
DataWorks使用MaxCompute分析IP来源最佳实践编写UDF函数?
DataWorks使用MaxCompute分析IP来源最佳实践编写UDF函数?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
北京阿里云ACE会长
当在DataWorks中使用MaxCompute进行IP来源分析时,可以使用UDF(User-Defined Function)函数来实现自定义的IP解析逻辑。以下是一个编写UDF函数来解析IP来源的最佳实践:
准备IP库数据:首先,需要准备一份包含IP地址范围和对应地理位置的IP库数据。可以使用第三方的IP库数据,或者使用公开的IP地址库。
创建MaxCompute表:在MaxCompute中创建一个表,用于存储IP库数据。表的结构可以包含IP起始地址、IP结束地址和对应的地理位置信息。可以使用MaxCompute的CREATE TABLE语句创建表,并将IP库数据导入到该表中。
编写UDF函数:在DataWorks中,创建一个UDF函数,用于解析IP来源。UDF函数可以使用Java或Python编写。以下是一个示例的Java UDF函数的伪代码:
java
Copy
public class IPSourceUDF extends UDF {
private static Map ipLibrary;public String evaluate(String ip) { // 初始化IP库 if (ipLibrary == null) { loadIPLibrary(); } // 解析IP来源 String source = ipLibrary.get(ip); return source != null ? source : "Unknown"; } private void loadIPLibrary() { // 从MaxCompute表中加载IP库数据到内存 // 使用MaxCompute的TableReader或TableAPI等方法读取表数据,并构建IP库的内存映射 // 将IP地址范围和对应的地理位置信息存储到ipLibrary变量中 }}
在上述代码中,evaluate()方法接收一个IP地址作为输入,并返回解析后的IP来源信息。loadIPLibrary()方法用于从MaxCompute表中加载IP库数据到内存。打包和上传函数:将编写好的UDF函数打包成JAR文件,并上传到MaxCompute项目中的资源库。可以使用DataWorks提供的资源管理功能来上传JAR文件。
创建函数和引用资源:在MaxCompute中,创建UDF函数,并引用上传的JAR文件作为函数的资源。
使用UDF函数:在MaxCompute的SQL语句中,可以使用已创建的UDF函数来解析IP来源。例如:
sql
Copy
SELECT ip, IPSourceUDF(ip) AS source FROM your_table;
在查询中,使用IPSourceUDF函数对IP字段进行解析,并将结果命名为source。2023-07-30 16:47:41赞同 展开评论 -
在DataWorks中使用MaxCompute分析IP来源的最佳实践是编写一个自定义函数(UDF)来解析IP地址并获取其来源信息。以下是一般的步骤和建议:
准备IP数据:首先,准备包含IP地址的数据集或表。
编写UDF函数:使用Java或Python等编程语言,编写一个自定义函数(UDF),该函数接收IP地址作为输入,并返回IP来源信息。
打包和上传UDF函数:将编写好的UDF函数打包成jar文件,并将其上传到MaxCompute项目中。
创建UDF函数:在MaxCompute中创建UDF函数,将上传的jar文件注册为MaxCompute函数。
使用UDF函数:在MaxCompute的查询语句中,使用你创建的UDF函数来解析IP地址,并获取其来源信息。
2023-07-26 21:47:25赞同 展开评论 -
通过编写Python UDF,将点号分割的IP地址转化为整数类型的IP地址,本示例使用DataWorks的PyODPS完成。详情请参见创建PyODPS 2节点。进入数据开发页面。登录DataWorks控制台。在左侧导航栏,单击工作空间列表。单击相应工作空间后的进入数据开发。新建Python资源。右键单击业务流程,选择新建 > MaxCompute > 资源 > Python。在新建资源对话框中,填写资源名称,并勾选上传为ODPS资源,单击确定。在Python资源中输入如下代码。from odps.udf import annotate@annotate("string->bigint")class ipint(object):def evaluate(self, ip):try:return reduce(lambda x, y: (x << 8) + y, map(int, ip.split('.')))except:return 0单击提交。新建函数。右键单击已创建的业务流程,选择新建 > MaxCompute > 函数。在新建函数对话框中,输入函数名称,单击提交。说明 如果绑定了多个MaxCompute引擎,则需要选择MaxCompute引擎实例。在函数的编辑页面,配置各项参数。
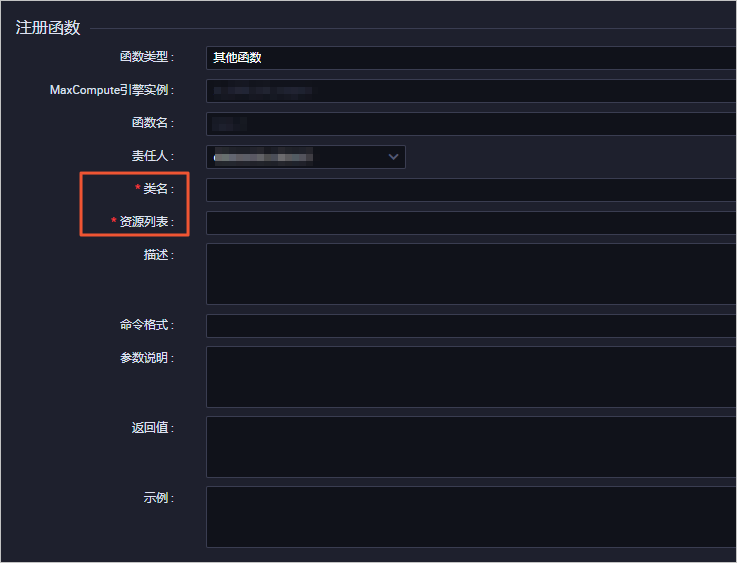
参数 描述
函数类型 选择函数类型,包括数学运算函数、聚合函数、字符串处理函数、日期函数、窗口函数和其他函数。
MaxCompute引擎实例 默认不可以修改。
函数名 UDF函数名,即SQL中引用该函数所使用的名称。需要全局唯一,且注册函数后不支持修改。
责任人 默认显示。
类名 实现UDF的主类名,必填。
资源列表 完整的文件名称,支持模糊匹配查找本工作空间中已添加的资源,必填。 多个文件之间,使用英文逗号(,)分隔。
描述 针对当前UDF作用的简单描述。
命令格式 该UDF的具体使用方法示例,例如test。
参数说明 支持输入的参数类型以及返回参数类型的具体说明。
返回值 返回值,例如1,非必填项。
示例 函数中的示例,非必填项。单击工具栏中的//help-static-aliyun-doc.aliyuncs
https://help.aliyun.com/document_detail/98399.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”2023-07-25 18:20:11赞同 展开评论


MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。