
ModelScope 这个报错是因为版本不对吗?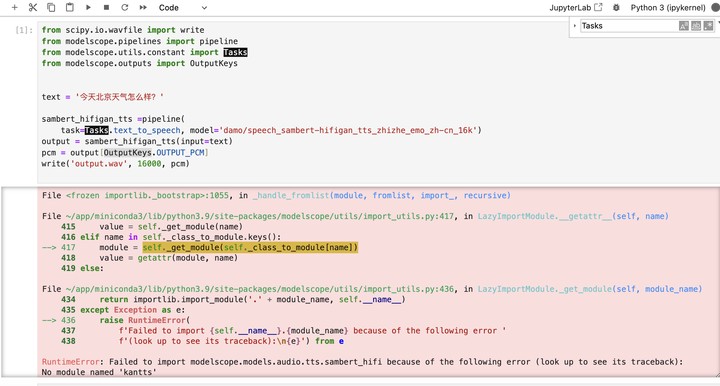
根据您提供的报错信息,虽然没有直接提及具体的错误内容,但结合知识库中的相关资料,可以推测出一些可能导致问题的原因以及解决方法。以下是详细的分析和建议:
ModelScope 的模型和服务部署对版本有严格的依赖关系。如果使用的模型版本、框架版本或依赖库版本不匹配,可能会导致报错。例如: - 在文档中提到,modelscope 的安装需要指定版本,如 pip install modelscope==1.12.0。 - 某些模型可能需要特定的 Python 版本(如 Python 3.7 或 3.8)或 CUDA 版本(如 CUDA 11.3.0)。
建议操作: - 确认当前环境中安装的 modelscope 版本是否符合要求。可以通过以下命令检查:
pip show modelscope
pip install modelscope==<目标版本>
在 ModelScope 中,每个模型都有唯一的 MODEL_ID 和对应的版本号。如果配置的 MODEL_ID 或版本号不正确,可能会导致服务无法正常加载模型。例如: - 文档中提到,部署时需要明确指定 MODEL_ID 和 REVISION 参数,如 ZhipuAI/chatglm2-6b 和 v1.0.2。 - 如果使用了不存在的模型 ID 或版本号,系统会报错。
建议操作: - 确认 MODEL_ID 和 REVISION 是否正确。可以在 ModelScope 官网查询目标模型的 ID 和版本号。 - 如果不确定,可以尝试使用默认推荐的模型和版本,例如:
MODEL_ID=ZhipuAI/chatglm2-6b
REVISION=v1.0.2
某些模型需要额外的访问令牌(ACCESS_TOKEN)才能下载或使用。如果未正确配置访问令牌,可能会导致权限不足的错误。例如: - 文档中提到,非公开模型需要配置 ACCESS_TOKEN 环境变量。 - 访问令牌可以在 ModelScope 官网首页获取。
建议操作: - 检查是否需要配置 ACCESS_TOKEN,并确保其值正确。例如:
export ACCESS_TOKEN=<您的访问令牌>
ACCESS_TOKEN 配置。大语言模型通常对 GPU 资源有较高要求。如果 GPU 显存不足或配置错误,可能会导致模型加载失败。例如: - 文档中提到,针对 7B 模型建议选择 GU30 系列机型,而更大的模型可能需要双卡机型或更大显存的机型。 - 对于 14B 及以上模型,建议使用 Ada 系列显卡,并预留至少 48G 显存。
建议操作: - 确认当前 GPU 资源是否满足模型需求。可以通过以下命令查看 GPU 使用情况:
nvidia-smi
除了上述原因外,还有一些其他可能导致报错的因素: - 依赖库缺失或版本冲突:某些模型可能需要额外的依赖库,如 torch、transformers 等。如果依赖库版本不匹配,可能会导致运行失败。 - 网络问题:如果模型文件较大,下载过程中可能会因网络不稳定导致失败。建议切换到稳定的网络环境重试。
建议操作: - 检查依赖库是否完整安装,并确保版本符合要求。例如:
pip install torch==1.14.0 transformers==4.37.0
根据上述分析,您可以按照以下步骤排查问题: 1. 确认 modelscope 和依赖库的版本是否正确。 2. 检查 MODEL_ID 和 REVISION 配置是否准确。 3. 确保环境变量(如 ACCESS_TOKEN)已正确配置。 4. 检查 GPU 资源是否满足模型需求。 5. 排查依赖库和网络问题。
如果问题仍未解决,请提供具体的报错信息,以便进一步分析和定位问题。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
