
Flink CDC我这里只提供一个链接 为什么通过SINK可以打印出来多次 而且地址不一样,又不是多线程 这是什么技术?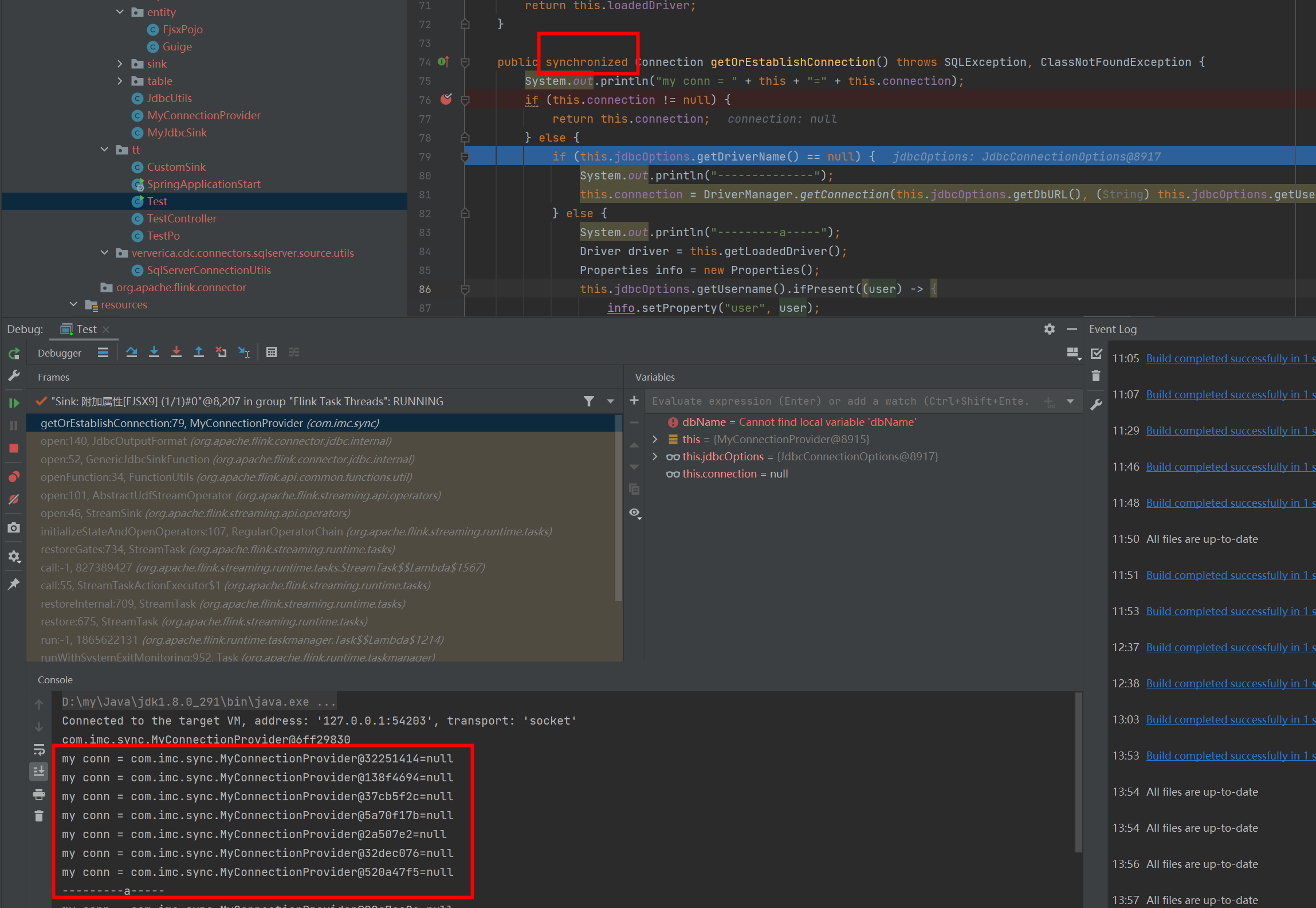
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用Flink CDC时,您提到通过Sink可以打印出多次数据,并且地址不同,即使没有启用多线程。这种现象可以通过以下几个方面来解释:
Flink作业默认会根据配置的并行度(Parallelism)将任务划分为多个并行子任务(Subtask)。即使您未显式设置多线程,Flink的并行度机制仍然会导致数据被分发到不同的并行子任务中处理。每个子任务独立运行,因此可能会看到多次打印的数据,且打印的地址不同。
原因:
Sink算子的并行度通常与上游算子保持一致。如果上游算子的并行度大于1,Sink算子也会以相同的并行度运行,导致数据被多个并行子任务分别处理和输出。
解决方法:
如果希望Sink只在一个线程中运行,可以将Sink的并行度设置为1:
SET sink.parallelism = 1;
Flink的Checkpoint机制会在定期保存状态时触发数据重放(Replay)。如果您的作业启用了Checkpoint,Flink可能会在某些情况下重新处理部分数据,导致Sink多次输出相同的数据。
原因:
Flink为了保证Exactly-Once语义,在发生Failover或Checkpoint对齐时,可能会重新处理部分数据。这种行为可能导致Sink多次接收到相同的数据记录。
解决方法:
检查是否启用了Checkpoint,并确认是否需要调整Checkpoint间隔或容错语义(如改为At-Least-Once):
SET execution.checkpointing.interval = 60000; -- 设置Checkpoint间隔为60秒
如果您在YAML作业中定义了多条路由规则(Route),同一张源表的数据可能会被分发到多个目标表中。这种情况下,Sink会针对每条路由规则分别输出数据,导致多次打印。
原因:
在route模块中,如果定义了多条路由规则,Flink会将同一份数据分发到多个下游目标表。例如:
route:
- source-table: mydb.orders
sink-table: sink_db.orders
- source-table: mydb.orders
sink-table: backup_sink_db.orders
这种配置会导致mydb.orders的数据被分发到sink_db.orders和backup_sink_db.orders两个目标表中,从而产生多次输出。
解决方法:
检查YAML作业中的route模块配置,确保路由规则符合预期。如果不需要多次分发,可以删除多余的路由规则。
默认情况下,Flink的Sink算子是无状态的(Stateless)。这意味着Sink不会对已经处理过的数据进行去重或过滤,而是直接将接收到的数据输出。如果上游算子多次发送相同的数据,Sink会多次打印。
原因:
Sink算子默认被视为无状态算子(table.optimizer.state-compatibility.ignore-sink=true),因此不会对重复数据进行处理。
解决方法:
如果需要避免重复输出,可以在Sink前添加去重逻辑,例如使用GROUP BY或DISTINCT操作:
INSERT INTO MySink
SELECT DISTINCT a, b, c
FROM MyTable;
在使用print连接器时,Flink会将数据打印到控制台或日志文件中。由于每个并行子任务独立运行,打印的日志可能来自不同的线程或进程,因此地址不同。
原因:
print连接器的实现方式决定了每个并行子任务会独立打印数据。如果并行度大于1,日志中会显示多个地址。
解决方法:
如果需要统一日志输出,可以将print连接器的并行度设置为1,或者使用其他日志聚合工具(如Logstash、Fluentd)对日志进行集中管理。
通过以上分析,您遇到的现象可能是由以下原因导致的: 1. Flink的并行度机制导致数据被多个子任务处理。 2. Checkpoint机制触发了数据重放。 3. YAML作业中的路由规则导致数据被多次分发。 4. Sink算子的无状态特性未对重复数据进行去重。 5. print连接器的实现方式导致日志地址不同。
建议您根据实际需求调整并行度、检查路由规则、优化Checkpoint配置,或在Sink前添加去重逻辑,以解决多次打印的问题。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

