
问题1:df = o.to_mars_dataframe('dim_sea_member_info',partition='data_source=1&dayno=20991231') 报错,请问Mars ,读取大数据计算MaxCompute表分区怎么弄?文档没看见。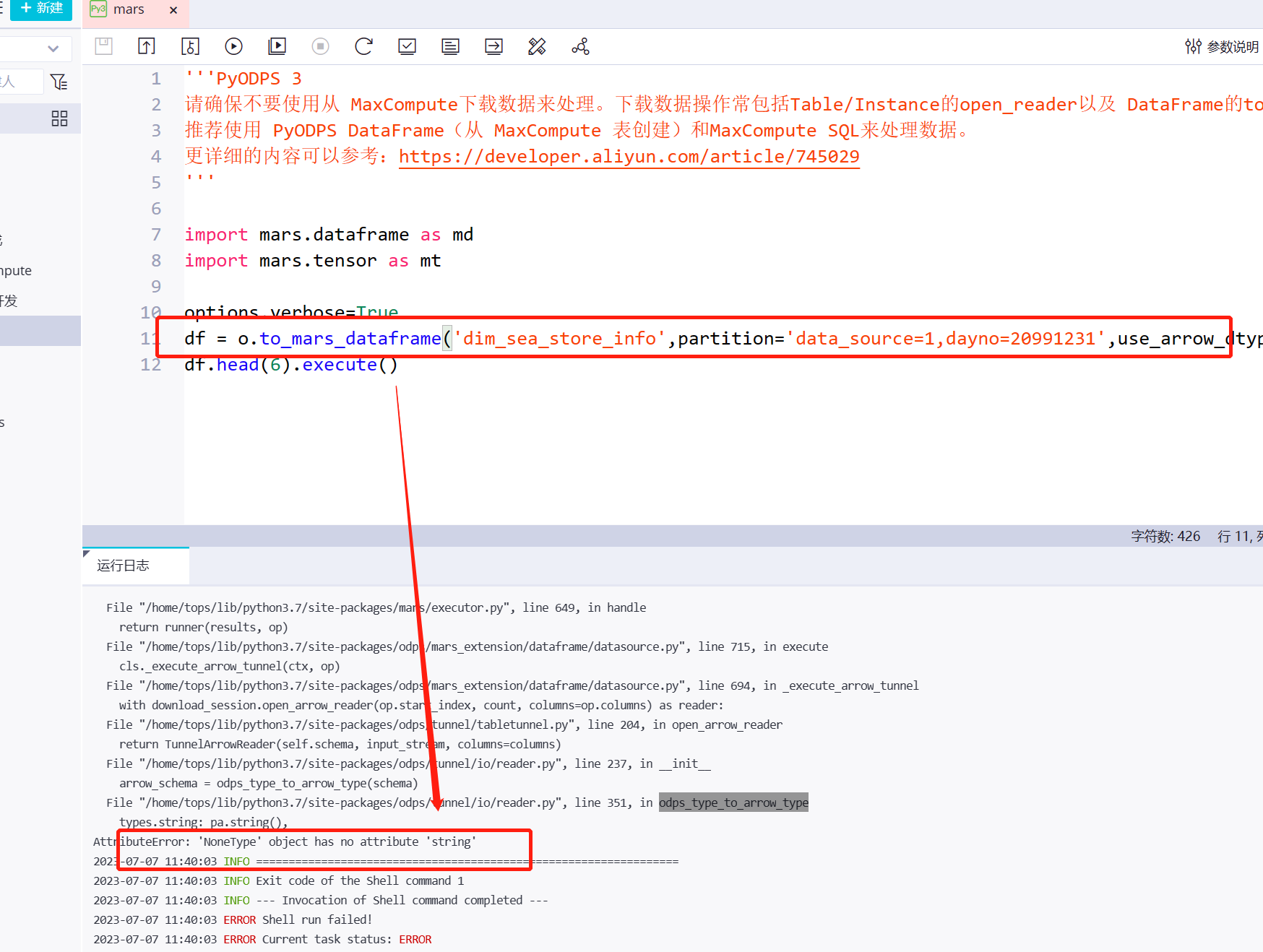
是我用错了吗?问题2: 我们的需求是我们用pyodps,做算法,用到pandas,性能太差,odps dataframe不兼容我们算法,mars兼容原始dataframe,所以想换成Mars看看性能和支持的数据量。
我们的需求是我们用pyodps,做算法,用到pandas,性能太差,odps dataframe不兼容我们算法,mars兼容原始dataframe,所以想换成Mars看看性能和支持的数据量。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Mars中,可以通过to_mars_dataframe方法将MaxCompute表导入到Mars中进行计算。如果要读取MaxCompute表的分区数据,可以在to_mars_dataframe方法中指定分区信息。具体而言,可以使用如下参数来指定分区信息:
partition:指定分区信息,格式为'partition_column1=value1&partition_column2=value2'。例如,假设您要读取MaxCompute表dim_sea_member_info中data_source=1和dayno=20991231的分区数据,可以使用如下代码:
Copy
df = o.to_mars_dataframe('dim_sea_member_info', partition='data_source=1&dayno=20991231')
partition_spec:指定分区信息,格式为字典。例如,使用如下代码指定data_source=1和dayno=20991231的分区数据:
scheme
Copy
partition_spec = {'data_source': '1', 'dayno': '20991231'}
df = o.to_mars_dataframe('dim_sea_member_info', partition_spec=partition_spec)
需要注意的是,读取MaxCompute表的分区数据时,需要先在MaxCompute中创建相应的表和分区,并在Mars中配置MaxCompute的访问信息(如access_id、access_key、project等)。另外,如果您的分区数据比较大,建议使用Mars的分布式计算能力来加速数据读取和处理。
在使用Mars库读取大数据计算MaxCompute表分区时,您可以按照以下步骤进行操作:
安装Mars库:首先确保已经安装了Mars库,可以使用pip install mars命令进行安装。
导入所需的模块:在Python脚本中导入Mars相关的模块,例如:
from mars import DataFrame
import mars.dataframe as md
import mars.oscar as mo
创建Mars连接:通过创建Mars连接对象并指定MaxCompute集群的地址和访问凭证来建立连接。例如:
session = mo.new_session(address='maxcompute://project_name.endpoint', access_id='your_access_id', access_key='your_access_key')
读取分区数据:使用to_mars_dataframe方法从MaxCompute表的特定分区读取数据,并将其转换为Mars的DataFrame对象。例如:
df = md.read_sql_table('dim_sea_member_info', uri='maxcompute://project_name.endpoint', partition='data_source=1&dayno=20991231', session=session)
在上述示例中,uri参数用于指定MaxCompute连接的地址,partition参数用于指定要读取的分区条件。请确保替换project_name.endpoint为实际的MaxCompute项目名称和地址,同时根据需要调整分区条件。
需要注意的是,Mars库对于MaxCompute的分区读取支持仍处于早期阶段,因此在文档中可能无法找到详细的说明。以上提供的示例代码是一种常见的方式,但具体实现可能会根据您的环境和需求有所不同。
针对问题1的回答:看报错是不支持用,看文档描述,mars我理解在mars环境中后,直接使用PyODPS的用法就行。这样,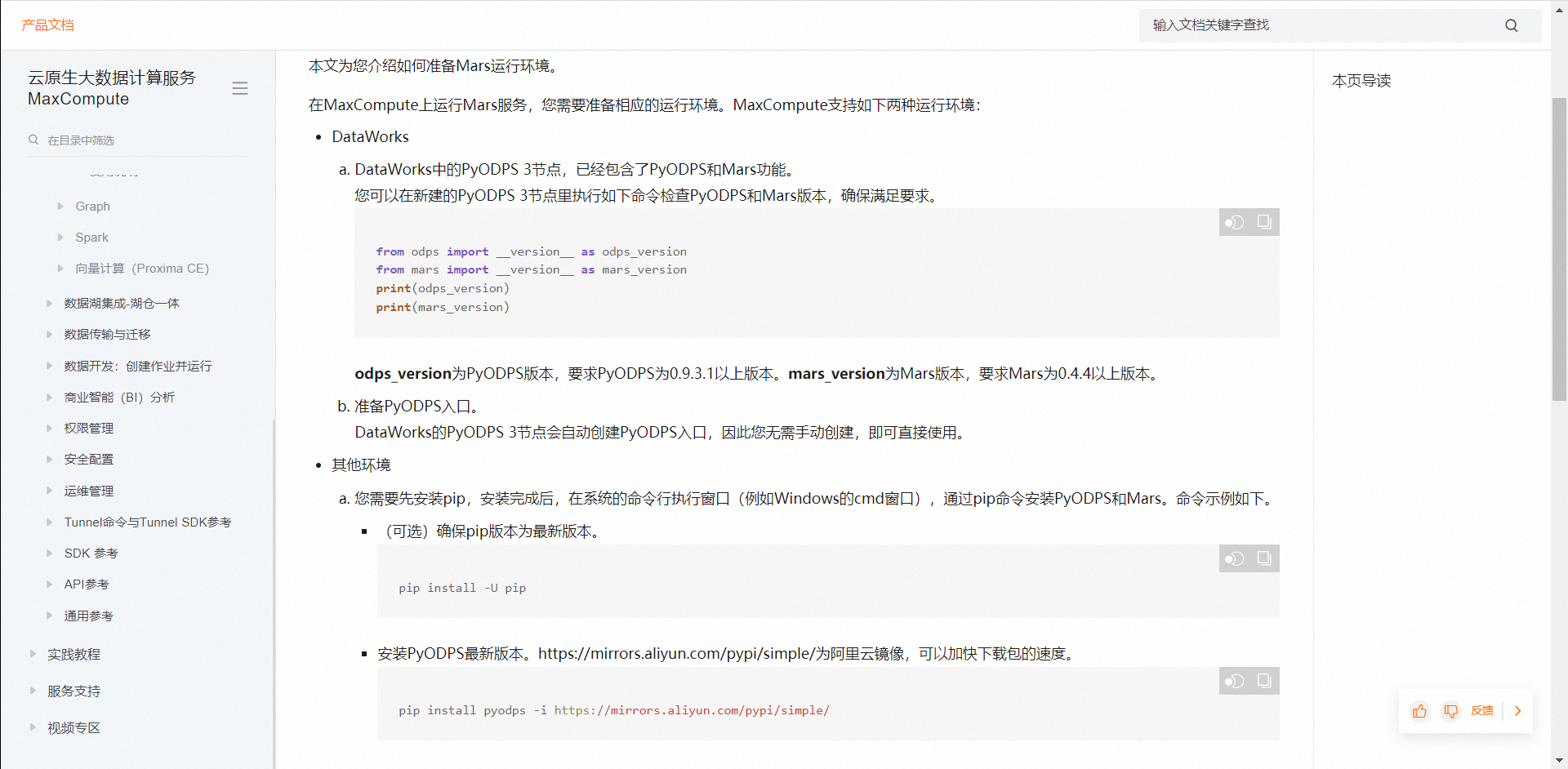
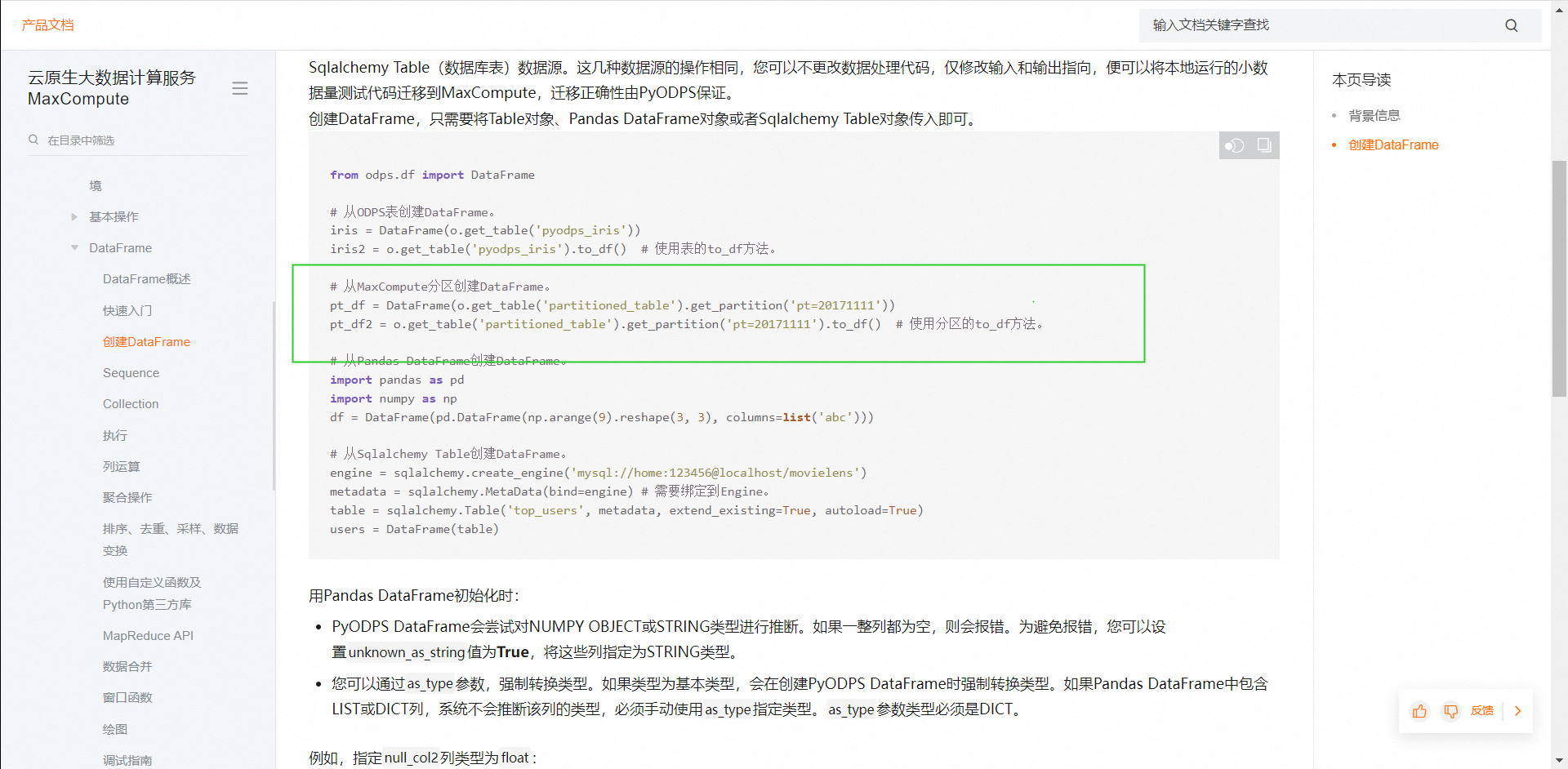 https://help.aliyun.com/zh/maxcompute/user-guide/create-a-dataframe-object?spm=a2c4g.11186623.0.0
https://help.aliyun.com/zh/maxcompute/user-guide/create-a-dataframe-object?spm=a2c4g.11186623.0.0
针对问题2的回答:我找了找关于mars读MaxCompute分区表没有文档示例
https://pyodps.readthedocs.io/zh_CN/latest/mars-user-guide.html
这边和研发确认了一下不太建议用Mars,如果有一些一定需要代码处理的数据,可以看看用spark。此回答整理自钉群“MaxCompute开发者社区2群”
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


