
服务器上启动了一个Flink流处理作业,运行近一个月时间后,发现个别task manager进程突然挂掉了。
该作业的数据流量较大,当前task manager的资源配置为:
Physical Memory: 4GB
JVM Heap Size: 1.56GB
Flink Managed Memory: 1.35GB
在task manager挂掉后,我检查了其日志文件,但是没有找到明显的异常信息,如OOM等。云平台的监控也没有发现CPU或内存使用异常。
已采取的排查步骤:
检查了task manager日志文件,没有明显异常
检查了云平台的CPU和内存监控,没有发现异常?好像是这里的原因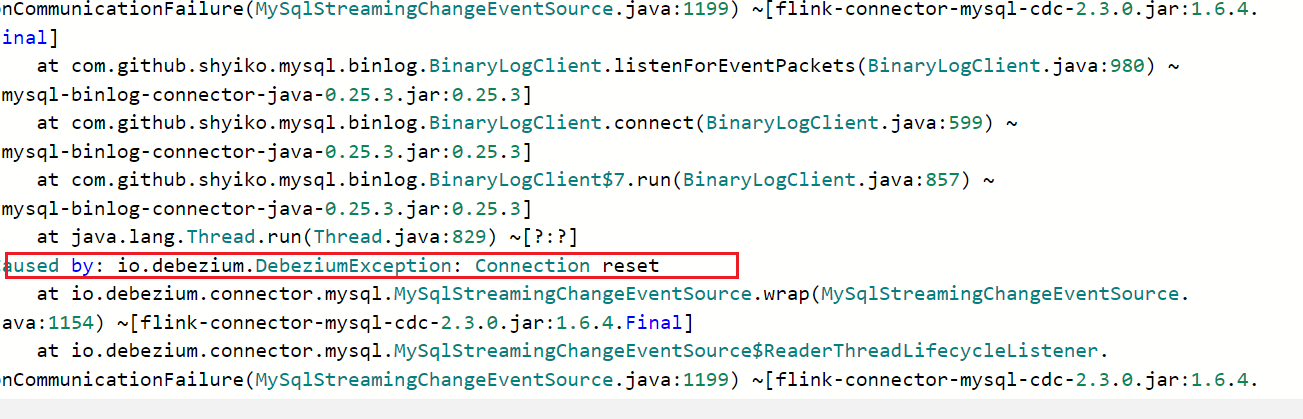
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的情况,Flink流处理作业运行近一个月后,个别TaskManager进程突然挂掉,且日志中未发现明显的异常信息(如OOM),云平台的CPU和内存监控也未显示异常。以下是基于知识库资料的详细分析与排查建议:
尽管云平台监控未显示内存异常,但Flink作业的内存管理涉及多个部分,可能存在隐性问题: - JVM Heap Size不足:当前配置为1.56GB,可能不足以应对长时间运行的大数据流量作业。如果Heap内存不足,可能导致频繁的垃圾回收(GC),进而引发TaskManager挂掉。 - 解决建议:适当增加JVM Heap Size,例如调整至2GB或更高,并观察GC日志以确认是否存在频繁GC问题。 - Managed Memory压力:Flink Managed Memory用于算子状态、缓存等操作,当前配置为1.35GB。如果作业涉及大量状态操作(如窗口聚合、Join等),可能导致Managed Memory不足。 - 解决建议:增加Physical Memory总量(例如从4GB提升至8GB),并相应调整Managed Memory比例。
TaskManager挂掉可能是由于线程死锁或资源争用导致的。虽然日志中未显示异常,但仍需进一步分析线程栈信息: - 线程栈分析:通过线程栈信息检查是否存在线程阻塞或死锁现象。可以使用jstack工具导出TaskManager的线程栈信息,并分析是否存在长时间阻塞的线程。 - 解决建议:如果发现线程阻塞或死锁,优化相关算子逻辑,避免资源争用。
TaskManager挂掉可能与本地磁盘空间不足有关。Flink在运行过程中会将中间结果存储在本地磁盘上,如果磁盘空间耗尽,可能导致TaskManager崩溃。 - 磁盘空间限制:每个TaskManager的磁盘空间与其分配的CPU核心数成比例,默认每个CPU核心配额20GiB磁盘空间,最大为200GiB。 - 解决建议: 1. 检查TaskManager所在服务器的磁盘使用情况,确保有足够的可用空间。 2. 如果磁盘空间不足,减少每个TaskManager上的Slot数量,降低单个节点的并行任务数,从而减少对本地磁盘空间的需求。 3. 提高TaskManager的CPU核心数,以增加其磁盘空间配额。
如果作业中使用了外部连接器(如Kafka、MaxCompute等),可能存在网络或连接器相关的异常: - 连接器超时或失败:例如,MaxCompute连接器的endPoint或tunnelEndpoint配置错误可能导致任务异常。 - 解决建议: 1. 检查连接器配置是否正确,尤其是endPoint和tunnelEndpoint。 2. 如果存在小文件问题,合并小文件以优化读取性能。 - 网络波动:长时间运行的作业可能因网络波动导致TaskManager挂掉。 - 解决建议:检查网络稳定性,确保TaskManager与外部系统的连接正常。
如果作业涉及大状态操作(如窗口聚合、Join等),可能存在状态膨胀或反压问题: - 状态膨胀:大状态可能导致TaskManager内存压力增加,甚至崩溃。 - 解决建议: 1. 使用SQL优化器提供的功能(如table.optimizer.distinct-agg.split.enabled: true)减少状态大小。 2. 调整多流Join顺序,优先连接数据量较小的流,缓解状态放大效应。 - 反压问题:如果作业存在反压,可能导致TaskManager挂掉。 - 解决建议: 1. 检查作业节点是否存在反压,添加pipeline.operator-chaining: 'false'参数拆开算子链,观察是否有被反压的节点影响消费速率。 2. 优化上游数据生成规律,确保数据生产和处理速度匹配。
根据上述分析,建议按照以下步骤逐步排查和解决问题: 1. 增加TaskManager的Physical Memory和JVM Heap Size,优化内存配置。 2. 检查磁盘空间使用情况,必要时减少Slot数量或增加CPU核心数。 3. 分析线程栈信息,排查是否存在线程阻塞或死锁。 4. 检查连接器配置和网络稳定性,确保外部系统连接正常。 5. 优化状态管理和反压问题,减少大状态对资源的压力。 6. 调整日志级别,捕获更详细的运行信息。
如果问题仍未解决,请提供更详细的日志信息(如GC日志、线程栈信息等),以便进一步分析。您也可以通过ECS一键诊断全面排查并修复ECS问题。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

