
DataWorks中是这个原因吗?
DataWorks中是这个原因吗?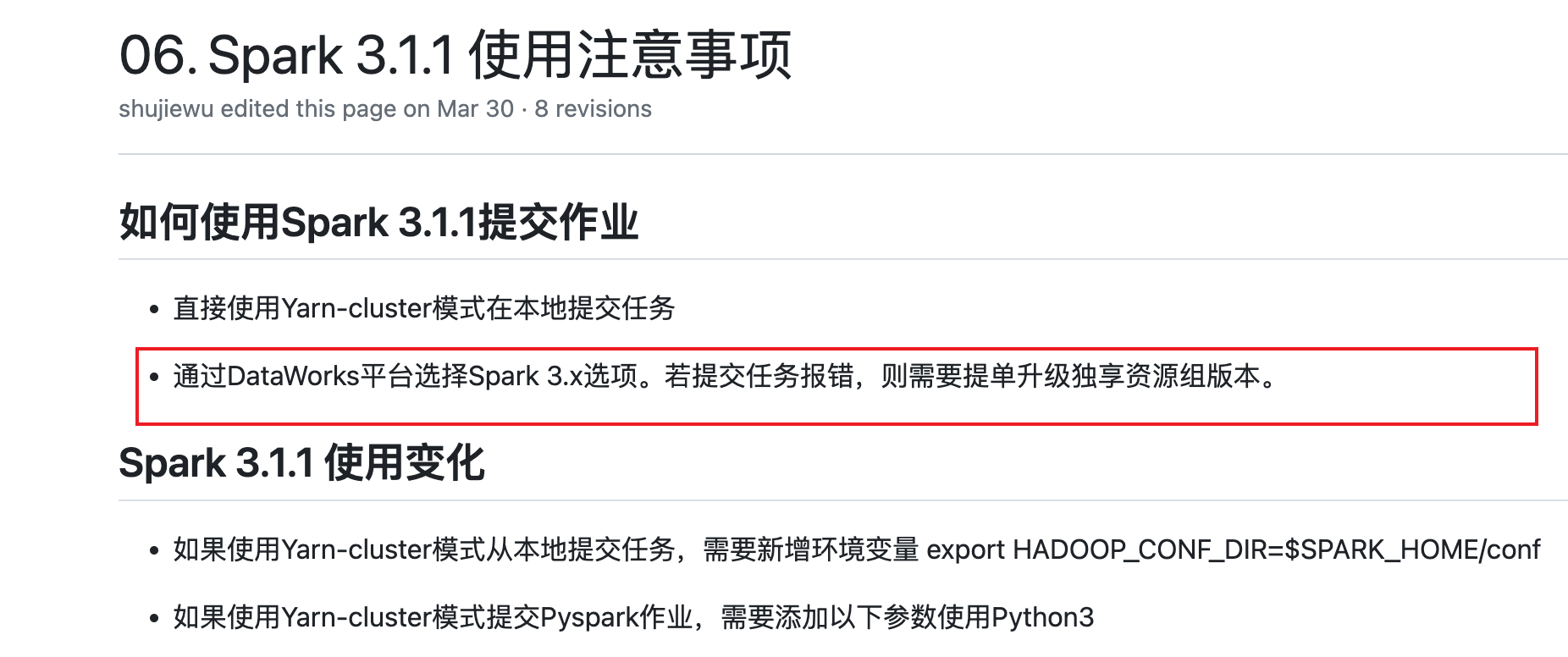
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
北京阿里云ACE会长
要使用 Spark 3.1.1 提交作业,您可以采用以下步骤:
确认您的 Spark 3.1.1 版本已经安装并配置好了相关环境,例如 Java、Scala 等。
编写 Spark 3.1.1 作业代码,并将其打包成 jar 包。
在本地通过 Yarn-cluster 模式提交任务,可以使用以下命令:
angelscript
Copy
spark-submit --class --master yarn --deploy-mode cluster
其中, 表示您的主类名, 表示您的应用程序 jar 包路径, 表示您的应用程序参数。如果您使用的是 DataWorks 平台,可以选择 Spark 3.x 选项,并在作业配置中选择相关的参数和配置,例如作业名称、主类名、应用程序 jar 包路径、应用程序参数等。然后点击“提交”按钮,将作业提交到集群中运行。
2023-07-30 15:49:25赞同 展开评论 -
-
应该是这个原因了 mc spark文档有说明 dw这边没有加上 我也反馈一下 辛苦也发一下报错日志的完整文本https://help.aliyun.com/zh/dataworks/user-guide/create-an-odps-spark-node?spm=a2c4g.11186623.0.i3,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
2023-07-25 20:08:18赞同 展开评论


DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。