
在ModelScope中,这个天龙八部里txt,需要提供什么样的数据格式,就是一整本书吗?还是需要做特定的数据预处理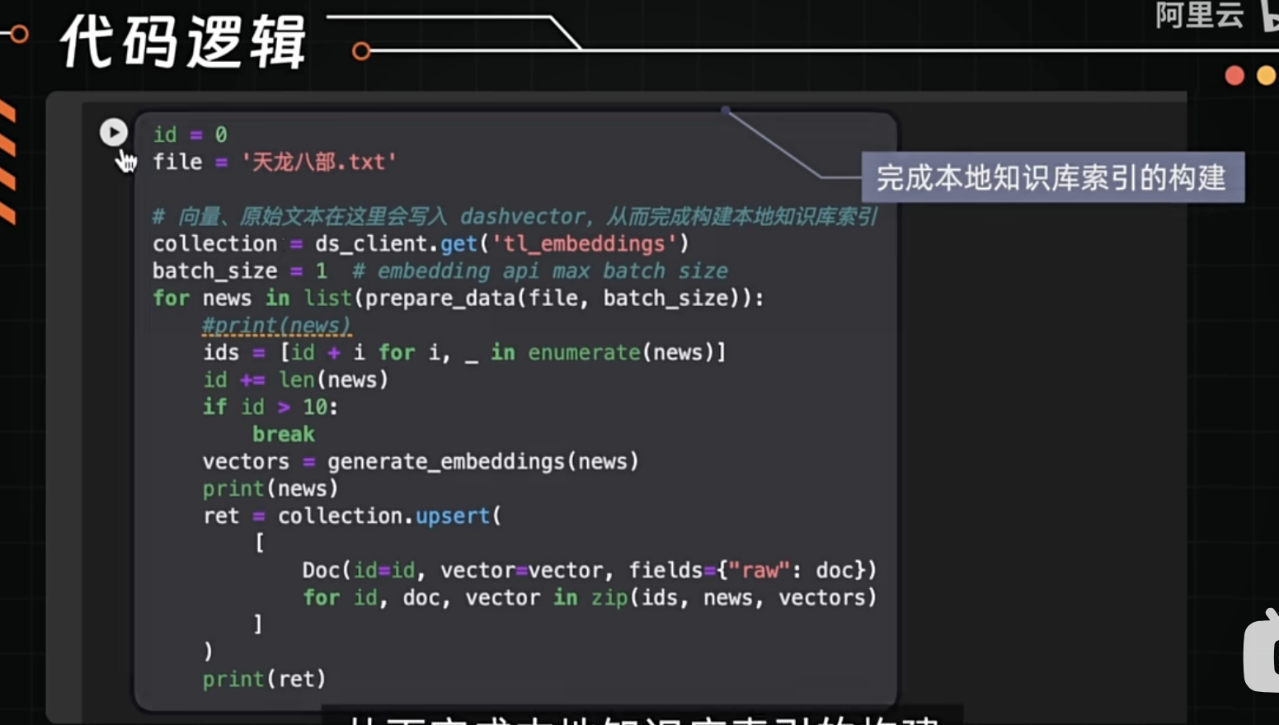
https://modelscope.cn/models/qwen/Qwen-7B/summary%20https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary这是模型信息想了解是整本故事数据丢到txt里咩,如果需要数据预处理的话,那需要怎么处理法
在ModelScope中,如果您希望使用类似《天龙八部》这样的文本数据对模型(如Qwen-7B或Qwen-7B-Chat)进行微调或训练,通常需要对原始文本数据进行特定的预处理,而不是直接将整本书丢到一个TXT文件中。以下是关于数据格式和预处理的具体说明:
根据知识库中的相关文档,模型微调所需的数据通常以JSON格式提供,而不是直接使用纯文本文件。每个样本需要包含以下字段: - id:唯一标识符,用于区分不同的样本。 - conversations:对话内容,通常是一个列表,包含多轮对话的输入和输出。
示例数据格式如下:
[
{
"id": "1",
"conversations": [
{
"from": "user",
"value": "段誉是谁?"
},
{
"from": "assistant",
"value": "段誉是《天龙八部》中的主要角色之一,他出身于大理段氏皇族,性格善良且痴情。"
}
]
},
{
"id": "2",
"conversations": [
{
"from": "user",
"value": "乔峰为什么离开丐帮?"
},
{
"from": "assistant",
"value": "乔峰因身世之谜被揭露,被认为是契丹人,因此被迫离开丐帮。"
}
]
}
]
如果您的原始数据是一整本《天龙八部》的TXT文件,您需要对其进行以下预处理操作:
id,并且conversations字段包含完整的对话内容。以下是一个简单的Python脚本,用于将TXT文件转换为JSON格式的对话数据:
import json
# 原始TXT文件路径
input_file = "tianlongbabu.txt"
# 输出JSON文件路径
output_file = "tianlongbabu_data.json"
# 读取TXT文件并分割为段落
with open(input_file, "r", encoding="utf-8") as f:
paragraphs = f.read().split("\n\n")
# 构建JSON数据
data = []
for i, paragraph in enumerate(paragraphs):
if not paragraph.strip():
continue
# 模拟问答对
question = f"请解释以下内容:{paragraph[:50]}..."
answer = paragraph
data.append({
"id": str(i + 1),
"conversations": [
{"from": "user", "value": question},
{"from": "assistant", "value": answer}
]
})
# 写入JSON文件
with open(output_file, "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print(f"数据已保存至 {output_file}")
通过以上步骤,您可以将《天龙八部》的文本数据转化为适合Qwen-7B或Qwen-7B-Chat模型微调的格式。
