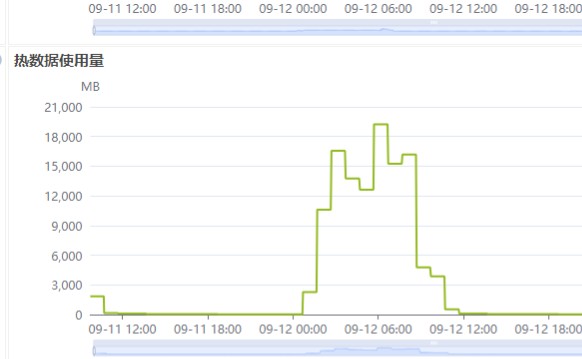
在云数据仓库 AnalyticDB for MySQL 数仓版中,热数据使用量的波动通常与以下场景相关。这些场景涉及热数据的存储、查询和计算操作,具体如下:
1. 实时写入和更新操作
- 当业务系统向 AnalyticDB 集群写入新数据时,这些数据默认会被存储为热数据。例如:
- 实时同步的日志数据、订单数据或监控数据。
- 数据通过 DTS(数据传输服务)或其他工具实时写入集群。
- 如果写入的数据量较大或写入频率较高,会导致热数据使用量增加。
2. 高频查询操作
- 热数据存储在高性能介质(如 SSD)上,主要用于支持高频查询和复杂分析任务。以下场景会显著使用热数据:
- 用户对最近一段时间内的数据进行频繁查询,例如最近 7 天或 30 天的业务数据。
- 查询涉及复杂的关联计算、聚合操作或即席分析。
- 查询操作越多,热数据的访问频率越高,可能导致热数据使用量波动。
3. 冷热数据迁移策略的影响
- AnalyticDB 支持冷热数据分层存储,按照时间分区或 TTL(Time to Live)策略将数据从热分区迁移到冷分区。在此过程中:
- 新生成的分区数据会优先存储为热数据。
- 在冷热数据迁移调度期间(如每日 23:00 到 23:59),部分数据可能暂时保留在热分区,导致热数据使用量波动。
- 如果业务表的分区策略发生变化(如新增分区或调整 TTL),也可能影响热数据的使用量。
4. 索引构建和维护
- AnalyticDB 会对写入的数据实时构建索引以加速查询性能。索引构建过程会占用热数据存储空间,尤其是在以下场景中:
- 写入峰值较高时,索引构建任务增多,导致热数据使用量上升。
- 数据更新或删除操作较多时,索引需要重新构建或调整。
5. 弹性模式下的资源分配
- 在数仓版弹性模式下,AnalyticDB 的热数据存储空间受一组弹性 IO 资源的限制(最大值为 8 TB)。如果热数据量接近该限制,系统可能会触发自动扩容或锁定机制,导致热数据使用量波动。
- 此外,当集群进行弹性伸缩(如扩容或缩容)时,热数据的分布和存储量也可能发生变化。
6. 多节点数据分布不均
- AnalyticDB 是分布式系统,数据分布在多个存储节点上。如果某些节点的热数据量较大,而其他节点较少,可能会导致整体热数据使用量的波动。
- 监控信息页面显示的热数据使用量是所有读写节点的磁盘数据使用量之和,因此单个节点的数据分布不均会影响整体统计结果。
7. 业务高峰期的影响
- 在业务高峰期,用户对近期数据的查询需求增加,热数据的访问频率和存储需求也会随之上升。例如:
- 智慧交通场景下,实时监控设备终端信息。
- 电商场景下,实时分析用户的订单和行为数据。
- 高峰期过后,热数据使用量可能会逐渐下降。
重要提醒
- 热数据存储成本较高:热数据存储在 SSD 上,费用高于冷数据存储(HDD 或 OSS)。建议根据业务需求合理配置冷热数据分离策略,降低存储成本。
- 监控热数据使用量:建议定期查看集群的热数据使用量和冷数据使用量,确保热数据量不超过一组弹性 IO 资源的最大限制(8 TB),避免集群锁定。
- 优化查询性能:对于高频查询的场景,可以通过索引优化、分区设计等手段提升查询效率,减少对热数据的依赖。
通过以上分析,您可以结合具体的业务场景和监控数据,进一步定位热数据使用量波动的原因,并采取相应的优化措施。