
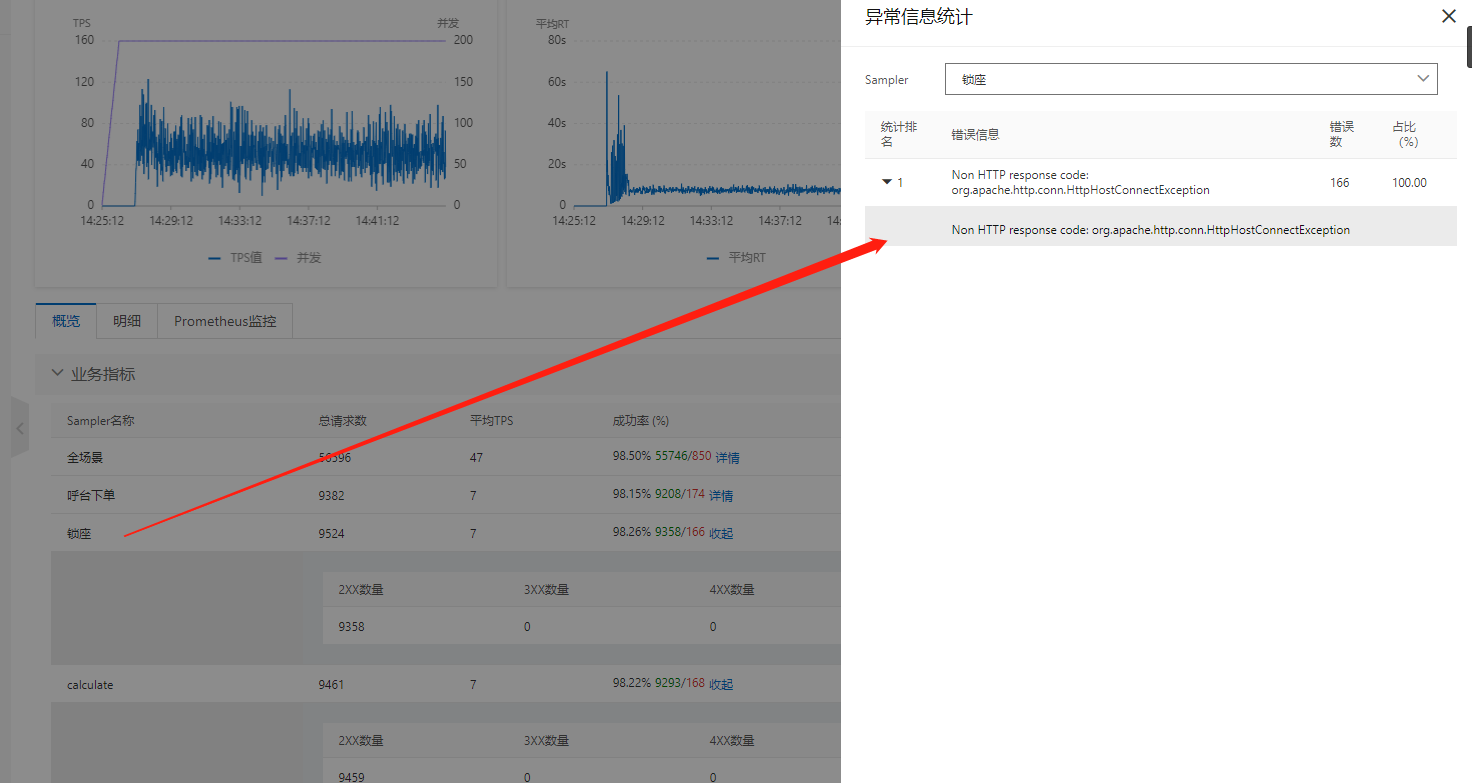
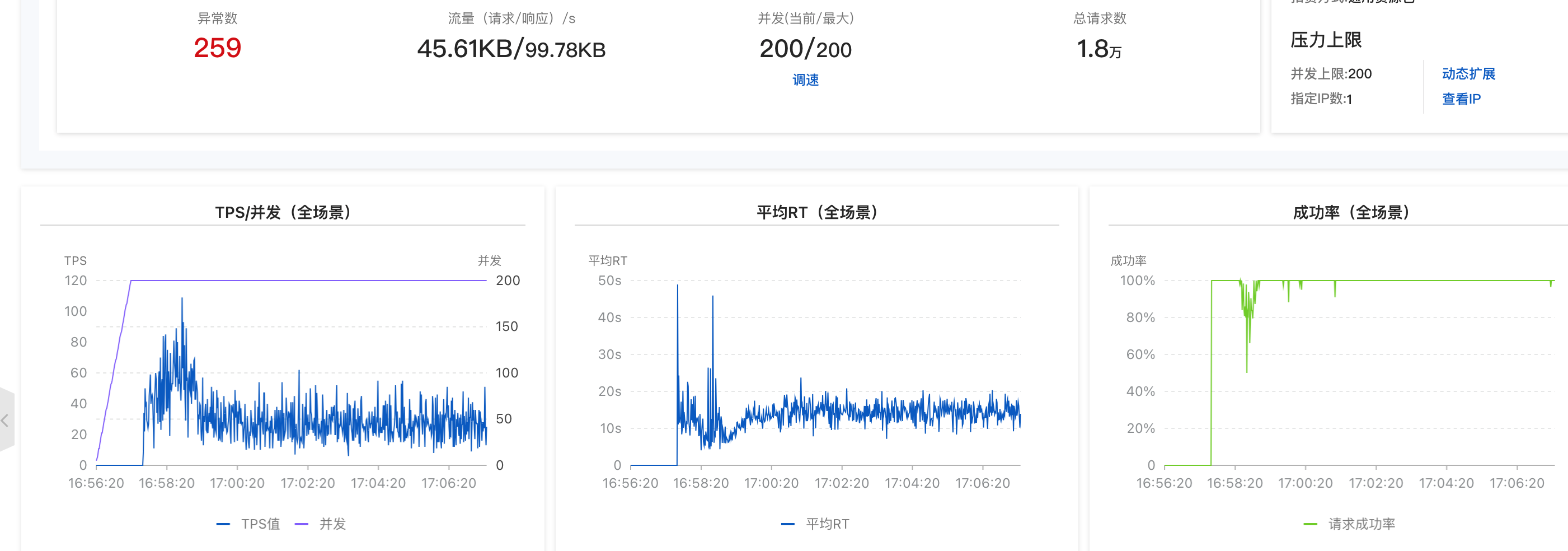
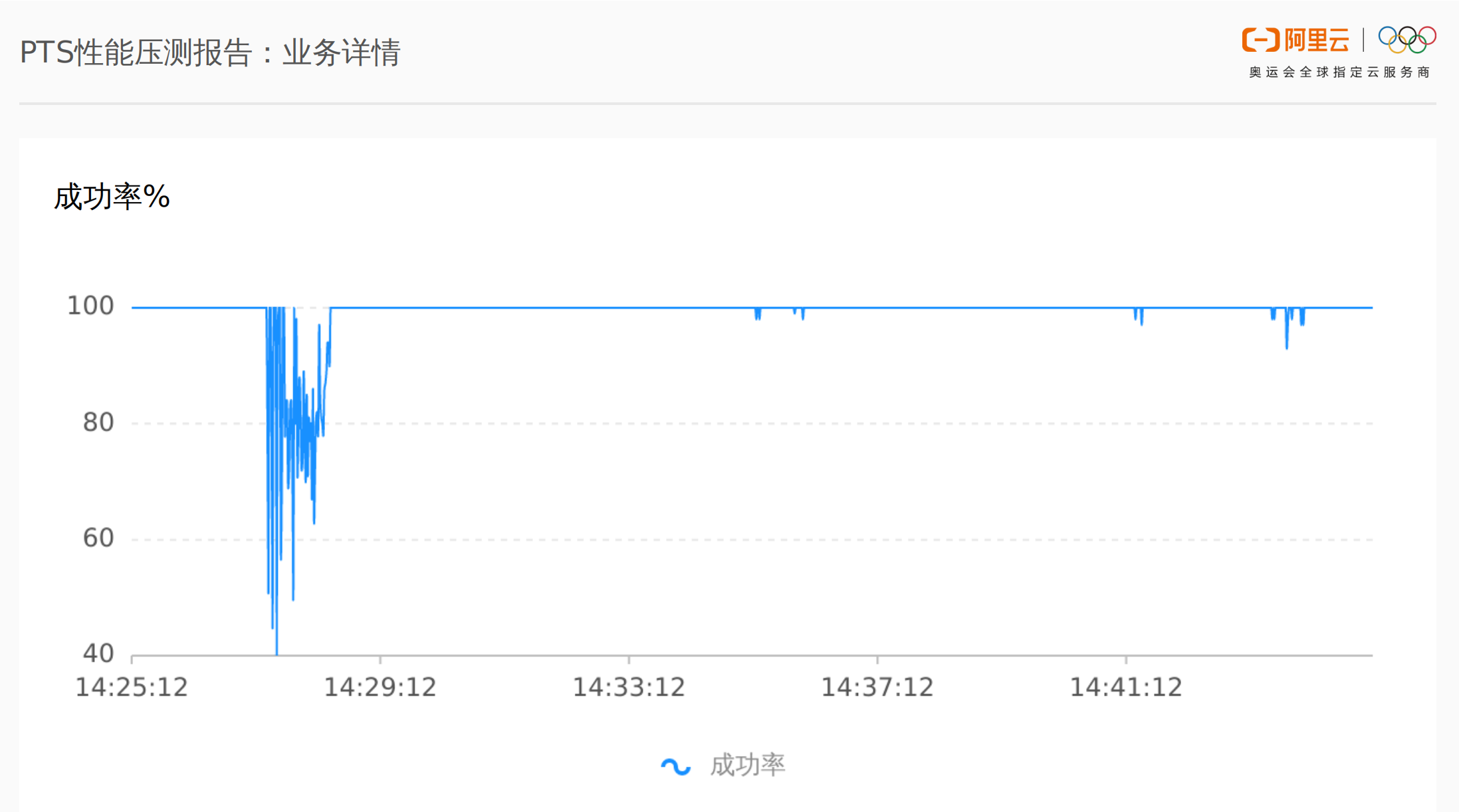
pts压测时候看了一下日志,一开始是的错误报的是连接超时,然后成功率又恢复正常这是为什么呢?我这个是服务端冷启动原因导致的吗?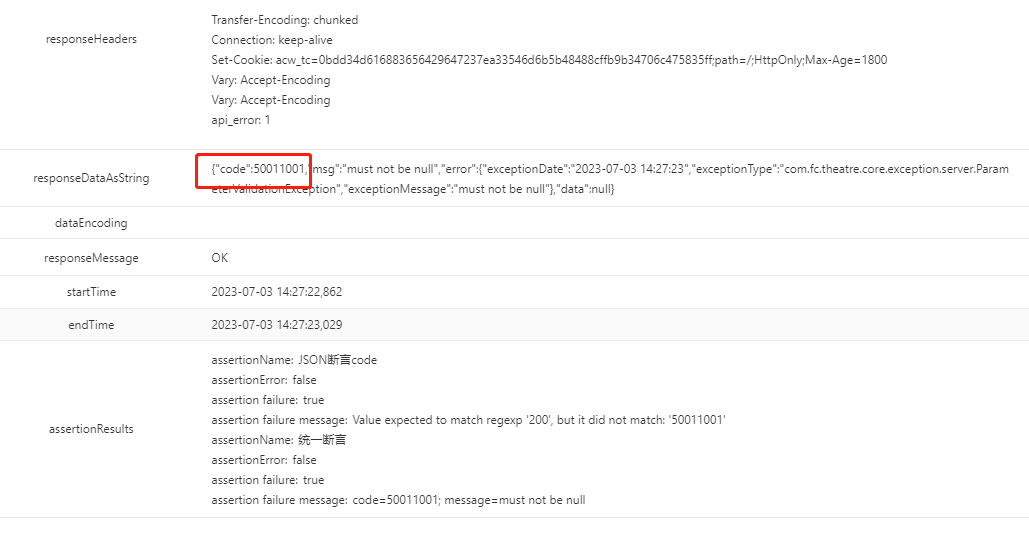
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在PTS压测过程中,出现连接超时的情况可能由多种原因引起,例如网络异常、目标系统响应过慢、测试场景设置不合理等。以下是一些可能导致连接超时的原因:
网络异常:网络连接不稳定或网络带宽不足可能导致连接超时。建议确认网络连接稳定,检查网络带宽是否足够,并尽可能选择网络状况良好的测试节点进行测试。
目标系统响应过慢:如果目标系统响应速度过慢,可能会导致连接超时。建议对目标系统进行性能测试,确认系统响应速度是否满足测试需求。
测试场景设置不合理:测试场景设置不合理可能导致连接超时。例如,请求速率设置过快,或者请求参数不合理,可能会导致目标系统无法及时响应请求。建议针对具体的测试场景进行分析和优化,调整测试策略和参数设置。
当在PTS压测期间遇到连接超时错误报告,并且之后成功率恢复正常的情况,可能是由于服务端冷启动引起的。以下是可能的原因和解释:
服务端冷启动:如果在开始阶段服务端出现了冷启动(即重新启动或初始加载),它可能需要一些时间来完成初始化和准备工作。在这段时间内,服务端可能无法及时响应所有的请求,从而导致连接超时错误。一旦服务端完成冷启动并稳定运行,成功率就会恢复正常。
资源加载延迟:服务端冷启动可能涉及加载和初始化各种资源,如数据库连接、缓存数据、配置文件等。这些加载过程可能需要较长的时间,特别是在首次启动或重启时。在此期间,大量的并发请求可能导致服务端无法及时处理请求,从而导致连接超时错误。
弹性扩展限制:如果服务端使用弹性扩展机制(例如自动伸缩),则在冷启动期间可能会有一段时间,新实例正在创建或启动中。如果PTS压测期间请求发送到还未完全启动的实例上,则可能会遇到连接超时错误。一旦新实例启动并处理请求,成功率将恢复正常。
为了应对这种情况,您可以尝试以下方法:
预热期:在PTS压测开始之前,预留一段时间来进行服务端的预热。这样可以确保服务端在压测期间已经完成了冷启动和初始化过程,从而减少连接超时错误的发生。
弹性扩展优化:如果使用了弹性扩展机制,请确保它能够快速响应并处理新实例的请求。考虑调整自动伸缩规则、扩容策略或使用其他优化方法,以提高冷启动期间的可用性。
压测模式调整:根据具体情况,可以调整压测模式,例如逐渐增加并发用户数、延长测试时间等。这样可以给服务端更多的时间来完成冷启动,并逐步达到稳定状态。
有可能的。这种一开始成功率低,后面成功率正常可能是一开始服务端处理请求的能力扛不住上来就这么大的压力,但是随着压测的进行,缓存什么的都准备好了,就有了快速处理请求的能力。此回答整理自钉群“【4群】PTS用户交流群”
云原生可观测基于Prometheus、Grafana 、OpenTelemetry 等核心产品, 形成指标、链路存储分析、异构数据源集成的数据层, 通过标准PromQL和SQL提供大盘展示、告警与探索能力。

