
flinkcdc,用哪个序列化器,才能拿到binlog里面的数据操作时间?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 Flink CDC 中,可以使用自定义的反序列化器来解析 CDC 数据源的数据,以获取 binlog 中的数据操作时间。根据您的需求,可以使用不同的反序列化器来实现。
如果您使用的是 Flink CDC 内置的反序列化器,可以通过在反序列化器中添加对应的字段,来获取 binlog 中的数据操作时间。例如,如果您使用的是 MySQL CDC 数据源,并且使用了内置的 MySQLRecordDeserializationSchema,可以在 schema 中增加对应的字段来获取 binlog 中的数据操作时间。示例代码如下:
java
Copy
public class MyRecordDeserializationSchema implements DebeziumDeserializationSchema {
@Override
public void deserialize(SourceRecord sourceRecord, Collector<MyRecord> collector) throws Exception {
Struct value = (Struct) sourceRecord.value();
String id = value.getString("id");
String name = value.getString("name");
int age = value.getInt32("age");
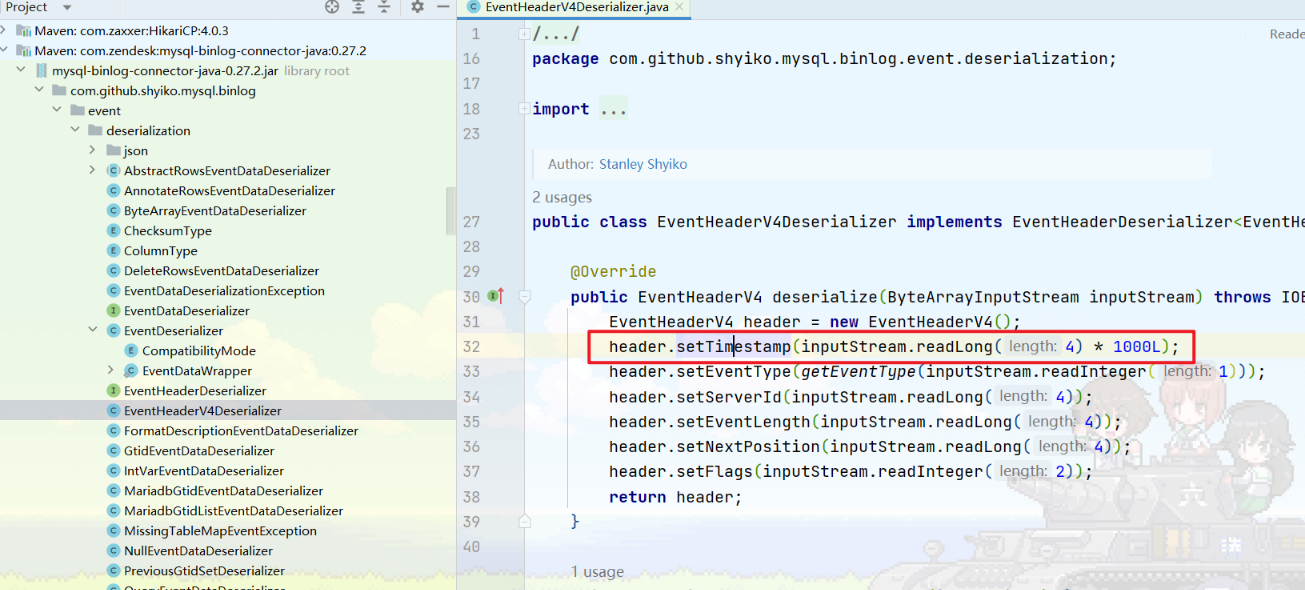
long timestamp = sourceRecord.timestamp(); // 获取 binlog 中的数据操作时间
collector.collect(new MyRecord(id, name, age, timestamp));
}
@Override
public TypeInformation<MyRecord> getProducedType() {
return TypeInformation.of(MyRecord.class);
}
}
在这个例子中,使用 sourceRecord.timestamp() 方法来获取 binlog 中的数据操作时间,并将其添加到 MyRecord 对象中。这样,在 Flink 程序中就可以获取到从 CDC 数据源中读取的每条数据的操作时间。
直接把这个mysqlsource输出
flink-connector-mysql-cdc包自带。

这样启动拿到的就是最开始binlog了,你试试这样启动,你就能看到差异了。
此回答整理至钉群“Flink CDC 社区”。"
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


