会导致数据源复用失败,从而增加内存占用。
server-id,以实现数据源的复用,减少对MySQL实例的压力和内存占用。'server-id' = '1001'
即使没有增量任务,Flink CDC仍然会监听Binlog的变化。如果Binlog缓存未被及时清理,可能会导致内存占用持续增加。
scan.startup.mode参数跳过Snapshot阶段,直接从Binlog开始读取。'scan.startup.mode' = 'latest-offset'
'debezium.max.batch.size' = '1024'
'debezium.max.queue.size' = '8192'
TaskManager线程数过多可能导致内存占用增加。可以通过监控指标确认线程数是否异常。
TM Threads指标,确认是否存在线程数过多的问题。parallelism),或者优化任务的算子链(Chaining)。SET parallelism.default = 4;
根据上述分析,建议您按照以下步骤排查和解决问题: 1. 检查Checkpoint配置,确保全量阶段结束后能够正确释放资源。 2. 优化JVM内存配置,启用G1GC并监控GC日志。 3. 确保多个CDC任务中配置了相同的server-id,实现数据源复用。 4. 调整Debezium的Binlog缓存大小,避免缓存过多数据。 5. 监控TaskManager线程数,合理设置并发度。
如果问题仍未解决,建议进一步收集以下信息以便深入分析: - Flink作业的GC日志和Heap Dump文件。 - TaskManager的线程数和内存使用情况。 - MySQL CDC源表的配置参数和运行日志。
希望以上内容能够帮助您解决问题!
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

