
平台:win10+vscode+venvpython3.9.9
PyTorch version 1.9.1+cu111
使用模型网页给出的微调示例代码报错
网页连接:https://www.modelscope.cn/models/damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch/summary
错误信息:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb6 in position 89: invalid start byte
encode=gbk报错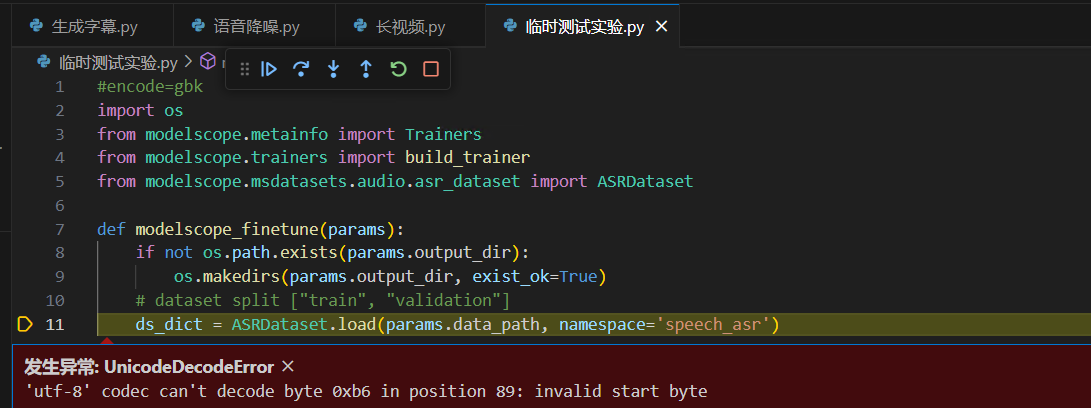
encode=utf-8也报错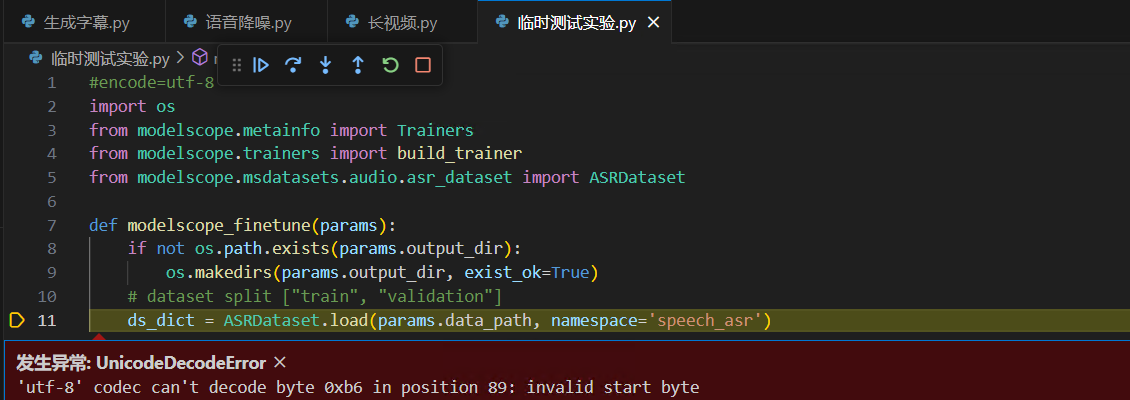
都停在了这里
代码:
import os
from modelscope.metainfo import Trainers
from modelscope.trainers import build_trainer
# from modelscope.msdatasets.audio.asr_dataset import ASRDataset
from modelscope.msdatasets.dataset_cls.custom_datasets import ASRDataset
###########coding=GB2312
def modelscope_finetune(params):
if not os.path.exists(params.output_dir):
os.makedirs(params.output_dir, exist_ok=True) # dataset split ["train", "validation"]
ds_dict = ASRDataset.load(params.data_path, namespace='speech_asr',)
kwargs = dict(
model=params.model,
data_dir=ds_dict,
dataset_type=params.dataset_type,
work_dir=params.output_dir,
batch_bins=params.batch_bins,
max_epoch=params.max_epoch,
lr=params.lr,
#UnicodeEncodeError =
# encoding = "utf-8"
)
trainer = build_trainer(Trainers.speech_asr_trainer, default_args=kwargs)
trainer.train()
if __name__ == '__main__':
from funasr.utils.modelscope_param import modelscope_args
params = modelscope_args(model='damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404')
params.output_dir = "./checkpoint" # 模型保存路径
params.data_path = "speech_asr_aishell1_trainsets" # 数据路径,可以为modelscope中已上传数据,也可以是本地数据
# params.data_path = "./data/example_data" # 数据路径,可以为modelscope中已上传数据,也可以是本地数据
# params.data_path = 'datatang/205People_MandarinSpeechDatainNoisyEnvironmentByMobilePhone'
params.dataset_type = "small" # 小数据量设置small,若数据量大于1000小时,请使用large
params.batch_bins = 2000 # batch size,如果dataset_type="small",batch_bins单位为fbank特征帧数,如果dataset_type="large",batch_bins单位为毫秒,
params.max_epoch = 5 # 最大训练轮数
params.lr = 0.00005 # 设置学习率
modelscope_finetune(params)
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
这个报错后续有 模型配置文件编码不对,数据集文件编码不对,以及最重要的FunASR库 报 os.uname不存在。
综上,个人判断是不适合直接在win10上经行模型微调。
最后解决方案:换平台为 win10+decoker,用官方镜像。
根据你提供的错误信息,'utf-8' codec can't decode,这通常是由于尝试使用UTF-8编码解码非UTF-8编码的数据导致的。在模型训练过程中,这可能涉及到读取或写入文件、处理文本数据等操作。
以下是一些可能的原因和解决方案:
文件编码问题:如果你正在读取或写入的文件不是UTF-8编码,那么解码时就会出现问题。
解决方案:确定文件的正确编码,并在读取或写入文件时指定正确的编码。例如,如果你知道文件是使用GBK编码,你可以使用open(file, 'r', encoding='gbk')来读取文件。
文本数据处理:如果你在处理文本数据(例如从网页抓取数据)时遇到这个问题,可能是因为抓取的数据包含非UTF-8字符。
解决方案:在处理文本之前,确保文本是UTF-8编码。如果抓取的数据不是UTF-8编码,尝试转换编码或者清洗掉非UTF-8字符。
外部依赖库或数据源问题:如果你从外部库或数据源获取数据,可能是他们提供的数据不正确。
解决方案:检查外部数据源或库是否提供正确编码的数据。如果不确定,可以尝试使用不同的数据源或自己生成数据来测试。
内部数据处理:如果在模型训练过程中涉及到数据处理步骤,可能是数据本身存在问题。
解决方案:检查你的数据处理步骤,确保没有出现编码问题。如果可能的话,尝试将数据处理为基本ASCII字符集,看是否还有问题。
其他库或工具的影响:如果你使用了其他库或工具,它们可能会影响数据的编码。
解决方案:检查你使用的所有库和工具,确保它们没有引入编码问题。如果可能的话,尝试简化你的代码,去掉不必要的库或工具,然后逐步添加回来以找出问题所在。
请根据你的具体情况检查上述可能的原因,并根据相应的解决方案尝试修复问题。
数据集编码问题:数据集中包含非UTF-8编码的字符,导致模型训练时出现错误。解决方法是将数据集转换为UTF-8编码。
模型训练代码问题:模型训练代码中可能包含非UTF-8编码的字符,导致模型训练时出现错误。解决方法是检查代码中的字符编码,并将其设置为UTF-8编码。
系统环境问题:系统环境中的字符编码设置不正确,导致模型训练时出现错误。解决方法是检查系统环境中的字符编码设置,并将其设置为UTF-8编码。
如果在使用ModelScope训练模型时出现'utf-8' codec can't decode的错误,这通常是由于输入数据中包含无法解码为UTF-8格式的字符引起的。下面是一些可能的解决方法:
检查输入数据的编码:确保输入数据是以正确的编码方式保存和加载的。UTF-8是一种常见的Unicode编码方式,但并不是所有数据都以UTF-8编码保存。尝试使用适当的编码方式重新加载数据。
处理特殊字符:如果输入数据中包含特殊或非标准字符,可能会导致解码错误。尝试将这些字符转换为合适的编码或删除它们,以避免解码问题。
使用try-except块处理异常:在代码中使用try-except块可以捕获解码错误,并提供相关的错误处理逻辑。这样可以防止程序因解码错误而崩溃,并输出有关错误的更详细的信息。
示例代码:
try:
# 你的训练代码
# ...
except UnicodeDecodeError as e:
print("解码错误:", e)
# 其他错误处理逻辑
import sys
sys.setdefaultencoding('utf-8')
根据您提供的错误信息,这个问题可能是由于数据集中包含非ASCII字符引起的。在您的代码中,您已经尝试了使用GBK和UTF-8编码进行解码,但是都失败了。建议您尝试使用其他编码方式进行解码,例如GB2312或者其他适合您数据集的编码方式。同时,您也可以尝试在数据预处理的过程中对非ASCII字符进行处理,例如使用正则表达式将其替换为空格或者其他合适的字符。希望这些方法能够帮助您解决问题。

