
DataWorks上游节点是视图如何设置依赖关系?
DataWorks上游节点是视图如何设置依赖关系?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
北京阿里云ACE会长
在 DataWorks 中,如果上游节点是视图,需要按照以下步骤设置节点之间的依赖关系:
在 DataWorks 中,创建视图节点,并编写视图的 SQL 语句。
在下游节点中,选择需要依赖该视图的节点,并右键单击该节点,在弹出的菜单中选择“新增依赖”。
在“新增依赖”对话框中,选择需要依赖的视图节点,点击“确定”按钮。
保存依赖关系后,您可以在依赖关系图中查看节点之间的关系。需要注意的是,视图节点可以作为下游节点的依赖节点,但不能作为上游节点的依赖节点。
2023-07-30 16:24:26赞同 展开评论 -
在DataWorks中,设置上游节点是视图的依赖关系可以按照以下步骤进行:
登录DataWorks控制台,并进入相应的项目空间。
在项目空间中找到对应的工作流程(或任务),并打开编辑模式。
在编辑模式下,找到需要设置依赖关系的目标节点(即下游节点)。
右键点击目标节点,在弹出的菜单中选择“设置上游”选项。
在设置上游菜单中,选择需要作为上游的节点。在这种情况下,选择需要作为上游的视图节点。
当你选择了视图节点作为上游时,会出现一个弹窗用于选择具体的上游视图。
在弹窗中,选择要设置为上游的视图节点,并点击确定。
完成上述操作后,目标节点就会与所选的视图节点建立依赖关系。
2023-07-26 21:38:23赞同 展开评论 -
依赖的上游节点怎么填?
A:◇ 父节点输出名称:即这里需要填的是父节点输出名称,以此来关联父节点达到调度父子关系。可以手动添加,也可以从代码解析。这个节点输出名称填写后会自动解析到父节点的名称和id。若解析不到说明不存在这个输出名称,也就是没有一个节点的输出名称是这个,任务是不能依赖不存在的节点,所以这样的节点不可以提交.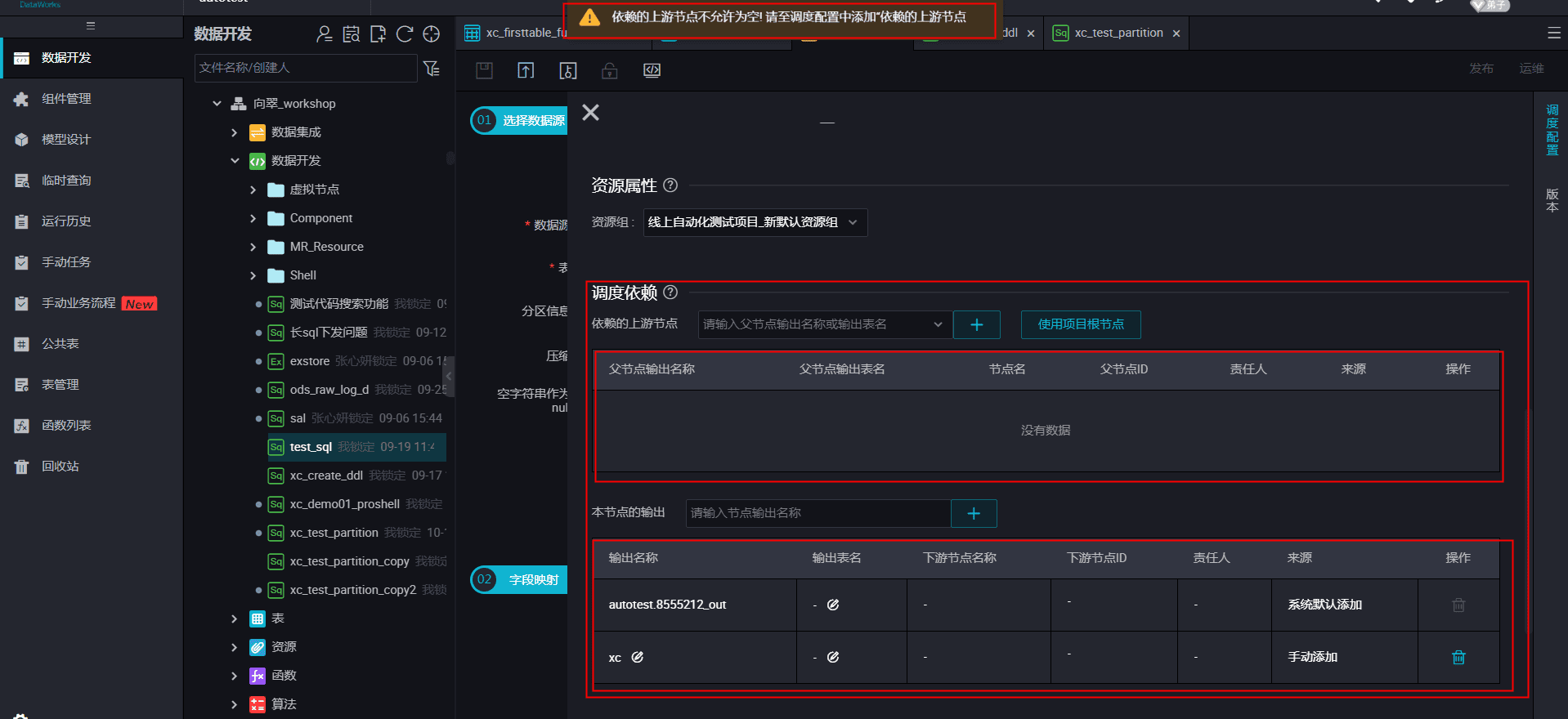
① 有节点依赖关系的通过节点输出名称挂上节点间的依赖关系。(注意:挂上依赖后,依赖的节点将影响本节点的实际运行时间,所有依赖的节点运行成功以后本节点才会运行,相关语料回复机器人:任务未运行)
② 没有节点依赖关系的将任务挂在项目根节点上,
面板中选择“使用项目根节点”。
参考: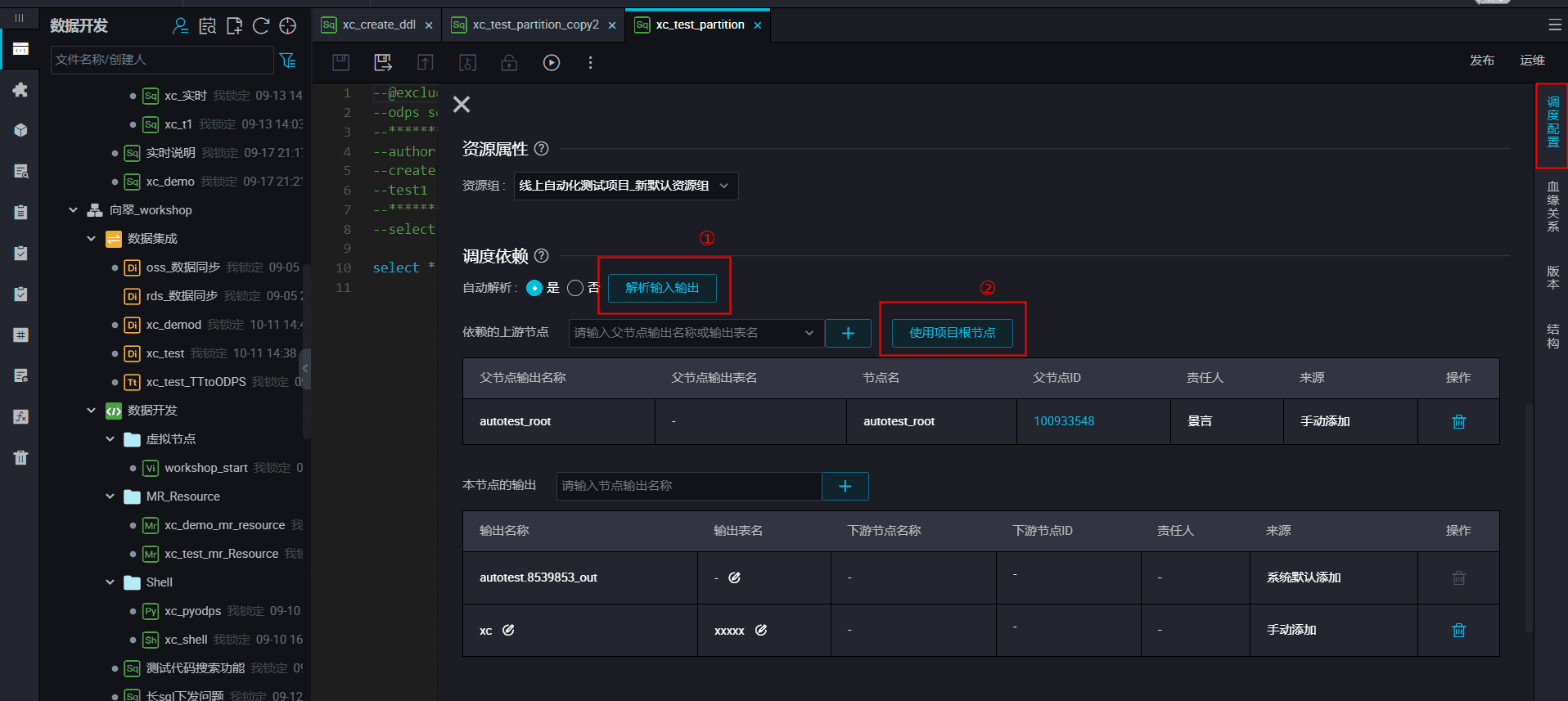
注意:如果自动解析出了不需要依赖的节点,请在代码区右键 删除输入 --@exclude_input=
具体操作回复机器人:删除输入,此回答整理自钉群“DataWorks交流群(答疑@机器人)”2023-07-25 19:08:07赞同 展开评论


DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。