
大数据计算MaxCompute pyodps DataFrame可以分批获取数据吗?比如每批读10000行
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 MaxCompute 中,使用 pyodps 的 DataFrame API 可以方便地进行数据处理和分析。如果您需要分批获取数据,可以使用 DataFrame 的 limit 和 offset 方法,将数据分批读取。
具体来说,您可以使用如下代码实现分批读取数据:
python
Copy
from odps import ODPS
from odps.df import DataFrame
odps = ODPS(access_id='', secret_access_key='', project='', endpoint='')
table = odps.get_table('')
batch_size = 1000
total_rows = table.count().execute()
for offset in range(0, total_rows, batch_size):
# 读取数据
df = DataFrame(odps=odps, table='<table-name>').limit(batch_size).offset(offset)
# 处理数据
# ...
在上述代码中,我们首先连接 MaxCompute,然后加载数据表。接着,我们设置每批读取的数据量为 1000 行,并获取数据表的总行数。最后,我们使用 limit 和 offset 方法分批读取数据,并进行数据处理。
是的,您可以使用MaxCompute的pyodps库进行分批获取数据。在pyodps中,DataFrame对象具有limit方法,可以用于限制每个批次返回的行数。
以下是一个示例代码,展示了如何使用limit方法来分批获取数据:
from odps import ODPS
# 连接到MaxCompute项目
odps = ODPS(project='<project_name>', access_id='<access_id>', secret_access_key='<secret_access_key>')
# 获取表数据
table = odps.get_table('<table_name>')
df = table.to_df()
batch_size = 1000 # 每批返回的行数
offset = 0
while True:
batch_df = df.limit(batch_size).offset(offset).to_pandas() # 分批获取数据并转为pandas DataFrame
if batch_df.empty:
break
# 处理当前批次的数据
# ...
offset += batch_size
在上述示例中,我们通过设置batch_size来控制每个批次返回的行数。通过不断调整offset参数,可以在循环中逐批获取数据,直到所有数据都被处理完毕。
具体是指怎么样的分区取数据?PyODPS通过DataFrame(o.get_table('table_name'))获取到DataFrame之后,后边直接执行处理逻辑就可以了。也可以单分区获取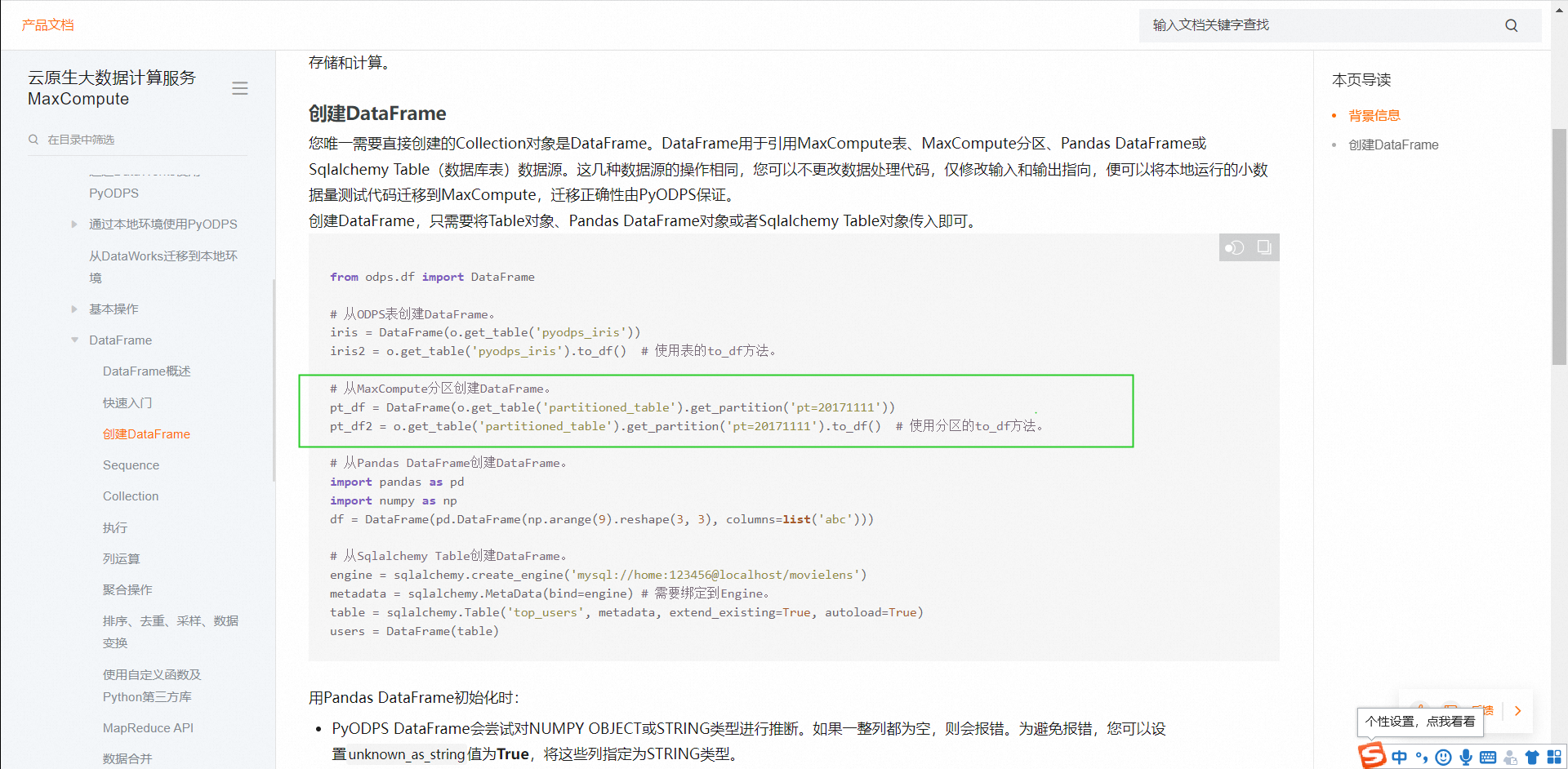
DataFrame应该是不能,DataFrame获取的时候没有参数可以控制;
可以用PyODPS直接执行SQL,加上limit1000的限制
https://help.aliyun.com/zh/maxcompute/user-guide/sql?spm=a2c4g.11186623.0.0.1c9057fd0GgIaX,此回答整理自钉群“MaxCompute开发者社区2群”
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


