Flink CDC中维表数据开启缓存怎么开启?不是那个ttl吗?我看那个ttl默认就是开启缓存的呀。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
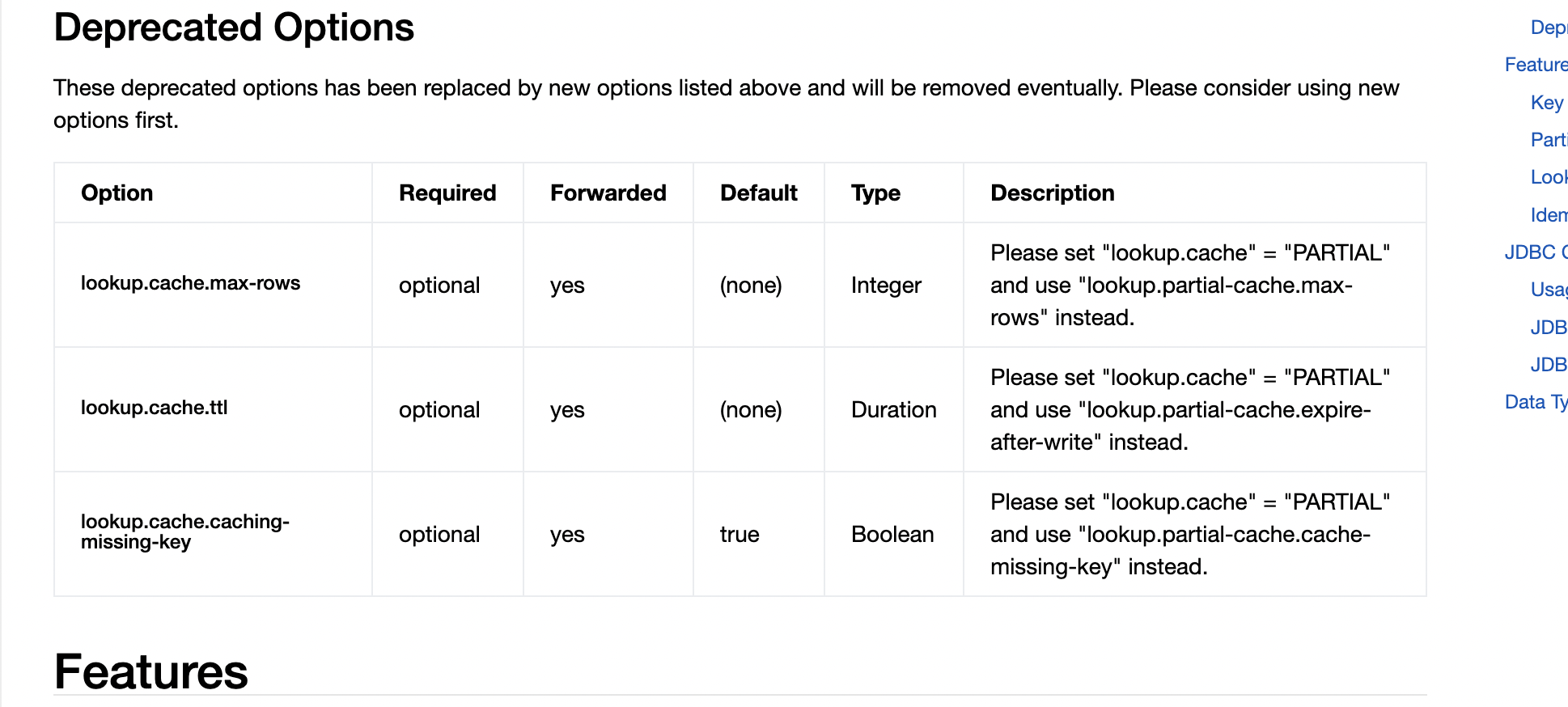
在 Flink CDC 中,维表数据的缓存是通过配置 Flink 的状态后端来实现的,并不是通过 TTL(Time-To-Live)参数来开启。
默认情况下,Flink CDC 使用的状态后端是 RocksDB。RocksDB 可以配置用于维表数据的内存缓存,以提高查询性能。这个缓存机制在 Flink 中被称为 "State Backend Cache" 或 "Managed Memory".
要开启维表数据的缓存,你可以按照以下步骤进行配置:
在 Flink 的配置文件(如 flink-conf.yaml)中添加以下配置项:
taskmanager.memory.managed.size: <缓存大小>
<缓存大小> 是指分配给维表数据缓存的内存大小,可以使用合适的单位(例如 MB、GB)。请根据你的需求和系统资源来设置。
确保 Flink 的状态后端配置为 RocksDB。可以在 Flink 的配置文件中检查以下配置项:
state.backend: rocksdb
如果没有设置,请添加该配置项,并设置为 rocksdb。
重新启动 Flink 作业或者任务,使配置生效。
经过上述配置,Flink CDC 将会在 RocksDB 中分配一部分内存作为维表数据的缓存。这样,在查询维表数据时,Flink 将首先尝试从缓存中获取结果,从而加速查询响应时间。
在Flink CDC中,为了提高维表数据的查询效率,可以开启维表数据的缓存功能。Flink CDC支持两种类型的维表数据缓存:LRU Cache和TTL Cache。
LRU Cache使用最近最少使用算法来管理缓存中的数据,当缓存空间不足时,会淘汰最近最少使用的数据。TTL Cache使用时限算法来管理缓存中的数据,在指定的时间窗口内,缓存中的数据不会被淘汰。
在Flink CDC中,开启维表数据的缓存功能可以通过设置TableSource的构造函数中的lookupOptions参数来实现。例如:
java
Copy
// 创建MySQL CDC数据源
JdbcTableSource dimTable = JdbcTableSource.builder()
.setDrivername("com.mysql.jdbc.Driver")
.setDBUrl("jdbc:mysql://localhost:3306/test")
.setUsername("root")
.setPassword("root")
.setTableName("dim_table")
.setLookupOptions(lookupOptions().setCacheExpireMs(300000))
.build();
在上述示例中,通过调用lookupOptions()方法来创建一个LookupOptions对象,并通过setCacheExpireMs()方法设置TTL缓存的过期时间为5分钟(300000毫秒)。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。