
DataWorks离线同步任务已经这样二十分钟了,是资源组有什么变化吗?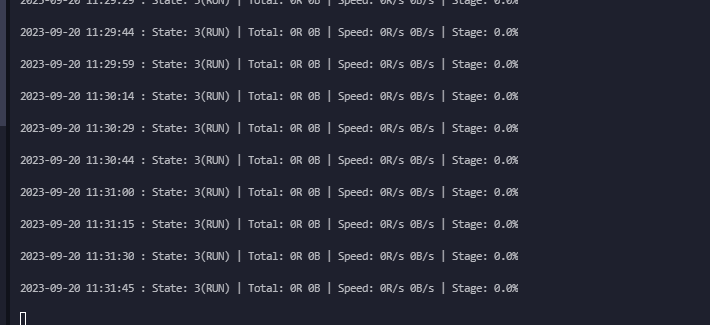
https://di-cn-shanghai.data.aliyun.com/web/di/instanceLog?id=1231846774&resourceGroup=group_397742964171266&requestId=bb61df96-5fcd-4a72-aba5-dca57c4a5f37&projectId=351026是数据量太大的原因吗?感觉是数据量比较大的原因,我是不是只能用分布式增加并发数进行同步了
现在一直在报这个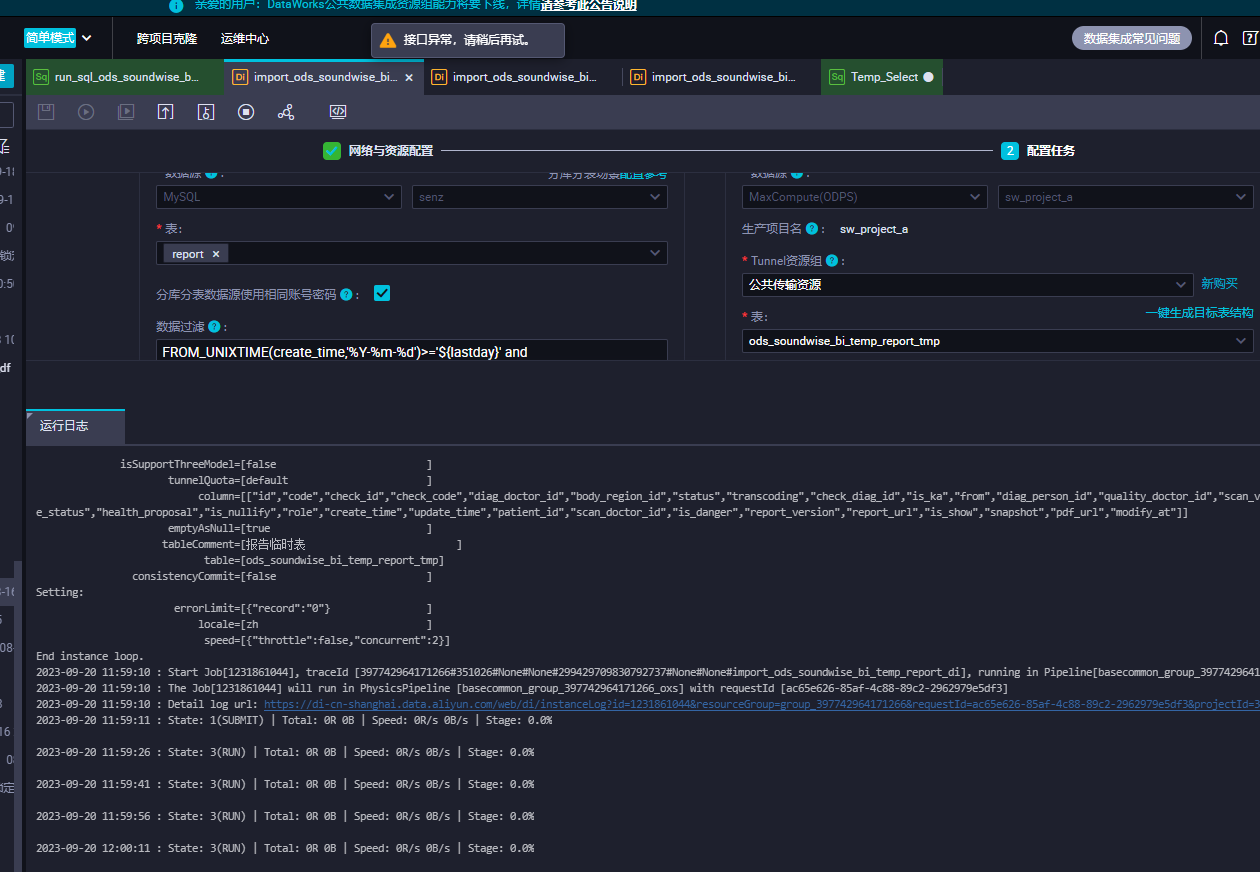
接口异常
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
原句在mysql执行耗时要多久呢 SELECT MIN(id),MAX(id) FROM order WHERE (FROM_UNIXTIME(create_time,'%Y-%m-%d')>='2022-01-01' and FROM_UNIXTIME(create_time,'%Y-%m-%d')<'2022-02-01' AND id IS NOT NULL)
或者可以看下mysql那边的审计记录 是不是慢sql了
现在应该是还在切分前就长sql了 一个月时间间隔的数据看能不能缩小点范围 多次同步,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。

