
dataworks如何实现自动解析表的血缘关系?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在阿里云的DataWorks中,自动解析表的血缘关系主要通过以下步骤实现:
任务配置:在创建数据集成任务时,需要在任务配置中指定输入和输出的表。这样,DataWorks就可以根据这些配置信息,知道哪些表是输入表,哪些表是输出表。
解析SQL:DataWorks会自动解析任务中的SQL命令,找出哪些表被写入,哪些表被读取。然后,DataWorks就会根据这些信息,建立表之间的血缘关系。
生成血缘关系图:DataWorks会根据解析的结果,生成一张血缘关系图。这张图中,每个节点代表一个表,如果表A被表B写入,那么在图上就会有一条边从表A指向表B。
自动添加依赖:DataWorks会根据血缘关系图,自动为任务添加依赖。例如,如果一个任务的输出是另一个任务的输入,那么DataWorks就会为这两个任务添加依赖,保证先执行前一个任务,再执行后一个任务。
自动解析优化:DataWorks的自动解析功能采用了一些优化策略,例如,它只会解析任务中的关键部分(例如SELECT和INSERT语句),而不是整个SQL命令,这样就大大提高了解析的效率。
DataWorks的自动解析表的血缘关系功能,可以大大提高数据集成任务的开发效率和运行效率,非常适合大规模的数据集成任务。
应用场景 DataWorks支持根据任务节点中的SQL命令,自动解析出表数据的血缘关系,以表数据的血缘关系为基座,为节点自动添加本节点的输出或依赖的上游节点,自动解析高效便捷,适用于绝大部分场景。实现原理下图为自动解析依赖关系的原理。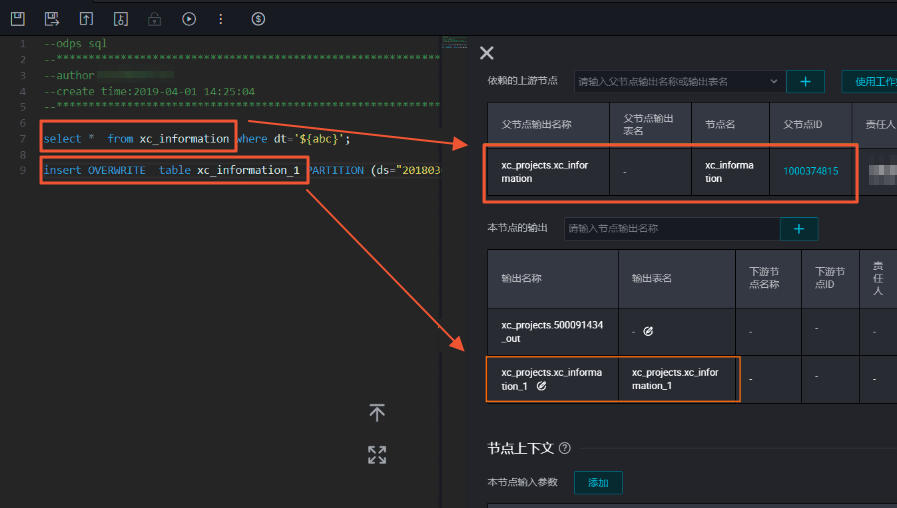
SELECT一张表,该表将自动解析为本节点依赖的上游。INSERT一张表,该表将自动解析为本节点的输出。如果出现的多个INSERT、SELECT,则会自动解析出多个输出、输入名称。配置方法自动解析通过SQL代码命令自动识别配置,无需您手动配置。自动配置的原则如下表所示。节点类型 代码命令 自动解析 调度依赖配置规则
ODPS节点 当节点代码中出现此类输出命令时,会自动为节点添加一条本节点输出配置内容。 为节点自动添加的本节点输出命名规则为:odps_project_name.table_name。
SELECT 当节点代码中出现此命令时,会自动为节点添加一条依赖的上游节点配置内容。 为节点自动添加的依赖的上游节点命名规则为:project_name.table_name。
非ODPS的SQL节点 当节点代码中出现此类输出命令时,会自动为节点添加一条本节点输出配置内容。 各类型节点自动添加的本节点输出命名规则为:
SELECT 当节点代码中出现此命令时,会自动为节点添加一条依赖的上游节点配置内容。 为节点自动添加的依赖的上游节点命名规则为:project_name.table_name。
离线同步节点 离线同步节点不支持自动解析,需要手动添加节点的调度依赖配置。注意事项代码开发要求自动解析完全依据您的任务节点中代码自动识别,因此您在进行数据开发时,建议严格遵循DataWorks的代码开发要求和节点创建要求:代码开发要求:一张表数据由一个节点产出,一个节点只产出一张表。节点创建要求:建议节点名称与产出表的表名称保持一致。调度配置要求:节点的产出表需配置为本节点的输出。不支持自动解析的场景离线节点、AnalyticDB for PostgreSQL节点、AnalyticDB for MySQL节点、EMR节点不支持通过自动解析添加节点的调度依赖,这些节点的产出表需要手
https://help.aliyun.com/document_detail/137550.html
节点全量的血缘可以直接查看运维中心的DAG图 表的血缘可以进入数据地图查看,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks提供了自动解析表的血缘关系的功能,可以通过以下步骤实现:
DataWorks提供了自动解析表的血缘关系功能,以帮助用户了解数据在整个数据流程中的来源和去向。以下是实现自动解析表的血缘关系的步骤:
登录DataWorks控制台:使用您的账号登录阿里云控制台(https://www.aliyun.com/),然后进入DataWorks管理控制台。
进入项目:在DataWorks管理控制台中选择相应的项目,进入该项目的详情页。
打开数据开发:在项目详情页中,点击左侧菜单栏中的“数据开发”选项。
选择数据表:在数据开发界面中,选择您要查看血缘关系的数据表。
查看血缘关系:在选中的数据表上右键单击,选择“查看血缘关系”选项。
解析血缘关系:系统将开始解析和展示选定表的血缘关系图。您可以通过该图表来查看与该表相关的输入表、输出表和中间表等。
通过这些步骤,您可以方便地在DataWorks中实现自动解析表的血缘关系,并通过可视化图表更好地理解数据在整个流程中的传递和关联情况。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


