
文字识别OCR中,请问路径该怎么写?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您好,根据官方文档来看文字识别OCR支持图片Url链接或者body图片二进制文件,不支持将本地路径的文件直接读取,您可以将本地文件上传到对象存储OSS,然后获取请求地址后作为Url参数来调用。
第一应该是汉语的问题,第二应该是路径本身写错了,直接复制一下先试试,不行再改汉语
在阿里云文字识别OCR中,路径的写法通常取决于具体的使用情况。以下是一些常见的路径写法示例:
本地文件路径:如果您要识别的文件位于本地计算机上,可以使用完整的文件路径。例如:/home/user/Documents/image.jpg。
网络文件路径:如果您要识别的文件位于网络上,可以使用URL路径。例如:https://example.com/image.jpg。
对象存储路径:如果您使用的是阿里云对象存储(OSS)来存储文件,路径可以使用OSS提供的规范的路径格式。例如:oss://bucketname/objectname。
需要注意的是,路径的写法可能会根据具体的SDK或API有所不同。在使用阿里云文字识别OCR时,请参考相应的文档或示例代码获取准确的路径写法。
应该替换为您要识别的图片文件的路径,例如/path/to/your/image.png。
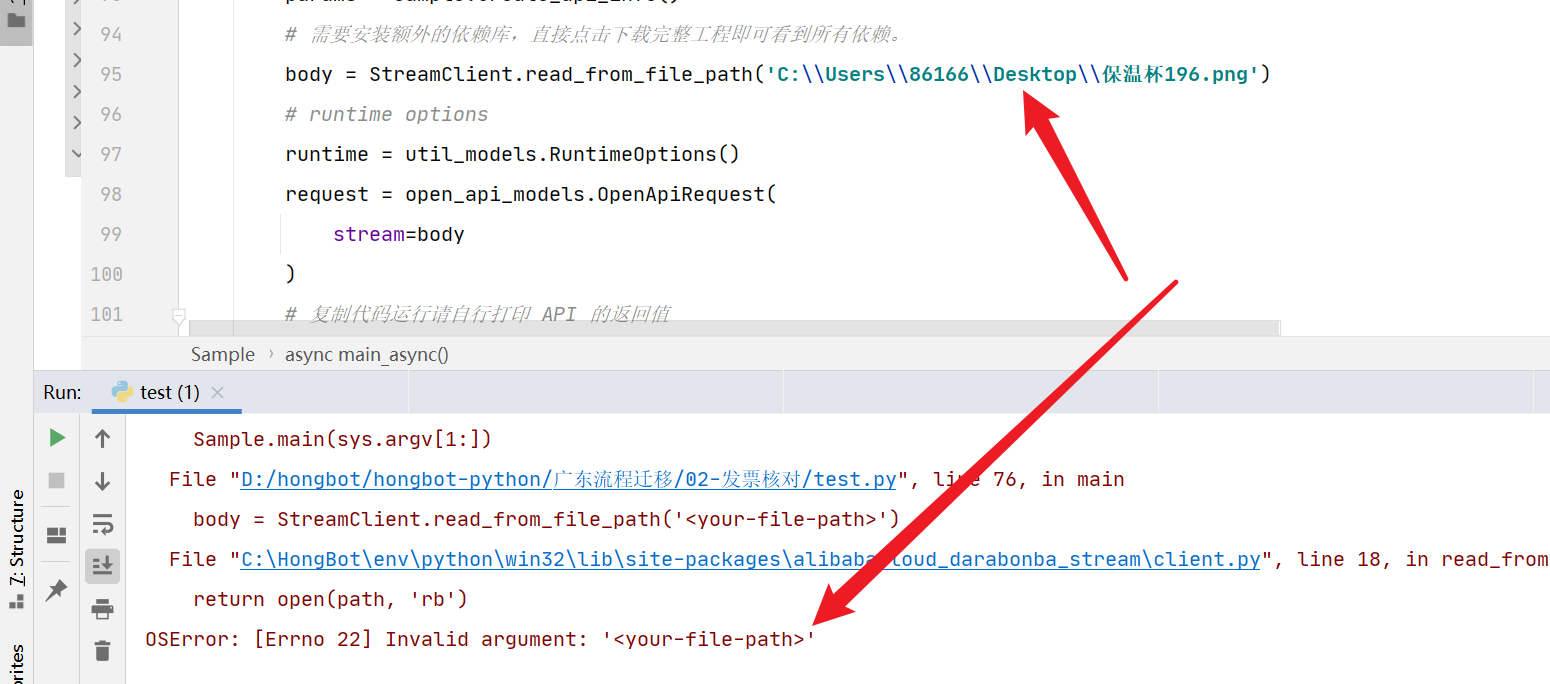
需要注意的是,文件路径应该根据您的实际情况进行调整,确保文件路径的正确性和存在性。如果您在Windows系统中使用反斜杠作为路径分隔符,需要注意将反斜杠进行转义,例如C:\path\to\your\image.png。
如果您仍然遇到路径无效或文件不存在的错误,建议您检查文件路径是否正确,并确保您有足够的权限访问文件。
根据您提供的错误信息,这是一个与文件路径相关的错误。在给定的代码行中,可能存在一些问题导致无效的文件路径。
从错误消息来看,似乎存在一个拼写错误和缺少路径分隔符的问题。请注意以下几点:
拼写错误:确保您提供的文件路径没有拼写错误,并且与实际的文件路径相匹配。
路径分隔符:根据操作系统的不同,确保使用正确的路径分隔符(斜杠 / 或反斜杠 \)。您提供的代码行中似乎缺少了路径分隔符。
根据您提供的代码行 open(path . 'rb'),我发现其中存在一个错误。应该使用字符串连接操作符 + 来连接路径和文件名,而不是使用点号 .。另外,确保在路径和文件名之间添加适当的路径分隔符。
以下是一个示例,展示了如何正确拼接文件路径:
import os
file_path = os.path.join(path, 'your-file-name')
with open(file_path, 'rb') as file:
# 执行文件操作
请将 path 替换为您要使用的实际文件路径,并将 'your-file-name' 替换为实际的文件名。使用 os.path.join() 函数可以确保正确处理路径分隔符,以避免路径错误。


