
刚接触flink 我试了下官方的DEMO 用SourceFunction 的那个DEMO可以监听到数据
用2.4之后的就监听不到数据 控制台没打印 还有个SplitFetcher thread 0 received unexpected exception while polling the records 错误
这个要怎么解决?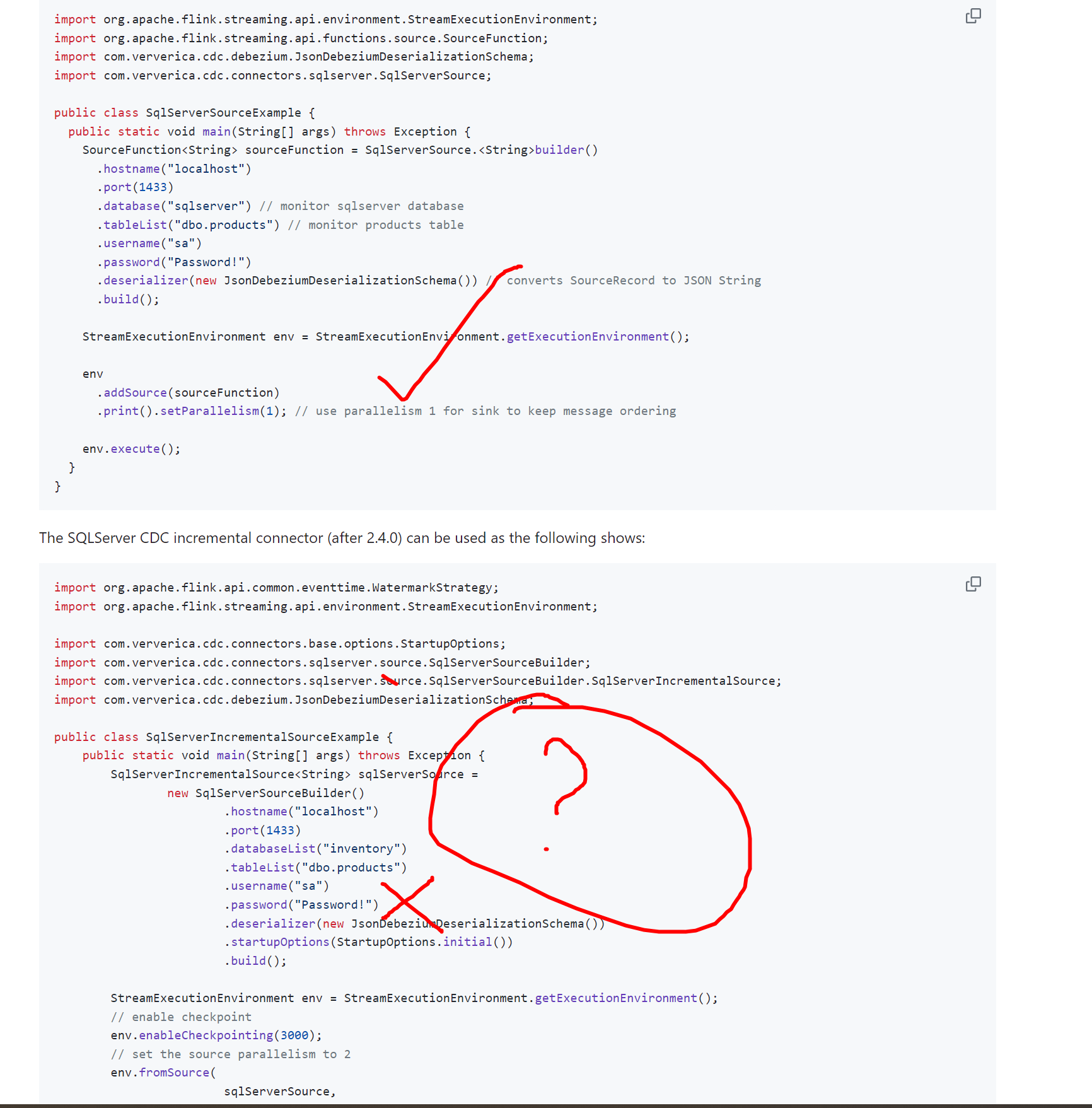

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的问题,使用Flink的SourceFunction可以正常监听到数据,但在升级到2.4版本后无法监听到数据,并且控制台未打印任何信息,同时出现SplitFetcher thread 0 received unexpected exception while polling the records错误。以下是针对该问题的详细分析和解决方案:
版本差异导致的行为变化
Flink在不同版本中对Source API进行了多次优化和重构,尤其是从2.4版本开始,引入了新的Source架构(如SourceReader和SplitFetcher)。如果您的代码未适配新版本的API,可能会导致数据监听失败或异常。
SplitFetcher线程异常
错误信息SplitFetcher thread 0 received unexpected exception while polling the records表明在SplitFetcher线程中发生了未捕获的异常。这通常与以下原因有关:
日志未打印
如果控制台未打印任何日志,可能是日志级别设置过高或日志输出被重定向。需要检查日志配置是否正确。
确保数据源的连接参数(如Kafka的Broker地址、Topic名称等)正确无误。如果使用的是Kafka Source,请确认以下内容: - Kafka集群是否正常运行。 - Topic是否存在且有数据写入。 - Flink作业是否能够访问Kafka集群(网络连通性)。
可以通过以下命令测试网络连通性:
telnet <kafka-broker-ip> <kafka-port>
如果网络不通,请参考文档排查跨VPC或公网访问的配置。
从Flink 2.4版本开始,推荐使用Source接口替代旧版的SourceFunction。以下是适配新版本的示例代码:
import org.apache.flink.api.connector.source.Source;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class NewSourceExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 使用新版本的Source API
Source<String, ?, ?> source = KafkaSource.<String>builder()
.setBootstrapServers("<kafka-broker>")
.setTopics("<topic-name>")
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source")
.print();
env.execute("New Source Example");
}
}
请根据实际需求替换<kafka-broker>和<topic-name>。
如果控制台未打印日志,可能是因为日志级别设置过高。可以在Flink开发控制台中调整日志级别为DEBUG或INFO: 1. 登录实时计算控制台。 2. 在运维中心 > 作业运维页面,单击目标作业名称。 3. 在部署详情页签的运行参数配置区域,添加以下参数:
env.java.opts: '-Dlog.level=DEBUG'
SplitFetcher线程异常通常与数据源的Schema或格式不匹配有关。建议检查以下内容: - 数据源的Schema是否与代码中的解析逻辑一致。 - 如果使用Kafka,确认消息的序列化格式(如JSON、Avro等)与反序列化器匹配。
例如,如果Kafka消息是JSON格式,需使用对应的反序列化器:
import org.apache.flink.formats.json.JsonDeserializationSchema;
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("<kafka-broker>")
.setTopics("<topic-name>")
.setValueOnlyDeserializer(new JsonDeserializationSchema<>(true, true, String.class))
.build();
如果数据源响应较慢,可能导致SplitFetcher线程超时。可以在DDL的WITH参数中增加connect.timeout的值:
CREATE TABLE kafka_source (
...
) WITH (
'connector' = 'kafka',
'properties.bootstrap.servers' = '<kafka-broker>',
'topic' = '<topic-name>',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset',
'connect.timeout' = '60s'
);
通过以上步骤,您可以逐步排查并解决SplitFetcher线程异常以及数据监听失败的问题。如果仍有疑问,请提供更多上下文信息(如完整代码、日志内容等),以便进一步分析。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

