
Flink CDC采集的Mysql Binlog数据 序列化的时候 串列的?后端在修改表结构时 使用 了 add column after 指定列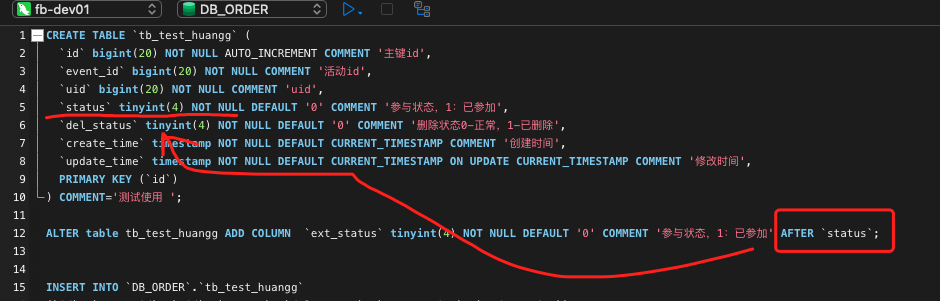
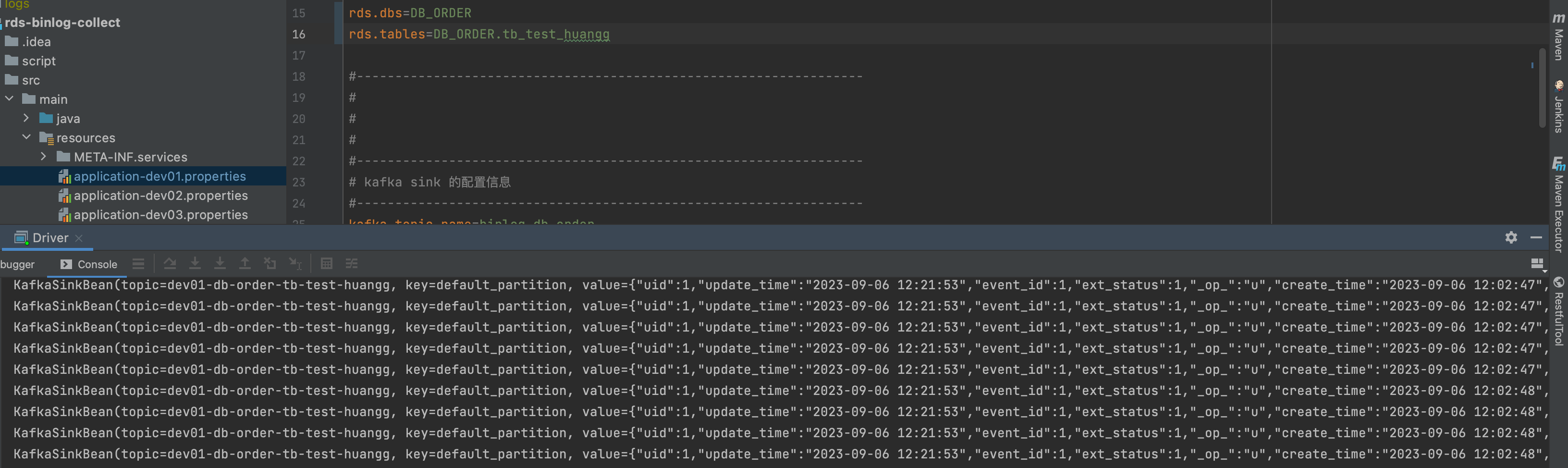
只采一张表 问题又还没有复现
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您的描述,Flink CDC在采集MySQL Binlog数据时,可能存在序列化问题,尤其是在后端修改表结构(例如使用ADD COLUMN AFTER指定列)的情况下。虽然目前问题尚未复现,但需要明确以下几点:
以下是针对该问题的详细解答和建议。
MySQL的Binlog格式对CDC作业的稳定性至关重要。如果Binlog格式为STATEMENT或MIXED,可能会导致数据解析失败或序列化问题。建议确保Binlog格式为ROW模式。
SHOW VARIABLES LIKE 'binlog_format';
SET GLOBAL binlog_format = 'ROW';
注意:修改Binlog格式可能需要重启MySQL服务,请提前评估影响。
在全量阶段或增量阶段发生表结构变更时,可能会导致作业报错或数据同步失败。以下是具体的处理建议:
全量阶段的表结构变更:
ADD COLUMN AFTER),可能会导致Schema不匹配,抛出NullPointerException等异常。增量阶段的表结构变更:
如果作业中包含多张MySQL源表,建议开启Source复用功能,以减少数据库连接数和Binlog读取压力。
开启Source复用:
SET 'table.optimizer.source-merge.enabled' = 'true';
注意事项:
SET 'sql-gateway.exec-plan.enabled' = 'false';
pipeline.operator-chaining设为false,否则会增加序列化和反序列化的开销。如果表结构变更后出现序列化问题,可能是由于下游表的Schema未及时更新。建议检查以下配置:
确保下游表支持Schema变更:
hg_binlog_event_type自动为每行数据设置准确的Flink RowKind类型。自定义序列化器:
serverTimeZone参数与MySQL服务器时区一致,避免时间戳字段的时区差异。为了提前发现潜在问题,建议启用以下监控和日志功能:
监控指标:
currentEmitEventTimeLag指标判断是否已完成全量数据同步。finish split response timeout异常。日志排查:
BinlogSplitReader is created日志,确认是否读取完全量数据。通过以上措施,可以有效降低表结构变更对Flink CDC作业的影响,并避免序列化问题的发生。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

