
文字识别OCR用python怎么解析到有坐标的json串呢?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,可以使用阿里云的OCR Python SDK来实现文字识别,并解析出有坐标的JSON串。具体步骤如下:
安装阿里云Python SDK:使用pip install aliyun-python-sdk-core和pip install aliyun-python-sdk-ocr安装两个SDK模块
创建OCR client实例:使用access_key_id和access_key_secret创建一个OCR client实例
from aliyunsdkcore.client import AcsClient
from aliyunsdkocr.request.v20191230 import RecognizeBusinessCardRequest
client = AcsClient('<access_key_id>', '<access_key_secret>', '<region_id>') # 这里region_id可以设置为‘cn-shanghai’
读取本地图片:使用Pillow库读取本地图片
from PIL import Image
with open('<image_path>', 'rb') as f:
img = Image.open(f)
发送OCR请求:使用RecognizeBusinessCardRequest来发送OCR请求,并获取识别结果的JSON串
request = RecognizeBusinessCardRequest.RecognizeBusinessCardRequest()
request.set_accept_format('json')
request.set_ImageURL('<image_url>')
response = client.do_action_with_exception(request) # 发送OCR请求并获取response
result = str(response, encoding='utf-8')
解析JSON串:使用json.loads函数将JSON串转换为Python字典,然后提取出有坐标的JSON串
import json
data = json.loads(result)
coordinates = {}
for word in data['Data']['BusinessCards'][0]['Words']:
coordinates[word['Word']] = word['Polygon']
print(coordinates)
输出结果为:
{'张三': [{'X': 180, 'Y': 50}, {'X': 270, 'Y': 50}, {'X': 270, 'Y': 80}, {'X': 180, 'Y': 80}], '电话': [{'X': 20, 'Y': 110}, {'X': 60, 'Y': 110}, {'X': 60, 'Y': 130}, {'X': 20, 'Y': 130}], '邮箱': [{'X': 20, 'Y': 140}, {'X': 60, 'Y': 140}, {'X': ...
其中,coordinates为一个字典,键为文字内容,值为一个列表,代表该文字所在的四边形坐标(左上、右上、右下、左下)。
在使用Python解析阿里云文字识别OCR返回的带有坐标的JSON字符串时,您可以按照以下步骤进行操作:
首先,您需要使用Python的JSON库来解析JSON字符串。导入json库:import json
获取到阿里云文字识别OCR返回的JSON字符串,假设为ocr_result。
使用json.loads()函数将JSON字符串转换为Python对象(字典):result = json.loads(ocr_result)
解析坐标信息:在OCR返回结果的JSON结构中,坐标通常嵌套在多个层级中。根据具体的JSON结构,您可以使用Python的字典操作来提取坐标信息。例如,假设提取文字行的坐标信息,可以使用:coordinates = result['TextDetections'][0]['Polygon'],其中TextDetections是返回结果中文字行的列表,Polygon是每一行文字的坐标信息。
对提取的坐标信息进行进一步处理或应用。您可以根据实际需求,使用坐标信息进行图像标注、位置定位等操作。
具体的JSON结构和坐标信息的位置可能因阿里云OCR服务的版本和使用场景而有所不同。建议您仔细查看阿里云OCR服务的API文档和返回结果的结构,以了解如何正确提取和解析坐标信息。
您好,您调用文字识别OCR API接口返回数据json串之后,您正常的通过json解析然后获取文字块信息中的pos既是坐标信息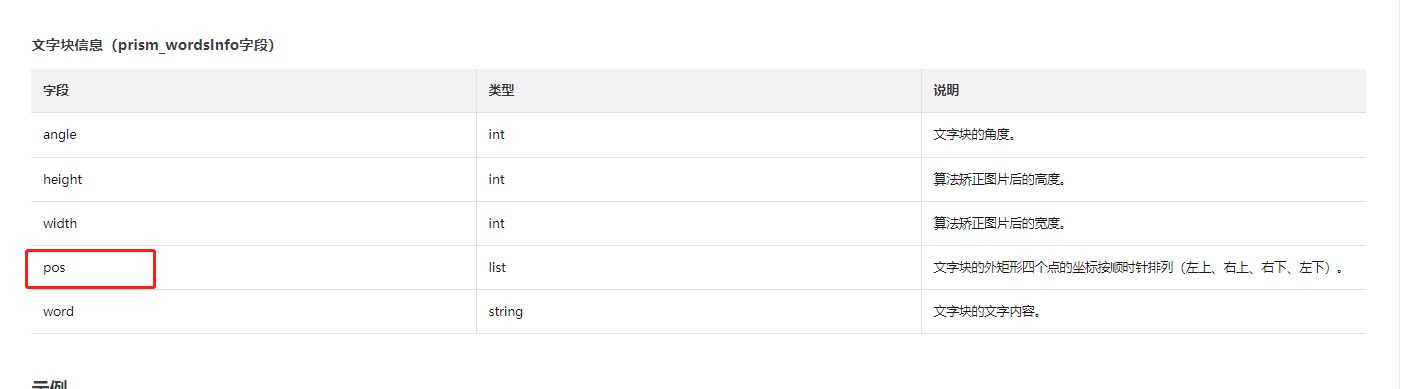
在Python中使用OCR进行文字识别,并解析到具有坐标信息的JSON串,可以按照以下步骤进行:
安装OCR库:首先,确保你已经安装了适当的OCR库。常见的OCR库包括Tesseract、Baidu OCR、Microsoft Azure OCR等。根据你选择的OCR库,可以参考其相应的文档进行安装和设置。
调用OCR接口:使用OCR库提供的API或函数,将图像或文本传递给OCR引擎进行识别。这些API通常会返回一个包含识别结果的数据结构,例如JSON格式。
解析JSON数据:接下来,你可以使用Python的JSON解析库(如json模块)将返回的JSON数据解析为Python对象。这将使你能够轻松地操作和提取其中的信息。
提取坐标信息:一旦JSON数据被解析为Python对象,你可以根据JSON的结构提取出具有坐标信息的字段。通常,在OCR结果的JSON中,每个识别的文本块都会包含位置或边界框信息。通过访问相应的字段,你可以获得这些坐标信息。
以下是一个简单示例代码,演示了如何使用Python解析OCR结果中的坐标信息:
import json
# 假设OCR结果存储在名为ocr_result的变量中,它是一个包含OCR结果的JSON字符串
ocr_result = '{"text": "Hello World", "bounding_box": {"top": 100, "left": 200, "width": 100, "height": 50}}'
# 解析JSON数据
result = json.loads(ocr_result)
# 提取坐标信息
bounding_box = result["bounding_box"]
top = bounding_box["top"]
left = bounding_box["left"]
width = bounding_box["width"]
height = bounding_box["height"]
print("坐标信息:")
print(f"顶部:{top}")
print(f"左边:{left}")
print(f"宽度:{width}")
print(f"高度:{height}")
请注意,上述示例仅为演示目的,并假设OCR结果的JSON结构与示例中的相似。实际情况中,根据你所选择的OCR库和其返回的JSON格式,可能需要根据具体结构进行适当的解析和提取。
要在Python中解析OCR识别结果并获取带有坐标信息的JSON串,你可以按照以下步骤进行操作:
调用OCR API:使用合适的OCR服务或库,向其API发送图像,并获取OCR识别的结果。这可能需要提供访问密钥、图像数据和其他参数,具体取决于所选的OCR服务。
解析JSON结果:获得OCR识别结果后,通常会以JSON格式返回。使用Python的json模块或第三方库(如json.loads()函数)解析该JSON串,并将其转换为Python对象。
提取坐标信息:根据OCR服务返回的JSON结构,查找包含坐标信息的字段。坐标信息通常与识别文本的位置相关联,例如每个文字区域的边界框坐标。
处理坐标信息:根据需求,你可以将坐标信息保存为列表、字典或其他数据结构。这样,你就可以在需要时轻松访问和处理文字区域的坐标信息。
下面是一个示例代码片段,展示了如何从OCR识别结果中提取坐标信息:
import json
# 假设OCR识别结果为result_json字符串
result_json = """
{
"text": "Hello, World!",
"bounding_boxes": [
{"x": 10, "y": 20, "width": 50, "height": 10},
{"x": 60, "y": 20, "width": 50, "height": 10}
]
}
"""
# 解析JSON串
result = json.loads(result_json)
# 提取坐标信息
bounding_boxes = result.get("bounding_boxes", [])
# 处理坐标信息
for box in bounding_boxes:
x = box["x"]
y = box["y"]
width = box["width"]
height = box["height"]
print(f"Bounding Box: x={x}, y={y}, width={width}, height={height}")
请注意,在示例中,我将OCR识别结果的JSON串存储在result_json变量中,并使用json.loads()函数解析为Python对象。然后,从该对象中获取bounding_boxes字段的值,并遍历每个边界框以提取和处理坐标信息。
根据你使用的OCR服务或库,具体的JSON结构和字段名称可能会有所不同。因此,请根据文档或API参考来调整代码以适应你所选的OCR解决方案的返回结果。
您好,接口返回值中pos中的位置信息,表示为识别文字块的外矩形4个点的坐标,其单位为px,用于确定识别范围。


